자연어처리와 전공의 피드백 퀄리티의 질 평가 (J Surg Educ. 2021)
Natural Language Processing and Assessment of Resident Feedback Quality
Quintin P. Solano, BS,* Laura Hayward, BS,† Zoey Chopra, BA,‡ Kathryn Quanstrom, BA,x Daniel Kendrick, MD,k Kenneth L. Abbott, MD, MS,{ Marcus Kunzmann, AB,# Samantha Ahle, MD, MHS,** Mary Schuller, MSEd,†† Erkin €Otle¸s, MSE,‡‡ and Brian C. George, MD, MAEdxx

소개
INTRODUCTION
효과적인 학습을 위해서는 성과 피드백이 필요합니다. 외과에서 피드백은 기술적 술기와 비기술적 술기의 개발을 모두 지원합니다.1, 2, 3, 4, 5, 6 이러한 이유로 레지던트에게 성과 피드백을 제공하는 것은 미국의학전문대학원교육인증위원회(ACGME)의 핵심 프로그램 요건입니다.7 이러한 요구를 해결하기 위해 새로운 작업장 기반 평가 도구는 교수진이 수련의에게 지시된dictated 피드백을 제공할 수 있는 메커니즘을 제공합니다.8, 9, 10 이로 인해 외과 수련의에게 제공되는 피드백의 양이 더 많아졌습니다.8,11 학습에는 피드백의 양도 중요하지만 피드백의 질이 가장 중요합니다.12, 13, 14 이러한 맥락에서 교육 프로그램은 교수진이 이러한 새로운 도구를 사용하여 수련의에게 필요한 고품질 피드백을 제공하도록 보장해야 합니다. 그러나 수행 피드백의 품질을 특성화하는 현재의 접근 방식은 노동력과 리소스 집약적이며, 평가자가 데이터 세트의 각 피드백을 개별적으로 평가해야 하는 경우가 많습니다.10,15
Performance feedback is necessary for effective learning. In surgery, feedback supports the development of both technical and non-technical skills.1, 2, 3, 4, 5, 6 For this reason, providing residents with performance feedback is an Accreditation Council for Graduate Medical Education (ACGME) core program requirement.7 To address this need, new workplace-based assessment tools provide a mechanism for faculty to provide trainees with dictated feedback.8, 9, 10 This in turn has led to greater volume of feedback provided to surgical trainees.8,11 While the quantity of feedback is important for learning, it is the quality of feedback matters most.12, 13, 14 Within that context, training programs must ensure that faculty use these new tools to provide the high-quality feedback that trainees need. However, current approaches to characterizing the quality of performance feedback are labor and resource intensive, often requiring raters to individually evaluate each piece of feedback in a dataset.10,15
일련의 기계 학습 방법인 자연어 처리(NLP)는 이 문제에 대한 자동화된 솔루션을 제공할 수 있습니다. 이전의 파일럿 연구에서는 SIMPL(Society for Improving Medical Professional Learning) 스마트폰 애플리케이션(매사추세츠주 보스턴)의 내러티브 데이터에 적용된 다양한 NLP 모델을 비교했습니다.8 이 연구에서는 소량의 수술 수련생 피드백 샘플의 피드백 기록 품질을 가장 정확하게 분류하는 NLP 모델 유형을 확인했습니다.16 초기 결과는 유망했지만 데이터 세트의 크기로 인해 성능 평가가 제한적이었습니다. 따라서 NLP 도구를 사용하여 피드백 품질을 자동으로 평가할 때 기대할 수 있는 성능은 알 수 없습니다.
Natural language processing (NLP), a set of machine learning methods, may offer an automated solution to this problem. A previous pilot study compared different NLP models applied to narrative data from the Society for Improving Medical Professional Learning (SIMPL) smartphone application (Boston, MA).8 That study identified which type of NLP model most accurately classified the quality of feedback transcripts of a small sample of surgical trainee feedback.16 While the initial results were promising, performance assessment was limited by the size of the dataset. Therefore, the expected performance of utilizing NLP tools to automatically assess feedback quality is unknown.
