OSCE의 타당도 근거 평가하기: 신설 의과대학으로부터의 결과(BMC Med Educ, 2018)
Evaluating the validity evidence of an OSCE: results from a new medical school
Vanda Yazbeck Karam1* , Yoon Soo Park2, Ara Tekian2 and Nazih Youssef1

배경
Background
기존 임상 평가의 문제점을 방지하기 위해 Harden은 보다 타당하고 신뢰할 수 있는 평가 도구로 "객관적 구조화 임상 검사(OSCE)"를 제시했습니다[1]. 그러나 고품질의 효과적인 OSCE를 보장하기 위한 필수 조건은 점수의 타당성을 뒷받침하는 증거를 확보하는 것입니다[2].
To prevent the problems of traditional clinical evaluation, the “Objective Structured Clinical Examination (OSCE)” was presented by Harden as a more valid and reliable assessment instrument [1]. However, an essential condition to guarantee a high-quality and effective OSCE is the assurance of evidence to support the validity of its scores [2].
검사의 타당도는 해당 검사가 측정하고자 하는 것을 얼마나 잘 측정하는지를 의미하며, 따라서 검사의 타당도는 여러 증거를 수집하여 축적되어야 합니다[3]. 1989년 Messick은 현대적인 타당도 프레임워크[4]를 제안했으며, 이는 1999년[5]과 2014년[6]에도 실무 표준으로 간주되었습니다. Messick의 구성 타당도 이론에는 테스트 개발을 뒷받침하는 증거와 결과의 결과가 포함됩니다[4]. Messick의 프레임워크에 따르면, 평가 도구에서 생성된 점수를 수락하거나 반박하기 위해서는 다섯 가지 타당도의 원천을 고려해야 합니다[4]. 다섯 가지 원천은 다음과 같다.
- 내용(시험 문항이 관심 구성의 특징),
- 응답 과정(데이터 일관성의 증거),
- 내부 구조(시험의 심리 측정적 특성),
- 다른 변수와의 관계(동일한 주제를 측정하는 유사하거나 다른 도구와의 결과 일치) 및
- 결과(학습자, 교수자 및 커리큘럼에 미치는 영향)
The validity of a test is the degree to which this test measures what is intended to measure and hence the validity of a test should be accumulated by collecting several sources of evidence [3]. In 1989, Messick proposed a modern validity framework [4] that was considered a standard of practice in 1999 [5] and also in 2014 [6]. The theory behind Messick’s construct validity includes the evidence supporting the test development and the consequences of the results [4]. According to Messick’s framework, five sources of validity should be considered in order to accept or refute the scores generated by any assessment tool [4]. The five sources are:
- content (test items are characteristic of the construct of interest),
- response process (evidence of data coherence),
- internal structure (psychometric properties of the exam),
- relations with other variables (alignment of results with similar or different tools measuring the same subject) and
- consequences (impact on learners, instructors, and curriculum) [4].
OSCE에서 생성된 점수의 타당성은 측정할 영역을 적절하게 표본화할 수 있는 능력에 따라 달라집니다[7]. 궁극적으로 효과적인 OSCE는 인지, 정신 운동 및 정서 능력을 테스트해야 합니다. 그러나 OSCE는 주로 밀러 피라미드의 'shows how' 수준을 평가하는 데 사용됩니다[8]. 우리의 목적은 Messick의 이론을 개념적 프레임워크로 사용하여 레바논 아메리칸 대학교 - 의과 대학(LAU-SOM)에서 시행한 OSCE의 구성 타당성을 조사하는 것입니다. 내부 구조와 결과 타당도를 뒷받침하는 데 중점을 두고 다양한 증거 자료를 수집하려고 시도했습니다. 다른 검증 연구와 달리, 본 조사는 점수 추론의 타당성이 표준 설정 기법의 적절한 적용에 크게 좌우되는 OSCE의 총합적 적용을 기반으로 했습니다. 연구의 또 다른 목적은 합격/불합격 커트라인 점수를 결정하기 위한 합격선 설정 방법으로 경계선 회귀법(BRM)을 사용하고, 이를 기존의 결과 계산 방법과 비교하는 것이었습니다.
The validity of the scores generated by any OSCE depends on its capability to appropriately sample the domain to be measured [7]. Ultimately, an effective OSCE should test cognitive, psychomotor, and affective skills. However, the OSCE is principally used for the assessment of the ‘shows how’ level of Miller’s pyramid [8]. Our purpose is to examine, using Messick’s theory as a conceptual framework, the construct validity of an OSCE we administered at the Lebanese American University – School of Medicine (LAU-SOM). We attempted to gather multiple sources of evidence with an emphasis on supporting internal structure and consequential validity. Unlike other validation studies, our investigation was based on a summative application of an OSCE where the validity of the score inferences is dependent, to a great extent, on the proper application of standard setting techniques. The other objective of the study was the use of the Borderline Regression Method (BRM) as a method for standard setting to determine the pass/fail cut scores and its comparison to our traditional method of computing the results.
연구 방법
Methods
연구 참가자
Study participants
이 연구는 학사 학위 후 4년의 통합 커리큘럼을 따르는 LAU-SOM에서 실시되었습니다. 평가 배터리에는 OSCE를 포함한 총괄 및 형성 도구가 포함되어 있습니다. LAU의 OSCE 팀은 표준화 환자(SP)를 모집하고 교육하는 연극 교사 1명과 사례를 작성하고 체크리스트를 개발하는 의사 2명으로 구성되어 있습니다. 53명의 1학년 의대생이 혈액학 및 내분비학 모듈을 평가하는 총괄적 OSCE에 참여했습니다. LAU 기관윤리심의위원회에서 윤리 승인을 받았습니다. 학생들은 두 개의 동시 트랙과 세 번의 연속 시험 기간을 사용하여 같은 날에 평가를 받았습니다. 각 트랙에는 임상 시뮬레이션 센터의 다른 방에 위치한 동일한 스테이션이 포함되었습니다. 각 트랙은 7개의 OSCE 스테이션으로 구성되었습니다. 5개 스테이션은 시험관, SP 또는 시험실에 있는 마네킹과 환자가 마주치는 상황으로 구성되었습니다. 나머지 두 스테이션은 병리학 및 미생물학 스테이션이었기 때문에 분석에서 제외되었습니다.
