키워드 특이적 알고리듬으로 발전 문제가 있는 전공의 찾아내기 (J Grad Med Educ. 2019)
Detection of Residents With Progress Issues Using a Keyword–Specific Algorithm
Gaby Tremblay, MSc Pierre-Hugues Carmichael, MSc Jean Maziade, MD, FCMF, CCMF, MSc Mireille Gre´goire, MDCM, FRCPSC
소개
Introduction
전공의 수련 과정에 등록한 레지던트 중 학습에 어려움을 겪는 레지던트를 조기에 발견하는 것은 지속적인 과제입니다. 여러 연구에서 레지던트의 4.3%에서 9.1%가 수련 중 어려움을 겪는 것으로 나타났습니다.1,2 레지던트의 학습 어려움은 수련 후반에 확인되는 경우가 많으며,3 평가자가 수련 중 평가 보고서(ITER)에 "어려움" 또는 "실패"를 표시하거나 다른 로테이션 종료 평가 양식에 "실패"를 지정하는 것을 꺼리는 경우가 많기 때문입니다.4,5 그러나 ITER와 같은 순환 평가에서 서술의 길이와 모호하거나 부정적인 의견의 비율은 레지던트 교정의 잠재적 필요성을 나타냅니다.3,6 수련생 평가에서 서술적 의견은 가치가 있는 것으로 나타났으며,7,8 학습자의 역량 달성을 향한 진행 상황을 판단할 때 고려해야 합니다.9-11
Early identification of a resident with progress difficulties who is enrolled in postgraduate medical training is an ongoing challenge. In various studies, between 4.3% and 9.1% of residents show evidence of struggling during training.1,2 The learning difficulties of residents are frequently identified late in their training,3 as assessors are often reluctant to mark “in difficulty” or “failure” on in-training evaluation reports (ITERs), or to designate “fail” on other end-of-rotation assessment forms.4,5 However, the length of narratives and percentage of ambiguous or negative comments on rotation assessments, such as ITERs, indicate a potential need for resident remediation.3,6 Narrative comments in assessing trainees have been shown to be valuable,7,8 and must be taken into account when determining learners' progress toward achieving competencies.9–11
언어 분석 도구가 교육에 적용되고 있지만, 의학교육에서의 언어 분석에 관한 논문은 거의 발표되지 않았으며, 학부생에 초점을 맞춘 경향이 있다.12 역량 기반 의학교육의 일환으로 제공되는 모든 서술 정보를 처리하기 위해, 우리는 특정 키워드를 기반으로 진도에 문제가 있는 전공의를 감지할 수 있는 알고리즘으로 구성된 새로운 컴퓨터 의미 분석을 개발하고자 했다.
Although the tools of language analytics have been applied in education, very few articles concerning language analytics in medical education have been published, and those that have tend to focus on undergraduate students.12 In order to handle all the narrative information becoming available as part of competency-based medical education, we sought to develop a novel computerized semantic analysis, which consists of an algorithm that is able to detect residents with progress issues, based on certain keywords.
방법
Methods
2001년부터 2013년까지 라발대학의 공인 프로그램에서 수련을 받은 모든 레지던트의 모든 ITER(사전 설정된 목표 달성 여부, 해당 서술, 전체 점수[합격/불합격] 및 일반적 의견을 나타내는 양식)가 포함된 데이터베이스를 추출하고 익명화하여 기록에 대한 기밀성을 보장했습니다. 이 연구에서 다루는 기간 동안 가정의학과에서 사용된 ITER 형식이 다른 레지던트 프로그램과 크게 달랐기 때문에 ITER는 가정의학과 또는 캐나다 왕립 의사 및 외과의 대학(RCPSC) 프로그램(온라인 보충 자료로 제공됨)으로 구분되었습니다. 데이터베이스에는 프로그램 이름, 레지던트 레벨, 로테이션 블록 번호, 레지던트 시작일과 종료일, 레지던트 근무지, CanMEDS 역할 평가(등급 및 코멘트), 전체 로테이션 평가(코멘트), 수련 기간 중 결근 일수 등이 포함되었습니다. 일반적으로 ITER는 로테이션 완료 후 30일 이내에 참석 교수진에 의해 완료되었습니다.