이 연구의 주요 목표는 수술 수련생에게 제공되는 피드백의 품질을 특성화하기 위해 NLP 모델의 성능을 평가하는 것이었습니다. 이를 위해 훨씬 더 큰 데이터 세트를 사용했습니다. 코딩된 트랜스크립트 세트를 사용하여 NLP 모델을 학습시킨 후 테스트를 거쳐 성능을 분석했습니다.
The primary aim of this study was to assess the performance of an NLP model to characterize the quality of feedback provided to surgical trainees. To do this we use a much larger dataset. The NLP model was trained using a set of coded transcripts, subsequently tested, and then analyzed for performance.
자료 및 방법
MATERIALS AND METHODS
연구 모집단
Study Population
2019년 8월에 기록된 단일 학술 외과 레지던트 프로그램에서 수술 성과 피드백을 받아쓰기한 간단한 성적표를 수집했습니다. 미시간대학교 기관윤리심의위원회는 이 연구가 심의 면제 대상이라고 판단했습니다.
We collected SIMPL transcripts of dictated operative performance feedback from a single academic surgical residency program, all recorded in August 2019. The University of Michigan institutional review board deemed this study exempt from review.
데이터 수집
Data Collection
외과 레지던트의 수술 중 성과에 대한 수술 후 평가를 용이하게 하기 위해 개발된 SIMPL 스마트폰 앱을 사용하여 받아쓰기 피드백을 수집했습니다. 피드백은 구글 클라우드 음성-텍스트 변환기(캘리포니아주 마운틴뷰)를 통해 전사하고 연구 코디네이터가 비식별화한 다음 품질을 위해 코딩했습니다.
Dictated feedback was collected using the SIMPL smartphone app, which was developed to facilitate post-operative evaluation of surgical residents’ intra-operative performance. Feedback was transcribed via Google Cloud Speech-to-Text (Mountain View, CA), de-identified by a study coordinator, and then coded for quality.
품질 평가
Quality Assessment
모든 성적표는 각각 2명의 코더로 구성된 두 개의 별도 팀에서 평가했습니다. 코더들은 이전 연구에서 외과의가 코딩한 '워밍업 성적표' 세트에 대한 교육을 받은 의대생이었습니다.15 코더들의 코딩을 전문가 평가와 비교하고 불일치하는 부분을 논의하여 평가자의 정확성을 개선했습니다. 성적표는 500단계로 평가되었습니다. 모든 단계가 끝나고 다음 단계가 시작되기 전에 코딩 불일치를 확인하고 각 코더 팀이 모여 코딩 결정을 논의하고 다음 단계의 코딩 스키마를 개선했습니다. 훈련 및 연구 데이터 세트를 코딩하는 동안 성적표의 텍스트 의미에 대한 의문이 생기면 저자 DK와 BG에게 문의하여 명확히 설명했습니다. 불일치하는 코드가 있을 때마다 각 팀은 각 녹취록에 대해 단일 품질 코드에 합의했습니다. 그런 다음 이 최종 코드를 사용하여 NLP 모델을 훈련했습니다.
All transcripts were evaluated by two separate teams with 2 coders each. The coders were medical students who were trained on a set of “warm-up transcripts” coded by surgeons in a previous study.15 Their codes were then compared to expert ratings and discrepancies were discussed to improve rater accuracy. Transcripts were assessed in phases of 500. After every phase and prior to initiation of any subsequent phase, coding discrepancies were identified, and each coder team met to discuss their coding decisions and refine coding schema for subsequent phases. During coding of the training and study data sets, authors DK and BG were consulted for clarification when questions arose about the meaning of text in the transcripts. For each discordant code, each team reached consensus on a single quality code for each transcript. These final codes were then used to train the NLP model.