This study was conducted at the LAU-SOM, where a 4-year integrated curriculum is followed after a Bachelor’s degree. The assessment battery includes summative and formative tools, including OSCEs. The OSCE team at LAU comprises one drama teacher who recruits and trains standardized patients (SPs) and two physicians who write cases and develop checklists. Fifty-three first year medical students took part in a summative OSCE evaluating the hematology and endocrinology modules. Ethics approval was granted by the LAU Institutional Review Board. Using two simultaneous tracks and three consecutive testing periods, students were assessed on the same day. Each track included the same stations located in different rooms of the clinical simulation center. Each track comprised seven OSCE stations. Five stations consisted of patient encounters with an examiner and an SP or a manikin present in the room. The other two stations were pathology and microbiology and therefore were excluded from our analysis.
콘텐츠
Content
내용 증거는 평가 대상 구조가 시험에서 정확하고 완벽하게 표현되었는지를 확인하는 것을 의미합니다[9].
- OSCE 스테이션에는 혈액학 및 내분비학 모듈과 관련된 다양한 임상 술기가 포함되었습니다: 1-발 검사, 2-목 검사, 3-커플 스테이션: 피로가 있는 환자의 병력 청취 및 기록, 4- 지중해빈혈 상담, 5-유방 검사. 각 스테이션은 30분 동안 진행된 3번 스테이션을 제외하고 10분씩 진행되었습니다.
- 다양한 콘텐츠 전문가들이 파일럿 테스트에 앞서 사례를 작성하고 검토했습니다. 또한 모든 체크리스트는 콘텐츠 전문가들의 자문을 거쳐 평가 결과에 따라 사전에 개발되었습니다.
- 의사 시험관(PE)은 학생들의 수행을 직접 관찰하고 체크리스트 성적과 글로벌 등급 성적을 모두 제공했습니다. 또한, 병력 청취 및 의사소통 능력을 평가하는 스테이션의 경우 SP가 채점한 체크리스트가 사용되었으며, 체크리스트 성적에 10%의 가중치를 부여하여 성적을 합산했습니다(추가 파일 1).
- OSCE가 끝나면 완성된 체크리스트의 정확성을 점검했습니다.
Content evidence refers to ensuring that the construct being assessed is accurately and completely represented on a test [9].
- The OSCE stations included various clinical skills related to the hematology and endocrinology modules: 1-ft exam, 2-neck exam, 3-couplet station: history taking patient with fatigue and write-up, 4-counseling for thalassemia, and 5-breast exam. Each station was 10 min except station three that lasted 30 min.
- Different content experts wrote and reviewed the cases that were pilot-tested prior to their implementation. Moreover, All checklists were developed in advance, following consultation with the content experts and in line with outcomes being assessed.
- The physician examiners (PEs) directly observed students’ performance and provided both grades; the checklist grades and the global rating grades. In addition, for stations assessing history taking and communication skills, a checklist scored by the SP was used and its grade added to the checklist grade with a weight of 10% (Additional file 1).
- At the end of the OSCE, the completed checklists were checked for their accurateness.
응답 프로세스
Response process
응답 프로세스는 체크리스트에 의해 수집된 데이터의 정확성과 무결성을 보장하여 편향 가능성을 줄입니다[6]. 최종 점수의 타당성은 평가자가 제공한 성적의 정확성과 직접적으로 관련이 있습니다.
- 의사 시험관(PE)은 의과대학에서 교육을 받은 교수진으로 구성되었습니다. 이들은 2시간 동안 체크리스트 항목, 채점 과정, 예상되는 학생의 행동에 익숙해지도록 적절한 지침을 제공받았습니다. OSCE 당일에는 채점 시스템에 대한 지침을 강화했습니다.
- 체크리스트에는 각 스테이션별로 10~35개 항목이 포함되어 있습니다(추가 파일 2). 각 항목은 과제 완료도와 상관관계가 있는 3점 척도를 사용하여 채점되었습니다.
- 글로벌 평가 점수는 학생의 전반적인 성과와 관련된 5점 척도로 구성되었으며, 체크리스트 항목별 점수가 아닌 스테이션의 글로벌 인상을 기반으로 했습니다. 글로벌 평가 기술서의 하드 카피는 시험관 파일(추가 파일 3)의 각 스테이션에 보관되었습니다.
- SP는 각 2시간씩 세 차례에 걸쳐 자신의 역할에 대한 적절한 교육을 받았습니다. 이들에게는 각자의 역할, 학생들이 질문할 수 있는 잠재적 질문, 각 질문에 대한 적절한 답변을 포함한 사례 세부 정보가 제공되었습니다.
- OSCE를 진행하는 동안 전담 직원이 각 학생의 라운드가 끝난 후 체크리스트 항목의 완성도와 글로벌 등급을 모니터링했습니다.
Response process ensures the correctness and the integrity of the data collected by the checklists to reduce any possible bias [6]. The validity of the final scores relates directly to the accuracy of the grades provided by the assessors.
- Physician examiners (PEs) were trained faculty from the School of Medicine. For this OSCE, they were provided with the appropriate instructions during a 2-h session in order to get familiar with the checklists’ items, the marking process, and the expected students’ behavior. Updating on the OSCE day reinforced the guidelines about the marking system.
- Checklists included 10–35 items for each station (Additional file 2). Each item was scored using a 3-point scale correlated to the task completion.
- The global rating score consisted of a 5-point scale associated with the overall performance of the student and based on the PEs’ global impression and not on the items’ scores. A hard copy of the global rating descriptors was kept in each station in the examiner file (Additional file 3).
- SPs were properly trained for their roles over three sessions, 2 h each. They were provided with the case details including their roles, any potential questions students may ask, and the appropriate answer for each question.
- During OSCE administration, the completeness of the checklist items and the global rating was monitored by dedicated staff after each round of students.
결과 타당도
Consequences
결과 타당도는 시험 점수가 수험생에게 미치는 실제 및 잠재적 영향을 탐구합니다. 합격률 또는 커트라인 점수는 결과 타당도의 출처와 밀접한 관련이 있습니다[10]. 합격 점수는 허용 가능한 성능을 입증하고 시험에 합격하는 데 필요한 최소 점수입니다. 합격선은 무작위적인 결정을 통해 설정될 수 있지만, 합격선 설정은 논리적이고 정당한 방식으로 신뢰할 수 있고 수용 가능한 합격 또는 커트라인 점수를 도출하는 프로세스입니다[11].