A database containing all ITERs (forms indicating whether preset objectives are met, corresponding narratives, overall score [pass/in difficulty/fail], and general comments) from all residents training in accredited programs at Université Laval between 2001 and 2013 was extracted and anonymized to ensure confidentiality of their track records. The ITERs were split into either family medicine or Royal College of Physicians and Surgeons of Canada (RCPSC) programs (provided as online supplemental material), as the ITER format used in family medicine for the period covered in this study differed significantly from that of other residency programs. The databases included
- the name of the program,
- residency level,
- rotation block number,
- residency beginning and end dates,
- residency site,
- CanMEDS13 role assessments (ratings and comments),
- overall rotation evaluation (comments), and
- number of days of absence during the training period.
In general, ITERs were completed by attending faculty within 30 days of rotation completion.
각 데이터베이스에 대해 "어려움"(즉, 고군분투 중) 또는 "실패" 등급을 받은 것으로 정의되는 진도 문제가 있는 레지던트를 식별했습니다. 연구 목적을 위해 특정 레지던트의 모든 ITER는 "실패" 또는 "어려움 중"이라는 언급이 있는 양식이 나타날 때까지 보관되었습니다. 진행 문제가 확인된 ITER 이후의 모든 ITER는 폐기되었습니다.
For each database we identified residents with progress issues, defined as having an ITER either rated “in difficulty” (ie, struggling) or “fail.” For the purposes of the study, all ITERs from a given resident were kept until a form with the mention “failure” or “in difficulty” appeared. All ITERs following an ITER with identified progress issues were discarded.
교육 설계자는 프랑스어로 작성된 모든 ITER를 검토하고 긍정적 피드백 및 성능 저하와 관련된 용어를 제안했습니다. 용어는 전반적 퍼포먼스 설명 섹션에 입력된 133,216개의 단어와 ITER의 각 CanMEDS 역할에 대한 서술 섹션에 입력된 84,365개의 단어에서 결정되었습니다. 데이터베이스의 전반부는 긍정 및 부정 키워드 목록을 만드는 데 사용되었으며, 이 목록은 데이터베이스의 후반부와 일관성을 확인했습니다. 이중 의미(긍정 또는 부정)를 가질 수 있는 프랑스어 단어와 접속사는 삭제되었습니다. 이 목록의 실질적인 중요성은 의학전문대학원 부학장과 비의료인인 의학부 구성원이 확인했습니다. 이러한 키워드 목록과 영어 번역본은 온라인 보충 자료로 제공됩니다.
An instructional designer reviewed all ITERs written in French and proposed terms associated with positive feedback and underperformance. Terms were determined from 133 216 words entered in the overall performance comments section and 84 365 words entered in the narrative section of each CanMEDS role of the ITERs. The first half of the database was used to make a list of positive and negative keywords that was checked for consistency against the second half of the database. French words that could have a dual meaning (either positive or negative) and conjunctions were discarded. The practical significance of this list was confirmed by the associate dean of postgraduate medical education and by a nonmedical member of the faculty of medicine. The list of these keywords with an English translation is provided as online supplemental material.