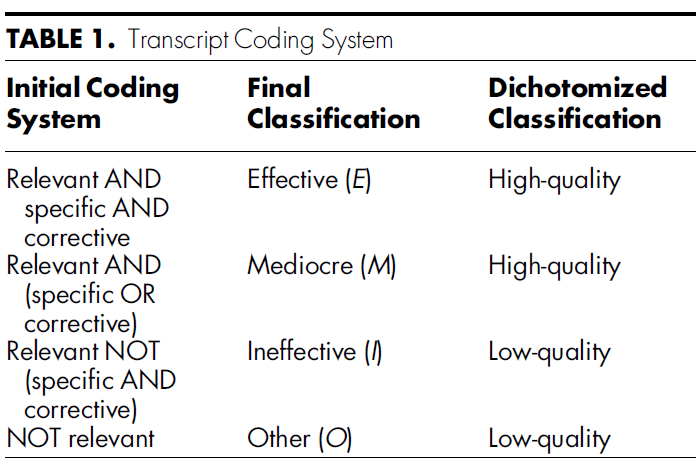
코더들은 Ahle 외15가 설명한 방법에 따라 피드백을 분류했으며, 처음에는 녹취록을 '관련성' 여부로 분류했습니다. 녹취록이 "관련성"으로 코딩된 경우, 후속 코딩에서는 해당 녹취록을 "구체적", "교정적", 둘 다 또는 둘 다 아닌 것으로 할당했습니다. 이러한 이진 속성은 훈련된 각 평가자가 평가했습니다. 각 성적표에 대한 코딩은 문장 수준에서 이루어졌으며, 성적표 내의 어떤 문장이 '관련성', '구체적' 및/또는 '교정적'에 해당하면 전체 성적표가 그렇게 코딩됩니다.
Coders classified the feedback following the methods described by Ahle et al15, with an initial classification of the transcripts as “relevant” or not. If a transcript was coded as “relevant”, subsequent coding would assign the transcript as being “specific”, “corrective”, both, or neither. These binary attributes were assessed by each trained rater. Coding for each transcript occurred at the sentence level; if any sentence within a transcript qualified as “relevant”, “specific”, and/or “corrective”, the entire transcript would be coded as such.
- '구체적'과 '교정적'으로 모두 평가된 성적표는 효과적(E)으로,
- 구체적이거나 교정적이지만 둘 다는 아닌 성적표는 보통(M)으로,
- 관련성이 있지만 구체적이지도 교정적이지도 않은 성적표는 비효과적(I)으로 분류했습니다.
- 관련성이 없는 것으로 평가된 성적표는 기타(O)로 분류되었습니다.
이러한 코드는 특정 분석을 위해 다시 이분화되어 E 또는 M으로 평가된 성적표는 높은 품질로, I 또는 O로 평가된 성적표는 낮은 품질로 분류되었습니다(표 1).
- Transcripts rated as both “specific” and “corrective” were classified as effective (E);
- transcripts rated as specific or corrective but not both were classified as mediocre (M);
- transcripts rated as relevant but neither specific nor corrective were classified as ineffective (I).
- Transcripts not rated as relevant were classified as other (O).
These codes were further dichotomized for specific analyses, with transcripts rated as E or M classified as high quality, and transcripts rated as I or O classified as low quality (Table 1).
통계 분석
Statistical Analysis
NLP 모델은 Python17 프로그래밍 언어와 SKLearn18, Pandas19, Numpy20 프레임워크의 도움을 받아 구축되었습니다. 트랜스크립트는 길이 1에서 5까지 다양한 n-그램 크기의 백 오브 워드 벡터21로 사전 처리되었습니다. 데이터는 훈련 세트와 테스트 세트로 무작위로 분할(75%/25%)되었습니다.
NLP models were constructed using the Python17 programming language with the aid of the SKLearn18, Pandas19, and Numpy20 frameworks. Transcripts were pre-processed into bag-of-word vectors21 with varying n-gram sizes, ranging from length 1 to 5. The data was randomly split (75%/25%) into a training set and a testing set.
로지스틱 회귀 모델은 파일럿 연구 결과를 바탕으로 선택되었습니다.17 모델 하이퍼파라미터와 파이프라인 파라미터(예: n-그램 크기)는 훈련 세트에서 5배 교차 검증 그리드 검색을 사용하여 평가되었습니다. 최적의 파라미터가 발견되면 전체 훈련 세트에서 모델을 훈련하고 테스트 세트에서 평가했습니다.