- OSCE에서는 BRM을 적용하여 합격 기준을 설정했습니다[12,13,14]. 체크리스트와 글로벌 등급 점수는 각 스테이션에 대해 별도로 보고되었습니다. 글로벌 등급은 표준 설정 계산에만 사용했습니다.
- 각 스테이션에 대해 체크리스트를 종속변수로, 글로벌 등급을 독립변수로 고려한 선형 회귀 모델을 사용했습니다. 회귀선을 사용하여 글로벌 등급의 커트라인 '2'(경계선)에 해당하는 체크리스트 점수를 계산하여 스테이션별 BR 합격/불합격 기준을 구했습니다.
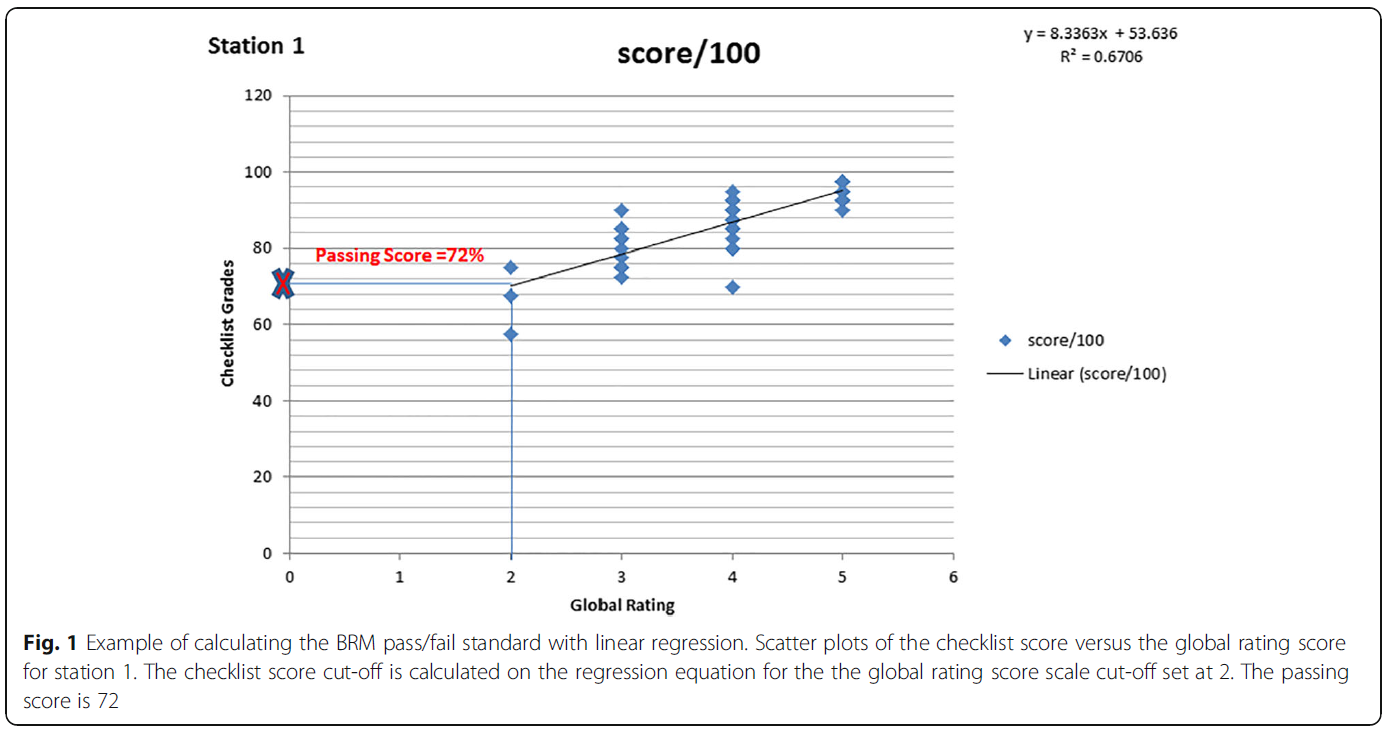
- 스테이션 1에 대한 기준 설정 계산 예는 그림 1에 나와 있습니다. 경계선 그룹에 해당하는 글로벌 등급 척도의 2점을 삽입하면 그에 해당하는 예상 체크리스트 점수가 결정될 수 있습니다. 이 예측 점수 72점이 이 스테이션의 합격/불합격 기준이 되었습니다. 총 시험 점수는 스테이션 체크리스트 점수를 평균하여 계산되었습니다.
- 5개 스테이션에 대한 해당 합격/불합격 기준은 스테이션 커트라인 점수의 평균으로 정의되었으며, 30분간 지속된 커플링 스테이션이므로 4번 스테이션에 가중치 2를 부여한 것을 제외한 모든 스테이션에 가중치 1을 부여했습니다. 경계선 회귀법(방법 2)을 사용한 OSCE의 합격/불합격 결과는 75%의 가중치가 부여된 체크리스트 성적에 25%의 가중치가 부여된 글로벌 등급 성적을 합산하는 현재의 결과 산출 방법(방법 1)과 비교했습니다.
Consequential validity explores the real and latent impact of any test scores on examinees. Passing rates or cut-off scores are closely linked to the sources of consequential validity [10]. The passing score is the minimum score needed to demonstrate acceptable performance and pass the test. While standards may be set using random decisions, standard setting is a process that results in a credible and acceptable passing or cut-off scores in a logical and justifiable manner [11].
- In our OSCE, the BRM was applied to establish a passing standard [12,13,14]. Checklists and global rating scores were reported separately for each station. We used the global rating solely for the calculation of standard setting.
- For each station, a linear regression model was utilized, with the consideration of the checklist as dependent variable and the global rating as independent variable. The BR pass/fail standard per station was obtained by using the regression line to calculate the checklist score corresponding with the cut-off point ‘2’ (borderline) of the global rating.
