OSCE를 위한 자원 효율적이고 신뢰할 수 있는 합격선 설정 방법: 표준화 환자를 단독 평가자로 하는 경계선 회귀 방법(Med Teach, 2022)
A resource efficient and reliable standard setting method for OSCEs: Borderline regression method using standardized patients as sole raters in clinical case encounters with medical students
Felise B. Milana and Joseph H. Grochowalskib

소개
Introduction
의학교육이 학부(UME), 대학원(GME) 및 평생의학교육(CME) 프로그램 전반에 걸쳐 역량 기반 평가를 강조하는 방향으로 점점 더 이동함에 따라, 의학교육자가 이러한 평가와 그 결과의 질과 엄격성을 보장해야 할 필요성이 증가하고 있습니다(Pell 외. 2010). 마일스톤, EPA(위탁 가능한 전문 활동) 또는 역량에 관계없이 교육기관은 평가를 기반으로 내린 결정이 신뢰할 수 있고 방어할 수 있음을 모든 이해관계자에게 보장하는 데 필요한 지식과 기술을 습득해야 할 필요가 있습니다(Lockyer 외. 2017). 성취한 역량에 기반한 교육 시스템으로 전환해야 하는 상황에서 합격선 설정(역량을 입증하는 점수 결정으로 진급자 및/또는 재교육 대상자를 결정)이 더욱 중요해졌습니다. 그러나 교육 예산이 점점 더 타이트해지고 임상의 교수진의 임상 생산성 요구가 증가함에 따라 더 적은 리소스로 이 작업을 수행해야 하는 과제에 직면해 있습니다(Price 외. 2018).
As medical education moves increasingly to emphasize competency-based assessments throughout the spectrum of undergraduate (UME), graduate (GME) and continuing medical education (CME) programs, there is an increased need for medical educators to ensure the quality and rigor of these assessments and their outcomes (Pell et al. 2010). Whether we are working with milestones, EPAs (Entrustable professional activities) or competencies, there is a need for institutions to acquire the knowledge and skills necessary to assure all stakeholders that the decisions made based on their assessments are reliable and defensible (Lockyer et al. 2017). With the imperative to move to an educational system based on competencies achieved, standard setting (determining the score that demonstrates competency to decide who moves forward and/or who must be remediated) becomes ever more crucial. However, as education budgets get tighter and as our clinician faculty have increasing clinical productivity demands, we are faced with the challenge of accomplishing this task with fewer resources (Price et al. 2018).
합격선 설정 결정은 복잡하며 교육기관의 문화, 정치적 분위기, 커리큘럼 프로그램, 리소스 등 다양한 변수에 따라 달라집니다(Downing and Yudkowsky 2009). 지난 20년 동안 성과 기반 평가를 위한 표준 설정 전략에 대한 지식이 엄청나게 성장했습니다(De Champlain 2018). 표준 설정 방법에는 일반적으로 두 가지 유형이 있습니다.
- (1) 교수자가 예정된 시험과 무관하게 시험 자료를 검토할 수 있는 시험 자료 검토 방법(예: 앙고프 및 에벨 방법)과
- (2) 수험자의 수행을 검토하는 방법(예: 경계선, 경계선 회귀 및 대조군 방법)
영국과 캐나다에서는 보건의료 및 의학교육 시스템의 구조상 이를 허용하는 교수진이 평가자로 사용되는 경우가 많기 때문에 고부담 OSCE(관찰형 표준화 임상시험)에 사용되는 수험자 중심의 표준 설정 방법에 대한 많은 연구가 수행되었습니다(Price et al. 2018). 교수진은 각 스테이션에서 학습자를 관찰하고 체크리스트와 전체 평가 점수를 작성한 다음 경계선 방법을 사용하여 학습자의 점수와 합격 기준을 모두 결정하는 데 사용합니다. 교수 평가자를 사용하는 교육 환경에서 경계선 그룹 및 경계선 회귀 방법은 신뢰할 수 있고 실용적인 표준 설정 방법인 것으로 나타났습니다(Kilminster and Roberts 2004; Boursicot 외. 2006; Wood 외. 2006; Boursicot 외. 2007; Wilkinson 외. 2008; Hejri 외. 2013; Yousuf 외. 2015; Malau-Aduli 외. 2017).
Standard setting decisions are complex and based on a multitude of variables that are specific to an institution’s culture, political climate, curricular program, and resources (Downing and Yudkowsky 2009). The past twenty years have seen an enormous growth of knowledge in standard setting strategies for performance-based assessments (De Champlain 2018). Standard setting methods are typically of two types;
- (1) Those involving review of examination materials (e.g. Angoff and Ebel methods) where faculty can review these materials independent of scheduled testing, and
- (2) Those involving review of examinee performance (e.g. Borderline, borderline regression and contrasting groups methods) (Kilminster and Roberts 2004; Pell et al. 2010).
Much of the work on the examinee-focused standard setting methods used for high stakes OSCEs (observed standardized clinical exam) has been done in the UK and Canada where faculty are used as raters, as the structure of their health care and medical education systems allow for this (Price et al. 2018). These faculty observe the learners at each station and complete checklists and global rating scores, which are then used to determine both the learners’ scores as well as the passing standard using the borderline method. In educational settings using faculty raters, the borderline group and borderline regression methods have been shown to be reliable and practical standard setting methods (Kilminster and Roberts 2004; Boursicot et al. 2006; Wood et al. 2006; Boursicot et al. 2007; Wilkinson et al. 2008; Hejri et al. 2013; Yousuf et al. 2015; Malau-Aduli et al. 2017).
현재 교수진이 평가에 참여하지 않는 OSCE에 사용되는 가장 신뢰할 수 있는 표준 설정 방법은 앙고프 방법과 그 파생 방법입니다(Kilminster and Roberts 2004). 그러나 경계선 방법과 달리 앙고프 표준 설정 방법은 합격 기준을 설정하는 소규모 전문가 그룹의 판단에 상당한 시간을 투자해야 합니다. 이 방법은 더 많은 비용으로 경계선 방법보다 덜 신뢰할 수 있는 표준을 생성하는 것으로 나타났습니다(도피니 외. 1997). 이러한 여러 가지 요인으로 인해 저희 학교를 포함한 미국의 많은 학교에서는 표준 설정에 규범 기반 기준을 사용해 왔습니다. 물론 이 방법은 역량 기반 평가를 실천하고자 하는 우리의 바람과는 상반됩니다.