Logistic regression models were chosen based on results from a pilot study.17 Model hyperparameters and pipeline parameters (e.g. n-gram size) were assessed using a 5-fold cross-validation grid search on the training set. Once the best parameters were found, the models were trained on the full training set and evaluated on the testing set.
주요 결과는 개별 및 이분화된 코딩 시스템 모두의 예측 정확도였습니다. 개별 클래스(E, M, I, O) 성능 등급은 클래스 가중치 메트릭(즉, 마이크로 가중치)을 사용하여 계산되었습니다. 2차 결과는 민감도, 특이도, 부정 및 양성 예측값, NLP 모델의 수신기 작동 특성 곡선(AUROC) 아래 영역이었습니다. 신뢰 구간은 부트스트랩 샘플링을 사용하여 추정했습니다. 테스트 데이터 세트는 성능 메트릭의 부트스트랩 샘플을 생성하기 위해 1,000회 교체하여 다시 샘플링되었습니다. 이 부트스트랩 분석을 통해 성적표 품질 레이블의 분포와 관련하여 예측 모델의 정확도 변화와 다른 성능 측정값을 추정할 수 있었습니다.
The primary outcomes were the predictive accuracies of both the individual, and dichotomized coding systems. The individual class (E, M, I, O) performance ratings were calculated using class weighted metrics (i.e., micro weighting). Secondary outcomes were sensitivity, specificity, and negative and positive predictive values, and area under the receiver operating characteristic curve (AUROC) of the NLP model. Confidence intervals were estimated using bootstrap sampling. The test dataset was resampled with replacement 1,000 times to generate bootstrap samples of the performance metrics. This bootstrap analysis enabled estimation of the predictive model's variation in accuracy, and the other performance measures, in relation to the distribution of transcript quality labels.
결과
RESULTS
총 2,416개의 트랜스크립트가 품질 코딩되었으며 표 2에 설명되어 있습니다. 전체적으로 1,014개(42%)가 효과적(E)으로 코딩되었고 1,811개(75%)의 성적표가 높은 품질(E, M)로 코딩되었습니다. 고품질 및 저품질 피드백의 예는 표 3에 나와 있습니다.
A total of 2,416 transcripts were coded for quality and are described in Table 2. Overall, 1,014 (42%) were coded as Effective (E) and 1,811 (75%) of the transcripts were high quality (E, M). Examples of high quality and low-quality feedback are shown in Table 3.


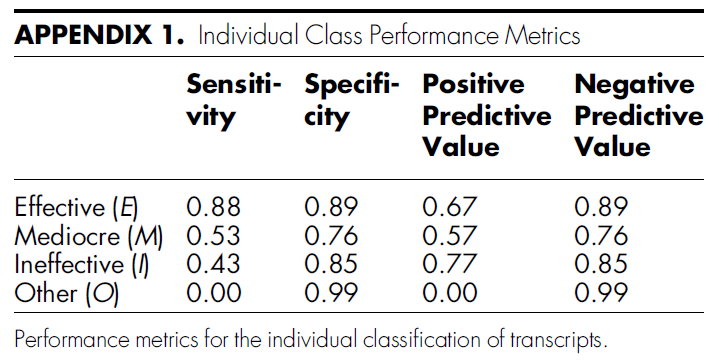
개별 피드백을 E, M, I 또는 O로 평가할 때 모델의 정확도는 0.65(95% 신뢰 구간: 0.61, 0.65)였으며, 민감도는 0.46(0.43, 0.49), 특이도는 0.87(0.86, 0.89), 양성 예측값은 0.50(0.48, 0.53), 음성 예측값은 0.87(0.86-0.89)로 나타났습니다. 개별 클래스 성능 지표는 부록 표 1에 나와 있습니다.
The accuracy of the model when rating individual pieces of feedback as E, M, I, or O was 0.65 (95% confidence interval: 0.61, 0.65), with sensitivity of 0.46 (0.43, 0.49), specificity of 0.87 (0.86, 0.89), positive predictive value of 0.50 (0.48, 0.53), and negative predictive value of 0.87 (0.86-0.89). Individual class performance metrics are presented in Appendix Table 1.