- An example for the calculation of the standard setting for station one is shown in Fig. 1. By inserting the point 2 of the global rating scale corresponding to the borderline group, a corresponding predicted checklist score could be determined. This predicted score 72 became the pass/fail standard for this station. The total test score was calculated by averaging the station checklist scores.
- The corresponding pass-fail standard for the five stations was defined as the average of the stations cut-scores, giving all stations a weight of one except station four with a weight of two since this is a couplet station that lasted 30 min. The pass/fail results of the OSCE using the borderline regression method (Method 2) were compared to our current method of computing the results (Method 1) that consists of ading the checklist grades with a weight of 75% to the global rating grades with a weight of 25%.
내부 구조
Internal structure
내부 구조 타당도 증거는 문항 간 상관관계, 시험 난이도 및 점수 신뢰도를 포함하는 시험의 심리측정 측정과 관련이 있습니다. 신뢰도는 다음 지표를 사용하여 평가했습니다:
- 1- 크론바흐 알파는 내적 일관성을 측정하는 것으로, 효과적인 시험에서는 우수한 학생이 모든 문항에서 비슷한 성적을 보여야 합니다. SP가 사용되는 OSCE에서 허용되는 알파 값은 0.7 이상입니다. 그러나 더 낮은 등급의 시험에서는 이보다 낮은 값의 크론바흐 알파가 허용됩니다.
- 2- R2 계수는 총점 점수와 체크리스트 점수 간의 제곱 선형 상관관계입니다. 두 점수는 양의 상관관계가 있을 것으로 예상됩니다. R2 = 0.5는 적절한 것으로 간주되며,
- 3- 등급 간 변별력은 총체적 평가에서 등급이 한 단계 올라갈 때마다 체크리스트 점수가 평균적으로 증가하는 것을 의미합니다. 적절한 변별력은 체크리스트에 의해 생성될 수 있는 최대 점수의 10분의 1,
- 4- 불합격자 수는 특정 과목에 대한 교육의 질과 변화의 필요성을 검토하는 데 사용,
- 5- 집단 간 변동는 수험생의 수행보다는 환경과 평가자의 태도가 점수에 미치는 영향과 관련이 있습니다. 이상적인 평가 과정에서는 모든 차이가 학생의 성과로 인한 것이어야 하므로 그룹 간 편차는 30% 미만이어야 하며,
- 6- 체크리스트 성적에 [10%의 가중치를 부여한 표준화 환자 등급]은 이러한 데이터를 통합하는 강력한 방법으로 평가의 신뢰도를 향상시키는 것으로 보입니다(Homer et al. 2009). SP 등급이 정상보다 높은 실패율과 결합된 경우, 이는 해당 주제에 대한 부적절한 교육의 결과일 수 있습니다.
The internal structure validity evidence correlates to the psychometric measures of the test encompassing inter-item correlations, exam difficulty and score reliability. Reliability was evaluated using the following metrics:
- 1- Cronbach’s alpha measures the internal consistency whereby in an effective test, better students should perform similarly well in all stations. Acceptable alpha value in OSCEs where SPs are used is 0.7 or above. However, in lower stakes exam, a Cronbach’s alpha of a lesser value is acceptable;
- 2- R2 coefficient is the squared linear correlation between the holistic rating score and the checklist score. It is expected that the two scores be positively correlated. An R2 = 0.5 is considered reasonable;
- 3- inter-grade discrimination is the average increase in scores of the checklist for each grade increase on the holistic rating. An adequate discrimination index should be the tenth of the maximum score that could be generated by the checklist;
- 4- number of failures is used to review the quality of teaching and the need for change on a particular subject;
- 5- between group variation relates to the effect of the environment and assessor attitude on the scores rather than the performance of examinees. To note that in an ideal assessment process, all differences should be only due to student performance therefore between group variation should be under 30%,
- 6- standardized patient rating that is added to the checklist grade with a weight of 10% appears to be a robust way of incorporating such data, leading to the improved reliability of the assessment (Homer et al. 2009). If the SP rating is coupled with a higher than normal failure rate, this could be the result of inadequate teaching of the topic.
통계 분석
Statistical analysis
데이터는 Microsoft Excel, 2010을 사용하여 분석되었습니다. 연구 집단의 특성은 서술적 통계를 사용하여 평가했습니다. 데이터는 범주형 변수의 경우 숫자와 백분율로, 연속형 변수의 경우 평균 ± SD로 표현했습니다. 두 그룹 간의 평균을 비교하기 위해 독립적인 t 검정을 사용했습니다. p < 0.05의 값은 유의미한 것으로 간주했습니다. 리스케일링은 두 방법의 합격 점수가 동일(60%)하고 보고에 대한 학교 정책을 준수하기 위해 사용되었습니다.
Data were analyzed using Microsoft Excel, 2010. Characteristics of the study population were evaluated using descriptive statistics. Data were expressed as numbers and percentages for categorical variables and as means ± SD for continuous variables. Independent t tests were used for comparing means between the two groups. A value of p < 0.05 was considered significant. Rescaling was used to have the same passing score for both methods (60%) and to comply with the school policy for reporting.
결과
Results
남학생 27명, 여학생 26명, 총 53명의 학생이 이번 OSCE에 참여했습니다.
Fifty-three students, 27 males and 26 females participated in this OSCE.
시험 내용
Content
OSCE 블루프린트는 혈액학-내분비학 모듈의 주요 목표 중 5가지로 구성되었습니다(추가 파일 4). 채점 도구에는 전문가가 개발한 스테이션별 분석 채점 또는 체크리스트, 전공의가 작성한 총점 또는 5점 만점 글로벌 평가 척도, SP가 작성한 커뮤니케이션 기술 체크리스트가 포함되었습니다.
The OSCE blueprint represented five of the major objectives of the hematology-endocrinology module (Additional file 4). The scoring instruments included a station-specific analytical scoring or checklist developed by experts, a holistic score or five-point global rating scale, both filled by the PEs and a communication skills checklist filled by the SP.
대응 프로세스
Response process
저희의 PE와 SP는 다양한 체크리스트 사용에 대한 교육 세션을 받았습니다. OSCE 이후 진행된 디브리핑 세션에서 모두 체크리스트 사용에 익숙해졌다고 답했습니다.