Currently, the most reliable standard setting method used for OSCEs that does not involve the faculty being present for the assessment is the Angoff method and its derivations (Kilminster and Roberts 2004). However, in contrast to the borderline methods, the Angoff standard setting method requires significant investment of time from a small expert group of faculty whose judgments set the passing standards. The method has been shown to produce less reliable standards than the borderline methods at a greater cost (Dauphinee et al. 1997). Due to these many factors, many schools in the US, including ours, have used a norm-based criterion for standard setting. This method, of course, runs counter to our desire to practice competency-based assessment.
미국에서는 미국국립의학시험위원회(NBME)와 외국 의대 졸업생 교육위원회(ECFMG)는 물론 많은 의과대학에서 고도로 훈련된 표준화 환자(SP)를 사용하여 환자를 묘사하고 학생의 점수를 생성하는 체크리스트 또는 척도를 작성합니다(Zanten 외. 2007). 많은 교육기관에서 SP는 임상 술기에 대한 교육과 피드백을 제공하는 교육자로서도 중요한 역할을 합니다(Howley 2013; May et al. 2009). 표준화된 환자에 의한 학생의 임상 술기 평가가 신뢰할 수 있고 타당하다는 것을 보여주는 많은 문헌이 있습니다. SP 평가자가 교수 평가자만큼 신뢰할 수 있다는 일부 문헌도 있습니다: Han 등(2006)은 SP 평가자가 체크리스트 채점에서 의사 평가자와 동일한 신뢰도를 보였으며, 4학년 의대생 임상 술기 OSCE에서 전체 평가에서 의사보다 더 높은 신뢰도를 보였다고 밝혔습니다.
In the U.S., both the National Board of Medical Examiners (NBME) and Educational Commission for Foreign Medical Graduates (ECFMG), as well as many medical schools, use highly trained standardized patients (SPs) to both portray the patients as well as complete the checklists or scales that create the students’ scores (Zanten et al. 2007). In many institutions SPs also play a key role as educators providing instruction and feedback on clinical skills (Howley 2013; May et al. 2009). There is a significant body of literature showing that the rating of students’ clinical skills by standardized patients is both reliable and valid (Boulet et al. 2002; Humphrey-Murto and Macfadyen 2002; Kilminster and Roberts 2004; Whelan et al. 2005; Han et al. 2006; McKinley and Norcini 2014). There is also some literature showing that SP raters may even be as reliable as faculty raters: Han et al. (2006) demonstrated SP raters had the same reliability as physician raters on checklist scoring and higher reliability than the physicians on global rating in a 4th year medical student clinical skills OSCE.
미국은 영국이나 캐나다와 같은 시스템보다 OSCE에 참석할 교수진의 시간이 더 제한되어 있으므로, 이 연구의 목표는 경계선 표준 설정 방법을 사용하는 데 필요한 글로벌 평가 점수를 작성하는 데 SP를 안정적으로 사용할 수 있는지 조사하는 것이었습니다. SP가 신뢰할 수 있는 점수를 제공할 수 있다면, 임상시험 OSCE에 교수진이 참석할 필요가 없어질 것입니다.
Faculty time to be present for OSCEs is more limited in the USA than in systems such as the UK and Canada, so the goal of this study was to investigate whether SPs could reliably be used to complete the global rating score needed to use the borderline method of standard setting. If SPs could provide reliable scores, it would obviate the need for faculty to be present for the clinical encounter OSCE.
(의도된 목적에 따라) 신뢰할 수 있는 점수는 점수의 타당성을 뒷받침하는 데 필요한(충분하지는 않지만) 증거이며, 이는 지속적인 조사 과정입니다(Kane 2013). 부정확한 점수는 일관된 내용의 표현, 수험자 순위, 합격/불합격 결정, 예측 또는 기타 점수 활용을 뒷받침할 수 없습니다. 이 논문의 핵심 목표는 OSCE 설계 및 채점 결정을 기반으로 점수의 reliability과 dependability의 토대를 구축하는 것이었습니다. 물론 이 측정 방법을 개발하는 과정에서 내용 및 구성 타당도를 확립하기 위한 일반적인 접근 방식도 통합했으며, 이에 대해서는 방법에서 설명합니다.
Reliable scores (for an intended purpose) is a necessary (but not sufficient) piece of evidence to have in support of score validity, which is an ongoing investigative process (Kane 2013). Imprecise scores cannot support representation of cohesive content, examinee ranking, pass/fail decisions, predictions, or other score uses in its absence. Our central goal in this paper was to establish the foundation of score reliability and dependability based on our OSCE design and scoring decisions. Of course, in our development of this method of measure, we also incorporated common approaches to establishing content and construct validity, which we describe in the methods.
방법
Methods
참가자
Participants
참가자는 우리 기관의 3학년 의대생 182명 전원을 포함했습니다. OSCE는 다양한 임상 시나리오를 제시하는 8개 스테이션으로 구성되었으며 필수 평가이므로 매년 100% 참여가 이루어졌습니다.
Participants included all 182 third-year medical students at our institution. The OSCE had 8 stations presenting a variety of clinical scenarios and is a required assessment, so 100% participation was achieved yearly.
OSCE
The OSCE
학생들은 환자의 나이, 성별, 진료 장소(예: 응급실, 클리닉, 병동)가 주어지고 한 케이스당 15분 동안 3케이스에 대해서만 병력 청취를 하거나 5케이스에 대해 병력 및 신체검사를 하도록 지시받았습니다. 어떤 케이스에서도 절차적 술기를 평가하지 않았습니다.
- 6개의 스테이션에서는 환자들이 해결해야 할 다양한 주요 불만 사항을 제시했습니다(5명은 직접 방문, 1명은 전화로). 이 스테이션은 집중적인 병력 청취, 집중적인 신체 진찰, 임상적으로 적절한 감별 진단에 기반한 적절한 관리 계획 수립 및 환자에게 해당 계획을 전달하는 학생의 능력을 평가하도록 설계되었습니다.
- 다른 두 스테이션에서는 환자 상담이 주요 과제였습니다.