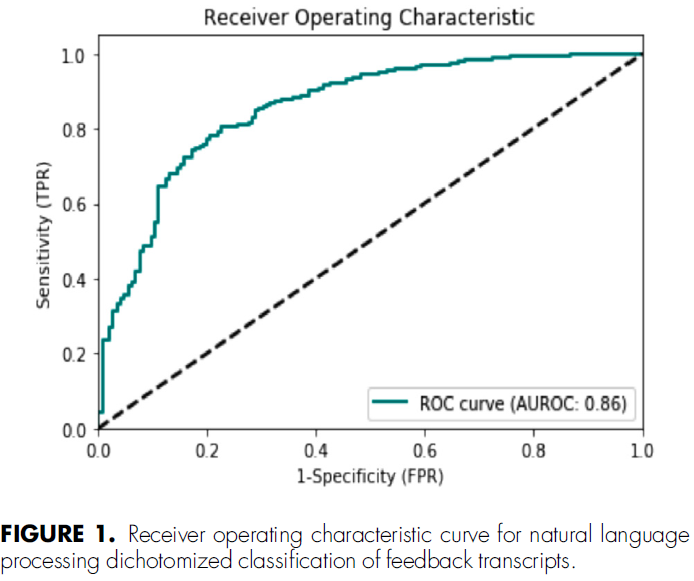
등급을 이분화했을 때(높은 품질과 낮은 품질), 낮은 품질의 피드백을 분류하는 모델 정확도는 0.83(0.80, 0.86), 민감도 0.37(0.33, 0.45), 특이도 0.97(0. 96, 0.98), 양의 예측값 0.80(0.74, 0.85), 음의 예측값 0.83(0.80, 0.85), 수신기 작동 특성 곡선 아래 면적 0.86(0.83, 0.87, 그림 1)으로 나타났습니다.
When ratings were dichotomized (high vs. low quality), the model accuracy for classifying low quality feedback was 0.83 (0.80, 0.86), with sensitivity of 0.37 (0.33, 0.45), specificity of 0.97 (0.96, 0.98), positive predictive value of 0.80 (0.74, 0.85), negative predictive value of 0.83 (0.80, 0.85), and area under the receiver operating characteristic curve of 0.86 (0.83, 0.87; Fig. 1).
토론
DISCUSSION
우리는 수술 수련생에게 제공되는 피드백의 품질을 특성화하는 임무를 맡은 NLP 모델의 성능 특성을 조사했습니다. NLP 모델은 높은 정확도와 특이도로 피드백 품질을 분류할 수 있습니다. 그러나 민감도는 훨씬 낮았는데, 이는 알고리즘이 낮은 품질의 피드백을 가장 안정적으로 식별할 수 있음을 나타냅니다. 이 보고서에서 설명한 NLP 모델은 수술 훈련 프로그램에서 피드백 개입의 효과를 측정하는 데 유용할 수 있습니다.
We investigated the performance characteristics of NLP models tasked with characterizing the quality of feedback provided to surgical trainees. NLP models can classify feedback quality with high accuracy and specificity. However, sensitivity was much lower, indicating that the algorithm can most reliably identify low quality feedback. The NLP model described in this report may be useful for measuring the effects of feedback interventions in surgical training programs.
이 연구는 NLP의 기능을 조사한 이전 파일럿 연구의 결과를 검증하지만, 이 연구에서는 이 기술이 더 큰 규모로 사용될 수 있기를 바라며 분류 성능을 더욱 개선하기 위해 더 큰 표본 크기를 활용했습니다.16 이 연구의 모델 지표는 의과 교육 환경 밖의 NLP 연구에서 나온 지표와 비슷합니다.22, 23, 24 라마찬드란 등은 NLP를 활용하여 연구 검토의 품질을 자동으로 평가하고 0.32-0.67의 정확도를 보고했습니다.22 우리 모델은 비교적 높은 정확도를 달성했으며, 이는 의학교육 맥락에서 향후 피드백 품질 개선을 위한 NLP의 잠재력을 강조합니다.