Our PEs and SPs underwent training sessions about the use of the different checklists. During the debriefing session following the OSCE, all reported being comfortable with its use.
결과
Consequences
5개 스테이션의 커트라인 점수는 (72 × 1) + (60 × 1) + (53 × 1) + (70 × 2) + (67 × 1) = 65.16%였습니다. 이 컷 점수를 사용하면 합격률은 100%입니다.
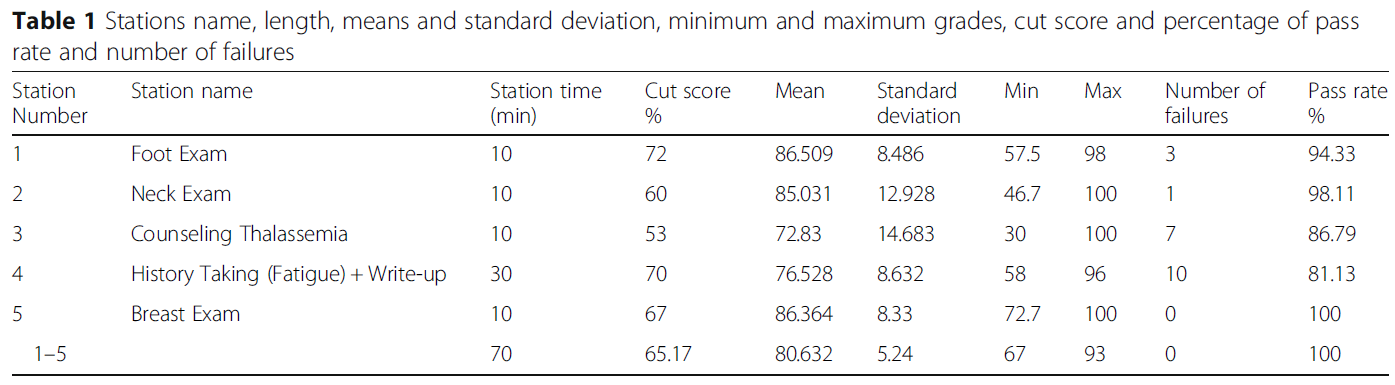
- 표 1은 스테이션의 길이, 평균 및 표준편차, 최소 및 최대 등급, 커트라인 점수, 합격률 및 불합격자 수를 보여줍니다.
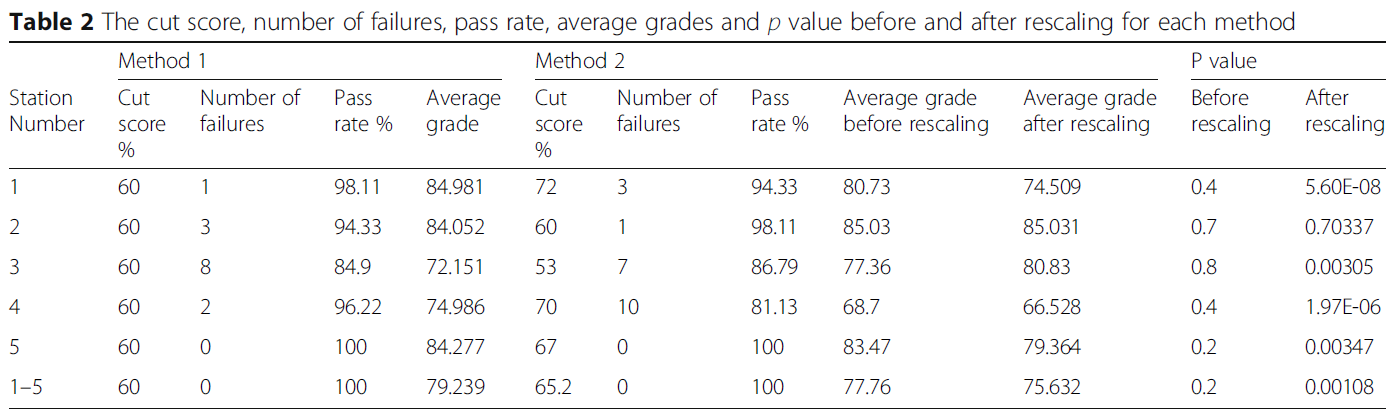
- 표 2는 BRM(방법 2)과 실제 결과 산출 방법(방법 1)을 비교한 결과를 나타냅니다.
BRM 방식이 학생들의 평균 성적(75.63점 대 79.23점)은 낮고 커트라인 점수(65.16점 대 60점)는 높았지만, 모든 스테이션 간 점수에서 통계적으로 유의미한 차이는 발견되지 않았습니다. 그러나 학교 정책에 따라 커트라인 점수인 60점으로 점수를 재조정했을 때, 전체 성적과 스테이션 2를 제외한 모든 스테이션에서 두 방법 간의 점수에서 통계적으로 유의미한 차이가 나타났습니다. 전체 시험에 대한 보상형 표준을 제공하기 위해 모든 사례에 대한 점수를 합산하기 때문에 두 가지 방법 모두 합격률은 100%였습니다.
The cut score for the 5 stations was: (72 × 1) + (60 × 1) + (53 × 1) + (70 × 2) + (67 × 1) = 65.16%. Using this cut score, the passing rate was 100%.
- Table 1 shows stations’ length, means and standard deviation, minimum and maximum grades, cut score as well as the percentage of pass rate and number of failures.
- Table 2 represents the compared results of the BRM (Method 2) to our actual method of computing the results (Method 1).
Although the BRM method showed a lower students’ average grades (75.63 vs 79.23) and a higher cut score (65.16 vs 60), no statistical significance in scores between all stations was noted. However, when scores were rescaled to the cut score of 60%, as per our School policy, a statistical difference in the scores between the two methods for the overall grade and for all stations except for station 2 was noted. The passing rate was 100% for both methods because scores are aggregated across cases to provide a compensatory-type standard for the whole test.