케이스는 핵심 임상 로테이션을 막 마친 학생에게 적합한 난이도로 설계되었습니다. 구성 및 내용 타당성을 확립하기 위해 전문가들은 OSCE 사례를 검토하여 의학, 정신과, 외과, 노인병, 신경과, 소아과 등 다양한 분야의 입원 및 외래 임상 문제를 다양하게 제공했는지 확인했습니다. 임상 술기 측정에 대한 포괄적이고 적절한 범위를 보장하기 위해 의사 교육자로 구성된 다학제적 위원회에서 사례를 작성했습니다. 임상 전문가들이 콘텐츠의 타당성과 임상적 정확성을 위해 사례를 검토했습니다.
Students were given the patient’s age, gender and encounter location (i.e. ER, clinic, hospital ward) and instructed to do a history for only three cases or history and physical exam for five cases in the 15 minutes allotted per case. No procedural skills were assessed in any of the cases.
- In six of the stations, patients presented (five in person, one by telephone) with chief complaints of varying acuity to be addressed. These stations were designed to assess the students’ ability to take a focused history, perform a focused physical, develop an appropriate management plan based on clinically appropriate differential diagnoses and communicate that plan to the patient.
- In the other two stations, the primary task was patient counseling.
The cases were designed to have a difficulty level appropriate for a student who had just completed their core clinical rotations. To establish construct and content validity, experts reviewed the OSCE cases to ensure they offered a diverse array of both inpatient and outpatient clinical problems from varied disciplines including medicine, psychiatry, surgery, geriatrics, neurology and pediatrics. Cases were written by a multidisciplinary committee of physician educators to ensure comprehensive and adequate coverage of clinical skills measurement. Clinical specialists reviewed cases for content validity and clinical accuracy.
SP 교육
SP training
표준화된 환자(SP)가 술기 체크리스트(병력, 신체 검사 및 의사소통 기술)를 사용하여 (학생들이 진료 후 노트를 작성하는 10분 동안) 학생들의 수행을 평가했습니다. SP 그룹은 표준화 환자로 훈련받았으며 이 역할에 4~25년의 경력을 가진 전문 배우들이었습니다. 이들은 30년 동안 이 일을 해온 의사와 SP 트레이너가 각 사례에 맞게 모집하고 훈련했습니다. SP는 OSCE와 관련된 다분야 의사 그룹이 개발한 허용 가능한 신체 검사 기법 매뉴얼을 기반으로 신체 검사 기법 표준에 대해 의사로부터 광범위하게 교육을 받았습니다. 이들은 SP 트레이너로부터 표준화된 방식으로 사례를 묘사하고 학생들이 질문한 병력 항목을 안정적으로 보고할 수 있도록 사례에 대한 교육을 받았습니다. 글로벌 평가 항목(그림 1)에서는 SP에게 훈련받고 경험이 풍부한 SP로서의 관점과 해당 학습자의 환자가 되어본 느낌에 대해 글로벌 평가를 하도록 요구했지만, 교수 평가자에게 요청하는 것처럼 임상적 판단을 하도록 요구하지는 않았습니다.
The students’ performances were evaluated by standardized patients (SPs) using skills checklists (history, physical exam and communication skills), during the 10 minutes that the students had to write their post-encounter note. The group of SPs were professional actors who had been trained as standardized patients and had from 4 to 25 years of experience in this role. They were recruited and trained for each case by a physician and SP trainer who had been doing this work for 30 years. The SPs were extensively trained by the physician on physical exam technique standards based on a manual of acceptable physical exam maneuvers that had been developed by a multi-disciplinary group of physicians involved with the OSCE. They were trained on the cases by the SP trainer to both portray the case in a standardized fashion as well as to reliably report which history items had been asked by the students. The global rating item (Figure 1) required the SPs to make a global rating from their perspective as a trained and experienced SP as well as what it was like to be this learner’s patient, but did not ask them to make a clinical judgment as would be asked of a faculty rater.

저자 중 한 명은 SP 트레이너와 협력하여 약 60분 동안 의사소통 기술 체크리스트 및 글로벌 평가 항목 사용에 대한 참조 프레임 평가자 교육(Holmboe and Hawkins 2008) 세션을 진행했습니다. 참조 프레임 훈련은 수행 차원 훈련의 연장선이며 평가자 간 신뢰도를 높이는 데 매우 효과적인 것으로 나타났습니다(Roch 외. 2012). 저희 교육에서는 SP에게 다양한 역량 수준에서 수행한 이전 학생들의 비디오 클립을 시청하게 하고, 평가할 동일한 사례를 묘사한 표준화 환자를 인터뷰한 후, SP가 의사소통 기술 체크리스트와 글로벌 평가 항목의 일부를 완료하도록 했습니다. 각 영상이 끝난 후 SP는 주어진 항목에 대한 자신의 등급을 보고하기 위해 손을 들어 응답했습니다. 의견이 일치하지 않는 경우 평가자는 자신이 선택한 이유를 설명했습니다. 평가자에게 행동 앵커를 참조하고, 행동을 적절한 차원으로 분류하고, 각 행동의 효과를 탐색하고, 행동이 역량 표준을 충족할 때 강화했습니다. 각 항목은 합의에 도달할 때까지 논의되었습니다.
One of the authors worked with the SP trainer to administer a frame-of-reference rater training (Holmboe and Hawkins 2008) session on the use of the communication skills checklist and global rating item, lasting about 60 minutes. Frame of reference training is an extension of performance dimension training and has been shown to be very effective in increasing inter-rater reliability (Roch et al. 2012). In our training we had the SPs view video clips of previous students performing at various competency levels and interviewing the standardized patients portraying the same cases they would be rating, the SPs completed portions of the communication skills checklist and global rating item. After each clip, the SPs responded to a show of hands to report their rating on a given item. When there was disagreement, raters explained their reasons for their choices. We referred raters to the behavioral anchors, categorized behaviors into appropriate dimensions, explored the effectiveness of each behavior and reinforced when behaviors met competency standards. Each item was discussed until consensus was reached.
교수진 교육
Faculty training
교수진은 검토자로 프로그램에 참여하면 2시간의 교육을 받습니다. 여기에는 각 사례에 대한 수행 기준을 제공하는 병력 및 신체 검사 체크리스트와 의사소통 기술 체크리스트에 대한 행동 앵커에 대한 광범위한 논의가 포함됩니다. 또한 교수진이 모여 점수, 비디오 및 SP 코멘트를 논의하여 학생이 합격에 필요한 역량 기준을 충족하는지 여부를 결정하는 추가 회의가 있습니다.