This study validates the results of a previous pilot study examining the capabilities of NLP, however, in this study we utilized a larger sample size to further improve classification performance in the hope that this technology might be used on a larger scale.16 Model metrics from this study are comparable to those from studies of NLP outside medical education settings.22, 23, 24 Ramachandran et al. utilized NLP to automatically assess the quality of research reviews and reported accuracies of 0.32-0.67.22 Our model achieved relatively high accuracy, and this highlights the potential of NLP for future feedback quality improvement in a medical education context.
NLP 모델은 피드백을 측정하고 개선하는 데 도움이 되는 새로운 도구가 될 수 있습니다. 효과적인 고품질 피드백 제공의 중요성은 분명하지만 피드백 품질을 측정하는 데는 리소스 집약적입니다.15,25 NLP 모델은 거의 실시간으로 피드백 품질을 자동으로 특성화하여 이러한 부담을 줄일 수 있습니다. 외과 레지던트 프로그램은 자동화된 피드백 품질 특성화를 사용하여 레지던트들이 받는 피드백을 개선할 수 있습니다. 예를 들어, 지속적으로 낮은 품질의 피드백을 제공하는 교수진에게는 추가적인 교수진 개발 리소스를 제공할 수 있습니다. 또한, 자동화된 피드백 분류는 피드백 개선을 위한 새로운 아이디어를 개발 및 테스트하고 피드백 품질 개선을 위한 기존 방법 구현의 영향을 평가하는 데 사용될 수 있습니다.9,26,27
NLP models may be a novel tool to both measure and help improve feedback. The importance of providing effective, high quality feedback is clear, yet the measurement of feedback quality is resource intensive.15,25 NLP models can reduce this burden by automatically characterizing feedback quality in near real time. Surgical residency programs could use automated characterizations of feedback quality to improve the feedback their residents receive. For example, faculty who consistently provide low quality feedback might be provided with additional faculty development resources. Furthermore, automated feedback classification might be used to develop and test new ideas for improving feedback, and to assess the impact of implementing existing methods for improving feedback quality.9,26,27
본 접근법은 일반외과 레지던트 프로그램 내에서 시범적으로 시행되었지만 다른 수술 전문과목에도 일반화할 수 있을 것으로 보입니다. 비수술 전문과목의 수련의에게 제공되는 피드백은 용어와 어휘가 다를 수 있지만, 이러한 환경에서 사용할 수 있는 NLP 모델을 개발하는 데 본 방법을 사용할 수 있습니다.
Our approach, while piloted within a general surgery residency program, is likely generalizable to other procedural specialties. Although, the feedback provided to trainees in non-procedural specialties likely features different terminology and verbiage, our methods could be used to develop NLP models for use in such settings.
이 연구에는 한계가 있습니다.
- 첫째, 우리가 분석한 모든 피드백은 단일 교육 기관에서 SIMPL을 통해 수집한 것으로, 다른 환경이나 다른 도구로 전달된 피드백을 대표하지 못할 수 있습니다.
- 둘째, 피드백 품질을 평가한 의대생은 제한된 경험으로 인해 일부 기록을 잘못 코딩했을 수 있지만, 이전에 코딩된 기록에 대한 교육과 실습 외과의와의 빈번한 상담을 통해 이를 완화하려고 노력했습니다. 일부 모범적이고 어려운 대본은 실습 외과의와 논의했지만, 코딩된 대본의 대부분은 외과의의 감수를 거치지 않았습니다.
- 셋째, 오디오 피드백의 대본에는 때때로 의미와 관련하여 합리적 추측을 필요로 하는 전사 오류가 포함되어 있으며, 이러한 추측 중 일부는 잘못된 것일 수 있습니다.
- 마지막으로 나이, 인종, 성별, 억양과 같은 요인이 전사 품질과 내용에 영향을 미칠 수 있으므로 이러한 모델을 구현할 때는 NLP 모델 출력에서 관련 편견의 위험성을 염두에 두어야 합니다.
이러한 한계에도 불구하고 이 보고서는 잠재적 유용성을 강조하고 의학교육에서 NLP 연구를 위한 벤치마크를 제공합니다.
This study has limitations.