내부 구조
Internal structure
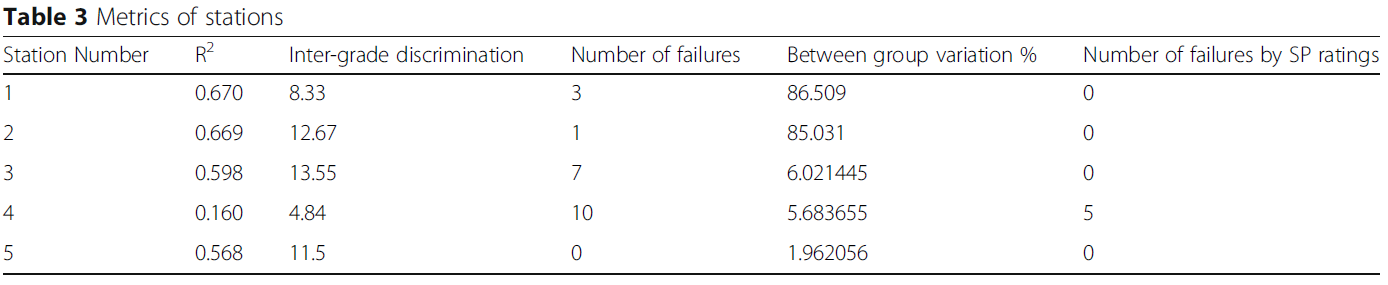
스테이션 전체에서 OSCE의 크론바흐 알파는 0.43이었습니다. 다양한 지표를 분석한 결과, 스테이션 4의 R2 값은 0.160, 스테이션 3의 등급 간 판별 지수는 13.55, 실패 횟수는 스테이션 3에서 7회(13.2%), 스테이션 4에서 10회(18.86%)로 나타났습니다. 그룹 간 편차는 30% 미만이었고 불합격 건수는 5건(9.43%)이었습니다. 각 스테이션의 메트릭은 표 3에 나와 있습니다.
Across stations, Cronbach’s alpha in our OSCE was 0.43. The analysis of the different metrics showed an R2 value of 0.160 in station four, an inter-grade discrimination index of 13.55 in station three, the number of failures of 7 in station three (13.2%) and 10 in station four (18.86%). Between group variation was less than 30% and the number of failures was five (9.43%). The metrics of the different stations are shown in Table 3.
토론
Discussion
OSCE의 품질을 확립하려면 점수의 타당성을 검증할 수 있는 증거가 필요합니다. 또한 점수 기반 추론의 타당성을 위협할 수 있는 요인도 해결해야 합니다.
To establish the quality of an OSCE, evidence is needed to verify the validity of the scores. Moreover, one must also address possible threats to the validity of score-based inferences.
타당도의 결과적 근거는 시험 성적 분석 및 사용을 의미합니다. 시험의 사용은 사회적 결과와 교육생, 교사 및 전체 교육과정에 미치는 영향을 고려해야 하는 반면, 시험 결과의 해석은 수행될 수 있는 유리한 결정과 불리한 결정 사이의 관계를 고려해야 합니다[4]. 표준 설정을 사용하여 방어 가능한 합격 점수를 선택하는 것은 교육자들에게 지속적인 도전 과제이지만 결과적 타당성의 근거를 보장하기 위한 핵심 문제입니다[15,16,17]. 오늘날 많은 교육 기관에서는 몇 가지 장점이 있는 경계선 방식을 선호합니다[18].
- 첫째, 체크리스트 점수가 아닌 수련의의 전반적인 수행 능력에 따라 달라지며, 시험 중에 전체 등급이 채점되기 때문에 임상의의 시간을 절약할 수 있습니다.
- 또한, 글로벌 등급은 불합격, 경계선, 합격의 세 가지 점수만 필요하고 경계선 학생들의 평균 분석 점수가 시험의 합격 점수가 되므로 간단한 통계적 절차만 거치면 됩니다.
The consequential basis of validity implicates test grade analysis and use. Whereas the use of tests should consider the social consequences and their impact on trainees, teachers, and the whole curriculum, the interpretation of the tests’ results should consider the relationships between the favorable and unfavorable decisions that could be undertaken [4]. Choosing a defensible passing score by employing standard settings represents a persistent challenge to educators yet it is a key issue for ensuring the consequential basis of validity [15,16,17]. Nowadays, many institutions favor the borderline method that has several benefits [18].
- First, it depends on the overall performance of trainees rather than the checklist markings and saves the clinicians’ time since the global rating is scored during the exam.
- Also, only three marks are required for global ratings (fail, borderline, pass) and the mean analytic scores of borderline students is the passing score of the exam, therefore it requires a simple statistical procedure.
그러나 우리와 같이 수험생 수가 한정된 소규모 OSCE의 경우, 경계선 범위에 있는 수험생이 소수에 불과할 경우 의도하지 않은 편향이 발생할 수 있습니다. Pell 등은 2005년에 Wood가 처음 설명한 BRM을 사용할 것을 권고했습니다[12, 19]. BRM은 소규모 OSCE에 이상적입니다. 이 방법은 선형 회귀 접근법을 통합하여 일부 하위 집합이 아닌 모든 수험자의 점수를 사용하여 커트라인 점수를 설정할 수 있도록 함으로써 글로벌 성적과 체크리스트 점수 간의 관계를 나타냅니다[14]. 이 방법을 사용하려면 5개의 글로벌 등급(예: 불합격, 경계선, 합격, 매우 우수 합격, 구별)을 사용해야 하며 계산에 더 많은 전문 지식이 필요합니다. 그러나 더 다양한 품질 보증 메트릭에 액세스할 수 있습니다[13]. 저희 OSCE에서는 표준 설정 도입으로 학생들의 평균 성적은 낮아지고 커트라인 점수는 높아졌습니다.
However, for the small-scale OSCE such as ours having a limited number of examinees, the presence of an only few examinees in the borderline range could introduce an unintentional bias. Pell et al. advised the use of the BRM that was initially described by Wood in 2005 [12, 19]. BRM is ideal in a small scale OSCE. It gives an indication of the relationship between global grade and checklist score by incorporating a linear regression approach allowing the cut score to be set using the scores from all examinees and not from a subset [14]. This method requires the use of five global ratings (e.g. fail, borderline, pass, very good pass, distinction) and more expertise for computation. However, it gives access to a wider variety of quality assurance metrics [13]. In our OSCE, the introduction of standard setting resulted in lower students’ average grades and a higher cut score.