Faculty receive a 2-hour training when they enter the program as reviewers. This includes extensive discussion of the history and physical exam checklists and behavioral anchors for communication skills checklist which provide a performance standard for each case. In addition, there are additional meetings where faculty meet to discuss the scores, videos and SP comments to decide whether students meet the competency standard for passing.
도구: 역사, 신체 검사 및 커뮤니케이션 기술 체크리스트
Instruments: History, physical exam, and communication skills checklists
OSCE의 각 케이스에는 약 14개 항목으로 구성된 케이스별 병력 체크리스트가 있습니다. 신체검사가 포함된 사례의 경우 약 8개의 항목으로 구성된 케이스별 신체검사 체크리스트가 있었습니다(스테이션 사례 요약 및 체크리스트 항목 수는 표 1 참조). 이 두 가지 사례별 체크리스트의 항목은 여러 전문 분야로 구성된 임상 교수진 그룹이 해당 사례의 감별 진단을 결정하는 데 필수적인 항목으로 선정했습니다.
Each case in the OSCE had a case-specific history checklist with approximately 14 items. For cases that included a physical exam, there was a case-specific physical exam checklist with approximately eight items (Table 1 for a breakdown of station case summaries and checklist item counts). The items on both of these case-specific checklists were chosen by a multi-specialty group of clinical faculty as items essential to the determination of the differential diagnoses for that case.

그런 다음 행동에 기반한 의사소통 기술 체크리스트를 모든 사례에 사용했습니다. 이 체크리스트는 2004년 3년차 OSCE를 위해 다른 기관과 협력하여 처음 개발되었으며, 2006년에 의료 커뮤니케이션 아카데미에서 개발하여 우리 기관에서 의사소통 기술을 교육하는 데 사용하는 3기능 모델 및 파트너십, 공감, 사과, 존중, 정당화 및 지원(PEARLS) 라포 형성 모델(Cole and Bird 2013)과 보다 밀접하게 일치하도록 개정되었습니다. 이 체크리스트는 교수진과 표준화 환자의 피드백을 바탕으로 2010년에 현재 버전(부록 1)으로 한 번 더 개정되었습니다. 체크리스트는 정보 수집(4개 항목), 촉진(2개 항목), 영어 능력(1개 항목), 관계 형성(3개 항목), 환자 교육(2개 항목)의 기술 영역으로 구성되어 있습니다. 체크리스트는 일반화 가능성 이론을 사용하여 분석되었으며, 이번 3년차 OSCE에 사용하기에 Φ̂=0.79의 점수 신뢰도가 있는 것으로 나타났습니다.
The behaviorally anchored communication skills checklist was then used across all cases. The checklist was first developed in 2004 in collaboration with another institution for the 3rd year OSCE and was revised in 2006 to more closely align with the 3-function model and Partnership, Empathy, Apology, Respect, Legitimation, and Support (PEARLS) model of rapport building (Cole and Bird 2013), developed by the Academy of Communication in Healthcare and used for teaching communication skills at our institution. It was revised once more to its current version (Supplementary Appendix 1) in 2010 based on feedback from faculty and standardized patients. The checklist is organized into the following skill areas: information gathering (four items), facilitation (two items), English Language proficiency (one item), relationship building (three items), and patient education (two items). The checklist was analyzed using generalizability theory and found to produce score reliability of Φ̂=0.79 for use with this third year OSCE.
글로벌 평가 항목
The global rating item
위에서 설명한 체크리스트 외에도 학생의 정량 점수에 포함되지 않고 표준 설정에만 사용되는 5점 만점의 글로벌 평가 항목이 하나 있습니다(그림 1). 영국과 경계선 회귀에 관한 많은 문헌에서 사용된 글로벌 평가 항목의 저자(Boursicot 외. 2007, Homer and Pell 2009)는 저자와 이 항목을 공유했으며, SP의 글로벌 평가에 대해 수행한 일부 작업을 바탕으로 SP와 함께 사용할 수 있도록 개정하는 데 조언을 제공했습니다. SP 트레이너와 소수의 숙련된 SP로부터 SP로서의 관점에서 판단할 수 있다고 생각하는 항목에 대한 의견을 받았습니다. 이 작성자는 원래의 글로벌 평가 항목에서 5가지 핵심 영역을 파악하고 환자의 관점에 맞게 문구를 수정했습니다.
In addition to the above checklists described, there is a single five-point global rating item (Figure 1) that does not count towards the students’ quantitative score but is used solely for standard setting. The authors of the global rating item used in the UK and in much of the literature on borderline regression (Boursicot et al. 2007; Homer and Pell 2009) shared the item with the authors and advised us in the revision of it for use with the SPs based on some work they had done with global rating from SPs. We received input from the SP trainer and a small group of experienced SPs as to what they felt they could make a judgment on from their perspective as an SP. This author identified five key domains in the original global rating item and revised the wording to match the patient perspective.
분석
Analyses
먼저 체크리스트와 경계선 방식을 사용할 필요가 있는지, 아니면 글로벌 평가 점수가 합격과 불합격을 결정할 수 있을 만큼 정확하고 신뢰할 수 있는지를 고려했습니다. 우리는 G 이론을 사용하여 글로벌 점수의 컷 점수 신뢰도(Brennan and Kane 1977)를 계산하여 컷 결정을 내릴 때 관찰된 점수의 정확성을 평가했습니다.
We first considered whether it was necessary to use the checklist and borderline method at all, or whether the global rating scores were precise and reliable enough to make pass or fail decisions. We calculated the cut score dependability (Brennan and Kane 1977) of the global scores using G-theory, assessing the accuracy of observed scores for making cut decisions.

저희는 Homer와 Pell(2009)의 제안(보충 부록 2, A4)에 따라 OSCE 점수의 품질과 경계선 회귀 결과를 평가했으며, 글로벌 점수와 스테이션 점수에 대해 각각 무작위 효과 분산분석(random-effects ANOVA)을 실시했습니다. 이를 통해 스테이션/평가자 점수가 전반적으로 얼마나 다른지, 스테이션에서 개인별 점수가 얼마나 다른지, 학습자 능력과 사례/평가자에 의해 설명되지 않는 분산의 비율(글로벌 평가 일관성 포함)을 설명했습니다(보충 부록 2, A5).