- First, all the feedback we analyzed was collected via SIMPL at a single academic institution and may not be representative of feedback delivered in other settings or with other tools.
- Second, the raters of feedback quality were medical students who, due to limited experience, may have miscoded some transcripts, though we attempted to mitigate this via training with previously coded transcripts and frequent consultations with practicing surgeons. Although some exemplar and difficult transcripts were discussed with the practicing surgeons, the majority of the coded transcripts were not audited by them.
- Third, transcripts of audio feedback sometimes contained transcription errors requiring reasoned guesses concerning meaning, and some of these guesses may have been incorrect.
- Finally, factors like age, race, gender, and accents may impact transcription quality and content, when moving to implement these models we must be mindful of the risk of related biases in NLP model output.
Notwithstanding these limitations, this report highlights the potential utility and provides a benchmark for the study of NLP in medical education.
결론
CONCLUSIONS
NLP 모델은 높은 정확도와 특이도, 적당한 민감도로 수술 성과 피드백 품질을 분류할 수 있습니다. NLP는 피드백 품질을 자동으로 분류하는 데 효과적인 접근 방식이 될 수 있습니다. 이러한 정보는 궁극적으로 피드백을 개선하고 수술 수련의의 학습을 가속화하는 데 사용될 수 있습니다.
An NLP model is able to classify operative performance feedback quality with high accuracy and specificity and modest sensitivity. NLP could serve as effective approach for automated classification of feedback quality. That information can ultimately be used to improve feedback and in turn accelerate learning for surgical trainees.
Natural Language Processing and Assessment of Resident Feedback Quality
PMID: 34167908
Abstract
Objective: To validate the performance of a natural language processing (NLP) model in characterizing the quality of feedback provided to surgical trainees.
Design: Narrative surgical resident feedback transcripts were collected from a large academic institution and classified for quality by trained coders. 75% of classified transcripts were used to train a logistic regression NLP model and 25% were used for testing the model. The NLP model was trained by uploading classified transcripts and tested using unclassified transcripts. The model then classified those transcripts into dichotomized high- and low- quality ratings. Model performance was primarily assessed in terms of accuracy and secondary performance measures including sensitivity, specificity, and area under the receiver operating characteristic curve (AUROC).
Setting: A surgical residency program based in a large academic medical center.
Participants: All surgical residents who received feedback via the Society for Improving Medical Professional Learning smartphone application (SIMPL, Boston, MA) in August 2019.
Results: The model classified the quality (high vs. low) of 2,416 narrative feedback transcripts with an accuracy of 0.83 (95% confidence interval: 0.80, 0.86), sensitivity of 0.37 (0.33, 0.45), specificity of 0.97 (0.96, 0.98), and an area under the receiver operating characteristic curve of 0.86 (0.83, 0.87).
Conclusions: The NLP model classified the quality of operative performance feedback with high accuracy and specificity. NLP offers residency programs the opportunity to efficiently measure feedback quality. This information can be used for feedback improvement efforts and ultimately, the education of surgical trainees.
Keywords: Medical Knowledge; Practice-Based Learning and Improvement; feedback; machine learning; medical education; natural language processing.
Copyright © 2021 Association of Program Directors in Surgery. All rights reserved.
'Articles (Medical Education) > 교수법 (소그룹, TBL, PBL 등)' 카테고리의 다른 글
| 임상 카데바의 라이프사이클: 실천-기반 민족지학(Teach Learn Med, 2022) (0) | 2023.08.19 |
|---|---|
| 프로젝트 기반 학습과 연구 기반 학습(Higher Education Faculty Career Orientation and Advancement, Ch 8) (0) | 2023.08.04 |
| 머신러닝을 활용하여 전공의 수행능력에 대한 주치의 피드백 평가하기 (Anesth Analg. 2021) (0) | 2023.07.16 |
| 인지과학의 인사이트를 임상 술기 교육에 사용하기: AMEE Guide No. 155 (Med Teach, 2023) (0) | 2023.07.04 |
| 보건의료전문직 교육에서 학생참여: AMEE Guide No. 152 (Med Teach, 2022) (0) | 2023.07.02 |