내부 구조 타당도 증거는 OSCE의 다양한 심리측정 특성을 분석하는 것입니다[20]. 신뢰도 검사 점수는 일반화 가능성, 평가자 간 신뢰도, 평가자 일관성과 같은 다양한 지표를 사용하여 평가할 수 있으며, 일관성을 평가하는 맥락에 따라 계수 알파 또는 크론바흐 알파로 평가할 수 있습니다[21].
- 전체 스테이션에서 크론바흐 알파는 0.43으로 낮은 것으로 나타났습니다. 이는 스테이션 수가 적기 때문으로 설명할 수 있습니다. 스테이션 수를 늘리면 신뢰도가 높아질 수 있습니다[7, 22]. 이는 각 설정의 타당성과 균형을 맞춰야 합니다.
- R2 값이 낮았던 스테이션 4와 같이 특정 스테이션에서 체크리스트와 전체 등급이 불일치하는 경우, 이는 일부 학생이 '과정'에 대한 분석 체크리스트에서 많은 점수를 획득했지만 전반적인 성과가 시험관에게 깊은 인상을 주지 못했음을 나타내며 체크리스트가 능력에 대한 잘못된 지표가 될 수 있음을 시사합니다. 따라서 학생 수준과 기준을 일치시키는 데 초점을 맞춰 재설계하고, 평가자 체크리스트에 중간 등급 설명자를 포함시키고, 체크리스트 기준에 적절한 경우 앵커가 2개가 아닌 3개가 되도록 하여 평가자가 변별력을 높일 수 있도록 해야 합니다.
- 특정 시험장에서 높은 불합격률이 발생하면 커리큘럼의 특정 부분에 대한 교육을 재검토해야 합니다. OSCE에서는 스테이션 3과 4의 높은 불합격률로 인해 지중해빈혈 환자 상담과 피로 및 어지럼증에 대한 병력 청취에 대한 교육 문제가 부각되었습니다.
The internal structure validity evidence involves the analysis of the different psychometric properties of the OSCE [20]. The reliability test scores can be evaluated using various indicators such as Generalizability, inter-rater reliability, rater consistency, and by the Coefficient alpha or Cronbach’s alpha, depending on the context of consistency evaluated [21].
- Across stations, Cronbach’s alpha in our OSCE was 0.43 and is considered low. This could be explained by the low number of stations. Increasing the number of stations would result in greater reliability [7, 22]. This will have to be balanced against the feasibility in each setting.
- When a mismatch between the checklist and the global rating in a specific station is revealed, such in station four where the R2 value was low, this indicates that some students have acquired many of the marks from the analytic checklist for ‘process’, but their overall performance did not impress in parallel the examiner, suggesting that the checklists can be a poor marker of ability. Consequently, a redesign of the station should be made while focusing on matching criteria with the student level, inclusion of intermediate grade descriptors on the assessor checklists and ensuring that checklist criteria have three instead of two anchors where appropriate, thereby allowing greater discrimination by examiners.
- The presence of high failure rates at particular stations should lead to revisiting the teaching of a specific parts of the curriculum. In our OSCE, the high number of failures in station three and four highlighted teaching problems about counseling patients with thalassemia and conducting a history taking about fatigue and dizziness.
평가의 타당성에 대한 위협을 피하기 위해 OSCE의 계획 단계부터 신중하게 고려해야 합니다. 타당도에 대한 두 가지 주요 위협은 구인 과소 대표성(CU)과 구성과 무관 분산(CIV)입니다[23].
- CU는 불충분한 수의 사례 사용으로 인해 콘텐츠 영역의 샘플링이 부족한 경우와 블루프린트가 시험 스테이션을 교육과정 내용 및 목표에 매핑하지 않을 때 샘플링이 부적절한 경우를 말합니다. OSCE의 청사진에는 콘텐츠 하위 영역, 평가 대상 역량 및 환자 특성이 포함되어 있었습니다.
- CIV는 측정 대상과 무관한 변수에 의해 평가 데이터에 도입된 체계적 오류입니다. CIV의 예로는 결함이 있는 사례/체크리스트/평가 척도, 사례의 부적절한 난이도, 제대로 훈련되지 않은 표준화 환자 또는 평가자 오류 등이 있습니다. CIV의 주요 위협은 체계적인 평가자 오류로 인한 것입니다. 실제로 평가자는 평가자 심각도 또는 관용 오류, 중심 경향 오류, 후광 평가자 효과와 같은 측정 오류의 주요 원인입니다. 따라서 평가자의 평가 능력을 균일화하기 위해서는 평가자 간 합의도를 높이기 위한 교육 방법을 개선하는 것이 필수적입니다. 또한, 평가에 앞서 평가자 및 SP를 대상으로 상세한 지원 자료 제공 및 브리핑을 체계적으로 실시해야 합니다.
Threats to the validity of any assessment should be well-thought-out since the planning phase of an OSCE in order to avoid them. Two major threats to the validity are construct underrepresentation (CU) and construct-irrelevant variance (CIV) [23].
- CU refers to the under sampling of the content domain by the use of insufficient number of cases, and to the inadequate sampling when the blueprint does not map the exam stations to the curriculum content and objectives. The blueprint of our OSCE included the content subdomains, the competencies to be assessed and patients’ characteristics.
- CIV is a systematic error introduced into the assessment data by variables unrelated to the construct being measured. CIV examples include flawed cases/checklists/rating scales, inappropriate difficulty level of the case, poorly trained standardized patients, or rater errors. The major CIV threat is due to systematic rater error. In fact, raters are a major source of measurement error, such as rater severity or leniency errors, central tendency error and halo rater effect. Therefore, upgrading training methods to improve between examiners’ agreement is essential in order to homogenize raters’ assessing skills. In addition, the provision of a detailed support material and briefings the examiners’ and SPs prior to the assessment should be systematically implemented.
이번 OSCE에서는 콘텐츠 전문가들이 세심하게 문항을 구성한 체크리스트를 만들었고, 심사관들은 숙련된 교수진으로 구성되었습니다. 또한 적절한 체크리스트/평가 척도를 사용하는 것이 중요합니다[24]. 현재 증거에 따르면 숙련된 의사가 총체적 채점 또는 글로벌 평가 척도를 사용하면 체크리스트에 비해 검사소 간 신뢰도, 구성 타당도, 동시 타당도가 더 높은 것으로 나타났습니다[25]. 글로벌 평가 척도는 판단력, 공감, 지식의 조직화, 테크니컬 스킬과 같은 영역을 평가할 때 한 가지 측면만 특별히 보는 평가 척도에 비해 검사자가 전체 과정을 평가할 수 있게 해줍니다[26, 27]. 표준 설정을 위해 BRM을 사용하는 OSCE의 경우 두 가지 유형의 체크리스트 사용은 필수입니다.