We evaluated the quality of OSCE scores and borderline regression results based on suggestions from Homer and Pell (2009) (Supplementary Appendix 2, A4) and we conducted random-effects ANOVAs for the global scores and station scores, separately. This explained the degree that station/rater scores differed overall, how much person scores at stations differed, and the proportion of variance unexplained by learner ability and cases/raters, including global rating consistency (Supplementary Appendix 2, A5).
마지막으로, 기존 방법의 대안으로 경계선 회귀법의 타당성을 평가하기 위해 경계선 회귀법을 사용하여 결정된 전체 OSCE 점수에 대한 합격률을 기존의 규범 기반 표준 설정 방법(합격 점수가 평균보다 2 표준편차 이상 낮을 경우 합격)과 비교했습니다.
Finally, we went on to evaluate the feasibility of the borderline regression method as an alternative to our former method, and we compared the passing rate for the overall OSCE score determined by this new method, using borderline regression, to our previous norm-based standard setting method (in which passing score is >2 standard deviations below the mean).
합격 기준을 충족하지 못한 지원자의 OSCE 결과를 면밀히 검토하여 점수에 불만족스러운 성과가 반영되었는지 확인했습니다. 숙련된 교수진은 비디오, 체크리스트 점수, SP 의견 및 학생 메모를 검토하여 불합격 점수가 실제로 표준 이하의 성과를 반영하는지, 불합격 결정이 타당하지 않거나 부정확한 합격 점수로 인한 것이 아닌지 확인했습니다.
The OSCE results for persons that did not meet passing standards were carefully reviewed to ensure that their scores reflected unsatisfactory performance. Trained faculty reviewed videos, checklist scores, SP comments and student notes to ensure that sub-passing scores truly reflected substandard performance, and that a fail decision was not an artifact of an invalid or imprecise passing score.
결과
Results
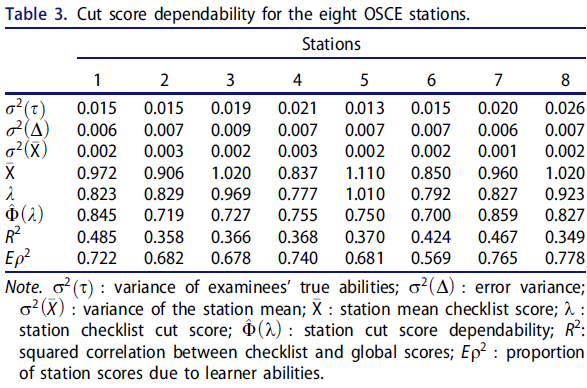
먼저 SP에 의한 평가의 안정성과 신뢰성을 평가했습니다. 학생들의 체크리스트 총점 평균은 0.96점(SD = 0.053점)이었으며, 글로벌 평가 점수는 평균 3.25점(SD = 0.44점)이었습니다. 글로벌 점수의 신뢰도는 0.44로, 그 자체만으로는 중요한 의사 결정 기준으로 신뢰하기에는 너무 낮았습니다. 체크리스트는 한 명의 평가자만 채점했기 때문에 평가자 효과와 스테이션 효과가 혼동되어 평가자 신뢰도를 직접 추정할 수 없었습니다. 그러나 체크리스트와 같은 사례 세부 사항이 아닌 보다 일반적인 평가이므로 글로벌 평가에 대한 평가자 신뢰도를 평가할 수 있었습니다. SP의 글로벌 등급(스테이션 난이도와 혼동)의 클래스 내 상관관계로서의 신뢰도는 ICC = 0.09/(0.09 + 0.81/8) = 0.47(이 값의 출처는 표 2 참조)로, '괜찮은' 일관성을 보였습니다(Cicchetti 1994). 글로벌 평가 점수가 중요한 결정을 내리기에는 충분히 정확하지 않고 스테이션에 중첩된 평가자의 일관성이 공정한 수준이라는 점을 감안하여 경계선 회귀법에서 함께 사용된 글로벌 및 스테이션 점수를 기준으로 결정의 품질을 평가했습니다.
We first assessed the stability and reliability of ratings by SPs. Students had an average total score on the checklists of 0.96 (SD = 0.053), and they had average global rating scores of 3.25 (SD = 0.44). The dependability of the global scores was 0.44, which was too low to be reliably used as a high-stakes decision point by itself. The checklists were only scored by one rater, and so rater effects and station effects were confounded, and rater reliability could not be directly estimated. However, rater reliability could be assessed for the global rating, as this was a more general rating and not specific to case details like the checklists. The reliability as intraclass correlations (Shrout and Fleiss 1979) of the SPs global ratings (confounded with station difficulty) was ICC = 0.09/(0.09 + 0.81/8) = 0.47 (Table 2 for the source of these values), which is ‘fair’ consistency (Cicchetti 1994). Given that the global rating score was not precise enough for high-stakes decisions and the raters nested in stations had only fair consistency of consistency, we assessed the quality of decisions based on global and station scores as used together in the borderline regression method.



경계선 회귀 방법을 사용한 합격 점수는 시범 도입 및 사용 후 7년간 일관되게 높았지만 그 정도는 다양했습니다(표 4). 전체 합격 점수는 0.6~4.0% 포인트 더 높았으며, 평균 차이는 2.64% 포인트였습니다. 그 결과 해당 연도에 시험을 치른 전체 학생의 1.1%(N = 2명)에서 7.4%(N = 12명)까지, 총 161명에서 182명에 이르는 매우 작지만 꾸준히 불합격 학생이 증가했습니다.
The passing score using the borderline regression method was consistently higher but to a varying degree in the seven years following the institution of its piloting and use (Table 4). The overall passing score ranged from 0.6 to 4.0 percentage points higher with a mean difference of 2.64 percentage points. This resulted in an increase in a very small-but-consistent increase in student failures ranging from 1.1% (N = 2) to 7.4% (N = 12) of the total students taking the exam in the year, which ranged from a total of 161 to 182 students.
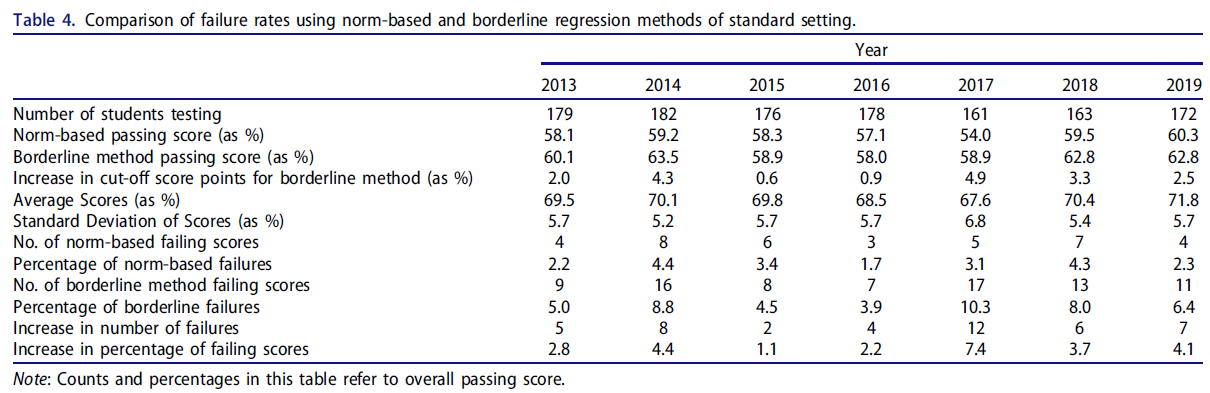
표 2의 결과는 무작위 효과 공변량 분석에서 체크리스트 점수와 전체 점수의 변동성 정도를 나타냅니다. 체크리스트 사례/평가자 측면의 표준편차는 0.056으로 전체 평균인 0.96에 비해 상대적으로 작았습니다. 마찬가지로 전체 점수의 경우 사례/평가자 표준편차는 0.31로, 0~5점 사이의 등급 범위에 비해 스테이션 간 변동성이 훨씬 작았습니다. 이러한 결과는 등급과 점수의 변동성이 부분적으로 스테이션 간의 차이로 인한 것으로, 스테이션 간 점수가 비교적 균일하다는 것을 시사합니다.
The results in Table 2 describe the degree of variability of checklist scores and global scores from the random effects ANOVA analysis. The checklist case/rater facet had a standard deviation of 0.056, which is relatively small, compared to the overall mean of 0.96. Similarly, the global scores had a case/rater standard deviation of 0.31, which is even smaller variability across stations relative to the rating range of 0 to 5. These results suggested that the variability in the ratings and scores was in small part due to differences between the stations, indicating relatively homogeneous scoring across stations.
토론
Discussion
경계선 회귀 표준 설정 방법을 사용하여 8개의 임상 사례 OSCE에서 신뢰할 수 있는 합격 기준을 생성할 수 있었으며, SP는 SP로서의 관점에서 글로벌 등급 항목을 사용하는 유일한 평가자였습니다. 개별 사례 점수만으로는 신뢰도 기준을 충족하지 못하지만, 8개 사례의 점수는 각각 신뢰도 > =0.70이었습니다. OSCE에서 글로벌 등급을 사용하면 타당한 점수를 산출한다는 연구 결과가 여러 차례 발표되었습니다(Solomon 외. 2000; Scheffer 외. 2008). 그러나 본 연구에서는 글로벌 등급 점수만으로는 합격/불합격 결정을 내릴 수 있는 신뢰도 기준을 충족하지 못했지만, 경계선 회귀 방법의 일부로 사용했을 때 수용 가능한 수준 이상의 신뢰도를 보여주었습니다. 또한 경계선 회귀법을 사용한 결과 불합격률이 상대적으로 적게 증가하여 우리 기관의 정치적, 재정적 관점에서 전적으로 수용 가능한 것으로 나타나 이러한 기준 설정 방법의 변경이 매우 실현 가능한 것으로 나타났습니다.
We were able to produce reliable passing standards in an eight-case clinical encounter OSCE using the borderline regression standard setting methods with SPs as the only raters employing the global rating item from their perspective as an SP. Using any individual case score alone would not meet reliability standards, but scores from each of the 8 cases had dependability > =0.70. There have been several studies showing the use of global rating producing a valid score in OSCEs (Solomon et al. 2000; Scheffer et al. 2008). In our study, however, use of the global rating score alone would not meet reliability standards on which to make a pass/fail decision, but used as part of the borderline regression method it demonstrated more than acceptable dependability. In addition, our results showed that the relatively small increase in failure rate using the borderline regression method was entirely acceptable from both a political and financial perspective at our institution making this change in standard setting method to be very feasible.
경계선 회귀 방법은 교수 평가자를 사용하는 성과 기반 시험의 표준 설정에 매우 신뢰할 수 있는 방법이라는 것이 입증되었습니다. 또한 Homer와 Pell(2009)은 모의 환자의 평가를 포함시킴으로써 교수 평가에 비해 OSCE 평가의 신뢰도가 높아졌음을 보여줄 수 있었습니다. 또한, 경계선 회귀법은 (직접 비교 연구 시) 성과 기반 평가를 위한 유일한 근거 기반 표준 설정 방법인 Angoff 방법보다 더 신뢰할 수 있는 점수를 산출했습니다(Dauphinee 외. 1997; Kramer 외. 2003). 영국의 5개 학교에서 6개의 OSCE 사례에 대한 합격 기준을 설정하는 데 Angoff 방법을 사용했을 때, 이 학교들에서 설정된 기준에는 허용할 수 없는 변동성이 있었습니다(Boursicot 외. 2006). 경계선 그룹과 수정된 경계선 모두 OSCE의 표준 설정 방법으로 인정받고 있지만, 경계선 회귀 방법은 신뢰도가 높고 오류가 적으며 특히 소수의 학습자가 참여하는 OSCE에 유용한 것으로 나타났습니다(Wood et al. 2006). 최근 연구에서는 다른 표준 설정 방법과 경계선 회귀 방법을 비교하여 경계선 회귀 방법을 상대적 황금 표준으로 삼았습니다(Yousuf 외. 2015; Malau-Aduli 외. 2017). 경계선 그룹 방법의 사용은 경계선 회귀 방법을 사용하기 위한 통계적 지원이 없는 프로그램에서 고려할 수 있는 중요한 방법입니다.