In this OSCE, content experts designed the checklists with carefully worded items and our examiners were trained faculty. Furthermore, the use of appropriate checklists/rating scales is critical [24]. Current evidence suggests that the use of holistic scoring or global rating scales by an experienced physician shows greater inter-station reliability, better construct validity, and better concurrent validity compared to checklists [25]. Global rating scales allow the examiner to rate the whole process compared to rating scales looking at one aspect alone specially when assessing areas such as judgment, empathy, organization of knowledge and technical skills [26, 27]. For OSCEs which use the BRM for establishing a standard setting, the use of the two types of checklists is mandatory.
평가를 사용하는 사람들이 결과를 신뢰할 수 있어야 하기 때문에 교육 평가에 대한 엄격한 검증은 매우 중요합니다[28]. 많은 학교에서 OSCE 시험에 미리 정해진 커트라인 점수를 사용합니다. 그러나 객관적인 방식으로 학생의 성취도에 대한 방어 가능한 기준을 설정하는 것은 특히 OSCE가 총점제인 경우 매우 중요합니다[29]. 본 연구에서는 표준 설정 방법을 도입하여 학교 정책에 따라 미리 설정된 커트라인 점수와 비교했습니다. 또한 개별 스테이션 수준과 전체 임상 평가에서 여러 심리 측정 측정을 사용하여 내부 구조 타당성 증거를 분석하여 OSCE 점수의 품질에 대한 강점과 약점을 식별할 수 있었습니다.
Rigorous validation of educational assessments is critically important because those using an assessment must be able to trust the results [28]. Many schools use a predetermined cut scores for OSCE exams. However, setting defensible standards for student performance in an objective manner is critical, in particular when the OSCE is summative [29]. In this study, we have introduced a standard setting method and compared it to the preset cut score as per our school policy. We also analyzed the internal structure validity evidence by the use of multiple psychometric measures both at the individual station level and across the complete clinical assessment which allowed us to identify strengths and weaknesses of the quality of our OSCE scores.
본 연구의 한계는 학생의 표본 크기와 OSCE 스테이션의 수입니다. 또 다른 한계는 연구 결과의 일반화 가능성입니다. 저희는 학교의 한 학습자 그룹을 대상으로 시행한 OSCE의 특정 인스턴스화의 유효성을 뒷받침하는 증거를 제공했습니다. 당연히 표본 규모가 더 크고 학교 대표성이 더 넓어지면 연구 결과에 다양한 영향을 미칠 수 있으며 추가 조사가 필요합니다. 그러나 본 연구는 점수 추론의 타당성이 다양한 품질 보증 및 표준 설정 기법의 적절한 적용에 크게 좌우되는 OSCE의 총체적 적용을 기반으로 한 몇 안 되는 연구 중 하나입니다.
A limitation to our study is the sample size of students as well as the number of OSCE stations. Another limitation is the generalizability of our results. We provided the evidence supporting the validity of a particular instantiation of an OSCE administered for one group of learners at our school. Understandably, larger sample sizes and wider school representation may have a varied impact on our results and warrants further investigation. However, our study is one of the few that was based on a summative application of an OSCE where the validity of the score inferences is largely dependent on the proper application of various quality assurance and standard setting techniques.
결론
Conclusion
OSCE는 복잡한 과정 내에서 기준 기반 평가 원칙을 사용하며 많은 학교의 평가 시스템에서 필수적인 부분을 구성합니다. OSCE 결과에 대한 심리측정 분석을 일상적으로 수행하면 시험에 대한 전반적인 관점을 확보하고 일반적인 함정을 식별하고 피할 수 있습니다.
OSCEs use criterion-based assessment principles within a complex process and constitute an integral part of the assessment system at many schools. The routine performance of a psychometric analysis on the OSCE results helps gaining an all-round view of the exam and prompts the identification and avoidance of common pitfalls.
여러 지표를 통해 결과적 및 내부 구조적 타당성 증거를 수집하는 것은 특히 요약 목적으로 사용될 때 OSCE의 품질에 대한 지지 또는 반대를 제공합니다. 이러한 분석은 주어진 테스트의 로컬 반복에 대해 정기적으로 수행되어야 하며, 그 결과는 평가의 품질을 향상시키는 데 사용됩니다.
Gathering consequential and internal structure validity evidence by multiple metrics provides support for or against the quality of an OSCE, in particular when used for a summative purpose. It is critical that this analysis be performed routinely on local iterations of given tests, and the results used to enhance the quality of assessment.
Evaluating the validity evidence of an OSCE: results from a new medical school
PMID: 30572876
PMCID: PMC6302424
DOI: 10.1186/s12909-018-1421-x
Free PMC article
Abstract
Background: To prevent the problems of traditional clinical evaluation, the "Objective Structured Clinical Examination (OSCE)" was presented by Harden as a more valid and reliable assessment instrument. However, an essential condition to guarantee a high-quality and effective OSCE is the assurance of evidence to support the validity of its scores. This study examines the psychometric properties of OSCE scores, with an emphasis on consequential and internal structure validity evidence.
Methods: Fifty-three first year medical students took part in a summative OSCE at the Lebanese American University-School of Medicine. Evidence to support consequential validity was gathered by using criterion-based standard setting methods. Internal structure validity evidence was gathered by examining various psychometric measures both at the station level and across the complete OSCE.
Results: Compared to our actual method of computing results, the introduction of standard setting resulted in lower students' average grades and a higher cut score. Across stations, Cronbach's alpha was moderately low.
Conclusion: Gathering consequential and internal structure validity evidence by multiple metrics provides support for or against the quality of an OSCE. It is critical that this analysis be performed routinely on local iterations of given tests, and the results used to enhance the quality of assessment.
Keywords: Objective structured clinical examination; Quality assurance; Validity evidence.