The borderline regression method has been shown to be a highly reliable method for standard setting for performance-based exams using faculty raters. In addition, Homer and Pell (2009) were able to show an increased level of reliability in their OSCE assessments over the faculty ratings by including the ratings of simulated patients. Furthermore, the borderline regression method, when studied in direct comparison, has produced more reliable scores than the Angoff method, which is the only other evidence based standard setting method for performance-based assessment (Dauphinee et al. 1997; Kramer et al. 2003). When the Angoff method was used to set passing standards for a set of 6 OSCE cases across five schools in the UK, there was unacceptable variability in the standards set across these schools (Boursicot et al. 2006). While both the borderline group (Kilminster and Roberts 2004) and modified borderline (Humphrey-Murto and Macfadyen 2002) are both accepted standard setting methods for OSCEs, the borderline regression method has been shown to have greater reliability, lower error and be particularly useful when the OSCE involves a small number of learners (Wood et al. 2006). Recent studies have compared other standard setting methods to the borderline regression method as the relative gold standard (Yousuf et al. 2015; Malau-Aduli et al. 2017). Use of the borderline group method is an important method to consider for programs without the statistical support to use the borderline regression method.
비의사 평가자(SP)가 임상 술기 OSCE의 맥락에서 신뢰할 수 있는 글로벌 평가 점수를 산출할 수 있는지에 대한 질문과 관련하여, 우리의 결과는 비의사를 포함한 비전문가도 글로벌 평가를 사용할 때 신뢰할 수 있는 평가자 역할을 할 수 있다는 최근의 문헌과 일치합니다. 외과 분야에서는 콘텐츠 전문성 수준이 평가 점수의 신뢰도 향상과 관련이 없으며(Patnaik 외. 2020), 의대생 OSCE를 포함하여 훈련된 비전문가도 신뢰할 수 있고 타당한 성과 기반 평가를 제공할 수 있다는 연구(Mahmood 외. 2018; Pradarelli 외. 2021)가 여러 차례 발표되었습니다(Donohoe 외. 2020). 본 연구 결과는 본 연구와 더 밀접한 관련이 있는 연구와 일치합니다. Berger 등(2012)과 최근 Yudkowsky 등(2019)은 비임상 평가자가 상세한 채점 루브릭을 제공받았을 때 교수 평가자만큼 신뢰성 있게 OSCE 환자 기록을 채점하고 임상 추론을 평가할 수 있음을 보여 주었기 때문입니다. 마지막으로 Han 등(2006)은 일반화 가능성 분석을 통해 의대 4학년 학생을 대상으로 의사소통 기술 태도와 전반적인 수행을 평가하는 5점 만점 항목 3개를 사용할 때 SP 평가자가 교수 평가자보다 더 신뢰할 수 있는 점수를 산출할 수 있음을 입증할 수 있었습니다. 이 결과는 'SP 기반 기본 임상술기 시험에 전문가가 필요한가'라는 질문에 대한 답이기도 합니다(한 외, 2006, 308쪽). 이 의문을 해결하기 위해 다음 프로젝트에서는 교수진에게 동일한 체크리스트를 사용하게 하고, 비디오로 촬영한 학생의 모습에 대한 SP와 교수진의 평가를 직접 비교하는 연구를 진행할 예정입니다.
Regarding the question of whether a non-physician rater (SP) can produce a reliable global rating score in the context of a clinical skills OSCE, our results are in alignment with the growing literature that non-experts, including non-physicians, can serve as reliable raters even when using global rating. In the field of surgery, there are several studies showing that level of content expertise is not associated with improved reliability in rating scores (Patnaik et al. 2020) and that trained non-experts can provide reliable and valid performance-based assessments (Mahmood et al. 2018; Pradarelli et al. 2021) including in a medical student OSCE (Donohoe et al. 2020). Our results are in accord with research more closely related to our study, as both Berger et al. (2012) and more recently Yudkowsky et al. (2019) showed that non-clinician raters, when provided with a detailed grading rubric were able to score OSCE patient notes and assess clinical reasoning as reliably as faculty raters. Lastly, Han et al. (2006) was able to demonstrate, using generalizability analysis, that when using three 5-point global items assessing communication skills attitude and overall performance, SP raters could produce more reliable scores than the faculty raters in a 4th year medical student. Our results also echo the question they raised, ‘whether experts are required for an SP based basic clinical skills exam’ (Han et al. 2006 p. 308). In order to further address this question, our next project will be to have faculty use the same checklists and to directly compare SP and faculty ratings of students’ videotaped encounters.
본 연구의 잠재적으로 중요한 한계 중 하나는 단일 기관에서 표준화된 단일 환자를 대상으로 수행되었다는 점입니다. 우리 SP는 경험이 풍부하고 수년에 걸쳐 누적적으로 매우 잘 훈련된 사람들입니다. 우리는 지속적으로 우리와 함께 일할 수 있는 미취업 배우가 많은 도시에 위치하고 있습니다. 새로운 SP 프로그램이나 아직 배우로 훈련받지 않은 사람들을 훈련시키는 프로그램을 운영하는 기관에서는 본 연구에서 발견한 수준의 신뢰도를 재현하지 못할 가능성이 높습니다. 또한, 본 연구의 일반화 가능성에 대한 또 다른 잠재적 한계는 본 연구가 임상 환자를 대상으로 임상 기술을 평가하는 OSCE였다는 점입니다. 보다 다양한 학생의 술기를 평가하는 OSCE에는 유용하지 않을 수 있습니다. 마지막으로, OSCE 설계의 효율적이고 비용 효율적인 특성으로 인해 평가자와 사례 효과를 분리하여 독립적으로 연구할 수 없기 때문에 SP, 체크리스트 항목 또는 사례 특징을 조정할 수 있는 진단 능력이 제한됩니다. 그러나 신뢰도 추정치는 이러한 제한의 영향을 받지 않습니다.
One of the potentially significant limitations of our study is that it was done in a single institution using a single cadre of standardized patients. Our SPs are highly experienced and cumulatively over the years, very well trained. We are located in a city with a large number of underemployed actors who are consistently available to work with us. It is quite possible that institutions with newer SP programs or programs that train people not already trained as actors might not be able to reproduce the level of reliability found in our study. In addition, another potential limitation to the generalizability of these findings is that ours was an OSCE evaluating clinical skills with clinical patient encounters. It may not be as useful for OSCEs that assess a greater variety of student skills. Finally, because of the efficient and cost-effective nature of the OSCE design, it is not possible to disaggregate rater and case effects such that they can be studied independently, which limits our diagnostic ability to adjust SPs, checklist items, or case features. However, the estimates of dependability are unaffected by this limitation.
요약하면, 우리의 결과는 글로벌 등급을 제공하는 데 있어 SP의 역할을 뒷받침하는 새로운 연구 및 문헌을 더욱 확인시켜 주며(Homer and Pell 2009), 경계선 방법이 매우 신뢰할 수 있는 합격 기준 점수를 생성할 수 있다는 과거의 연구 결과와도 일치합니다(Dauphinee 외. 1997; Kramer 외. 2003). 신뢰도 높은 전체(및 스테이션) 커트라인 점수에 대한 증거는 이 방법에 대한 신뢰도 증가에 추가적인 신뢰를 제공합니다(Yousuf 외. 2015; Malau-Aduli 외. 2017). 임상의가 아닌 SP가 신뢰할 수 있고 유효한 성과 기반 평가를 생성할 수 있고(Mahmood 외. 2018; Patnaik 외. 2020; Donohoe 외. 2020; Pradarelli 외. 2021), 잘 훈련된 SP가 교수진과의 신뢰도에 상응하는 평가를 생성할 수 있다는 다른 연구 결과(Berger 외. 2012; Yudkowsky 외. 2019)에 따라, 단독 SP를 평가자로 사용하는 경계선 방법이 매우 신뢰할 수 있는 기준 점수를 생성한다는 것을 발견했습니다. 이상적으로는 타당도 프로세스의 다음 단계는 합격 또는 불합격 결정의 기준 및 예측 타당도를 탐색하는 것이지만, 전문적인 효능 및 결과 데이터의 가용성이 부족하기 때문에 수집하기 매우 어려운 증거입니다.
In summary, our results further confirm the emerging research and literature that supports the role of SPs in providing global ratings (Homer and Pell 2009), and our results are also consistent past findings that the borderline method can produce highly dependable pass criterion scores (Dauphinee et al. 1997; Kramer et al. 2003). Our evidence of highly reliable overall (and station) cut scores gives additional credence to the increasing confidence in the method (Yousuf et al. 2015; Malau-Aduli et al. 2017). In line with other research finding that non-clinician SPs can produce reliable and valid performance-based assessments (Mahmood et al. 2018; Patnaik et al. 2020; Donohoe et al. 2020; Pradarelli et al. 2021), and that well-trained SPs can produce ratings commensurate in reliability with faculty (Berger et al. 2012; Yudkowsky et al. 2019), we found that the borderline method using sole SPs as raters produced a highly reliable criterion score. Ideally, a next step in our validity process would be to explore criterion and predictive validity of our pass or fail decisions, which is very difficult evidence to collect, given the scant availability of professional efficacy and outcomes data.
결론
Conclusion
결론적으로, 우리가 사용한 표준 설정 방법은 평가자가 OSCE 동안 한 가지 추가 항목(글로벌 평가)만 완료하면 됩니다. 성과 기반 평가에서 SP 평가자를 사용하는 기관은 환자의 관점에 기반한 글로벌 평가 항목 사용에 대해 SP에게 짧은 교육(본 연구에서는 1시간)만 받으면 이 표준 설정 방법을 활용할 수 있습니다. 요약하면, 본 연구는 경계선 회귀 방법을 SP만 평가자로 사용하여 임상 진료 OSCE에서 신뢰할 수 있는 합격 점수를 생성하는 데 사용할 수 있음을 보여줍니다.
In conclusion, the standard setting method we used requires only that the raters complete one additional item (global rating) during the OSCE. Institutions using SP raters in a performance-based assessment can utilize this standard setting method with a short training (one hour in our study) of their SPs on the use of the global rating item based on their perspective as the patient. In summary, our study demonstrates that the borderline regression method can be used with only SPs as raters to create reliable passing scores in a clinical encounter OSCE.
A resource efficient and reliable standard setting method for OSCEs: Borderline regression method using standardized patients as sole raters in clinical case encounters with medical students
PMID: 35234562
Abstract
Finding a reliable, practical and low-cost criterion-referenced standard setting method for performance-based assessments has proved challenging. The borderline regression method of standard setting for OSCEs has been shown to estimate reliable scores in studies using faculty as raters. Standardized patients (SPs) have been shown to be reliable OSCE raters but have not been evaluated as raters using this standard setting method. Our study sought to find whether SPs could be reliably used as sole raters in an OSCE of clinical encounters using the borderline regression standard setting method.SPs were trained for on a five-point global rating scale. In an OSCE for medical students, SPs completed skills checklists and the global rating scale. The borderline regression method was used to create case passing scores. We estimated the dependability of the final pass or fail decisions and the absolute dependability coefficients for global ratings, checklist scores, and case pass-score decisions using generalizability theory.The overall dependability estimate is 0.92 for pass or fail decisions for the complete OSCE. Dependability coefficients (0.70-0.86) of individual case passing scores range demonstrated high dependability.Based on our findings, the borderline regression method of standard setting can be used with SPs as sole raters in a medical student OSCE to produce a dependable passing score. For those already using SPs as raters, this can provide a practical criterion-referenced standard setting method for no additional cost or faculty time.
Keywords: OSCE; Standard-setting; borderline-regression; generalizability theory; global-rating; standardized patients (SPs).
'Articles (Medical Education) > 평가법 (Portfolio 등)' 카테고리의 다른 글
| 사회문화적 학습이론과 학습을 위한 평가 (Med Educ, 2023) (0) | 2023.11.05 |
|---|---|
| 작은 코호트 OSCE에서 방어가능한 합격선 설정하기: 언제 경계선 회귀방법이 효과적인지 이해하기(Med Teach, 2020) (0) | 2023.09.08 |
| OSCE에서 경계선 집단 방법과 경계선 회귀 방법을 기준-기반 합격선 설정과 비교(J Educ Eval Health Prof. 2021) (0) | 2023.09.08 |
| OSCE 합격선 설정: 세 가지 경계선 집단 방법(Medical Science Educator, 2022) (0) | 2023.09.08 |
| OSCE의 타당도 근거 평가하기: 신설 의과대학으로부터의 결과(BMC Med Educ, 2018) (0) | 2023.09.08 |