이러한 키워드를 기반으로 한 분류 규칙은 분류 및 회귀 트리 방법을 사용하여 재귀적 분할을 통해 구성되었습니다.14 이 방법론은 변수와 컷오프 값을 자동으로 선택할 수 있는 유연성과 비교적 간단한 분류 규칙을 생성할 수 있는 능력 때문에 선호되었습니다. 기술적 방법론에 대한 자세한 내용은 온라인 보충 자료로 제공됩니다. 분류 및 회귀 트리 알고리즘은 가정의학과 및 전문 프로그램 데이터 세트에 독립적으로 적용되었으며, 100%에 가까운 민감도(실제 양성으로 정확하게 식별되는 비율)와 최대 특이도(실제 음성으로 정확하게 식별되는 비율)를 가진 규칙을 얻는 것을 목표로 조정되었습니다. 도출된 각 분류 규칙에 대해 민감도, 특이도, 양성 및 음성 예측값(각각 실제 양성 및 실제 음성 비율)을 계산했습니다. 알고리즘은 키워드와 동시에 또는 그 이후 언제든지 "실패" 또는 "어려움"이라는 엄격한 기준과 전체 점수를 비교했습니다. 각 데이터 세트에 대해 얻은 최종 규칙의 데이터만 제시합니다. 어려움을 겪는 전공의의 유병률이 낮았기 때문에 성능 변동성이 증가하지 않도록 데이터 세트를 훈련 세트와 테스트 세트로 나누지 않았습니다.15
A classification rule based on these keywords was constructed by recursive partitioning using classification and regression tree methods.14 This methodology was preferred due to its flexibility in automatically selecting variables and cutoff values and its ability to produce relatively simple classification rules. Technical methodologic details are presented as online supplemental material. The classification and regression tree algorithm was applied independently to the family medicine and specialized programs data sets and tuned with the aim of obtaining rules with near 100% sensitivity (proportion of actual positives correctly identified as such) and maximal specificity (proportion of actual negatives correctly identified as such). Sensitivity, specificity, and positive and negative predictive values (proportion of true positives and true negatives, respectively) were computed for each derived classification rule. The algorithm was compared to the stringent standard of “fail” or “in difficulty” overall score, either concurrent to the keyword or anytime thereafter. We present only data of the final rules obtained for each data set. Due to the low prevalence of struggling residents, data sets were not split into training and testing sets to avoid increasing performance variability.15
라발 대학교 윤리위원회는 이 프로젝트의 심의를 면제했습니다.
The Université Laval Ethics Board exempted this project from review.
통계 분석은 R 3.2.3(오스트리아 비엔나, 비엔나 통계 컴퓨팅 재단)을 사용하여 수행되었습니다.
Statistical analyses were carried out with R 3.2.3 (R Foundation for Statistical Computing, Vienna, Austria).
결과
Results
등록된 3292명의 전공의에 대한 총 4만1618개의 ITER가 있었습니다. RCPSC 데이터베이스에는 2002년 5월부터 2013년 11월까지 라발대학의 36개 공인 프로그램에서 수련을 받은 2163명(여성 60%)의 ITER 3073건이 포함되어 있습니다. 가정의학 데이터베이스는 2001년 8월부터 2013년 9월까지 1129명의 레지던트(여성 73%)가 수련한 11,545명의 ITER로 구성되었습니다. 현재 50개의 농촌 및 도시, 대학 기반 공인 수련 프로그램에 910명의 레지던트가 등록되어 있습니다.
There was a total of 41 618 ITERs for the 3292 registered residents. The RCPSC database contained 30 073 ITERs from 2163 residents (60% female) training in 36 accredited programs at Université Laval between May 2002 and November 2013. The family medicine database was composed of 11 545 ITERs from 1129 residents (73% female) training between August 2001 and September 2013. There are currently 910 residents registered in the 50 rural and urban, university-based accredited training programs.
표 1은 RCPSC 레지던트 프로그램에 등록한 레지던트를 분류할 때 선택한 규칙의 성능을 보여줍니다. 이 분류 규칙은 100%의 민감도를 달성하는 동시에 87.7%의 특이도를 최대화합니다. 이 특정 그룹에서는 2163명의 레지던트 중 78명(4%)에서 진행 문제가 확인되었습니다. 분류 트리는 이러한 전공의를 진행 문제가 있는 것으로 정확하게 분류했습니다. 그러나 분류 트리는 난이도 또는 실패를 나타내는 전체 점수는 없었지만, 256명의 전공의를 진행 문제가 있는 것으로 식별하여 23.4%의 양의 예측값을 얻었습니다.
Table 1 presents the performance of the chosen rule when classifying residents enrolled in an RCPSC residency program. This classification rule achieves 100% sensitivity while maximizing specificity at 87.7%. In this particular group, progress issues were identified in 78 of the 2163 residents (4%). The classification tree correctly classified these residents as having progress issues. However, the classification tree identified 256 residents as having progress issues, although they did not have an overall score indicating difficulty or failure, resulting in a positive predictive value of 23.4%.
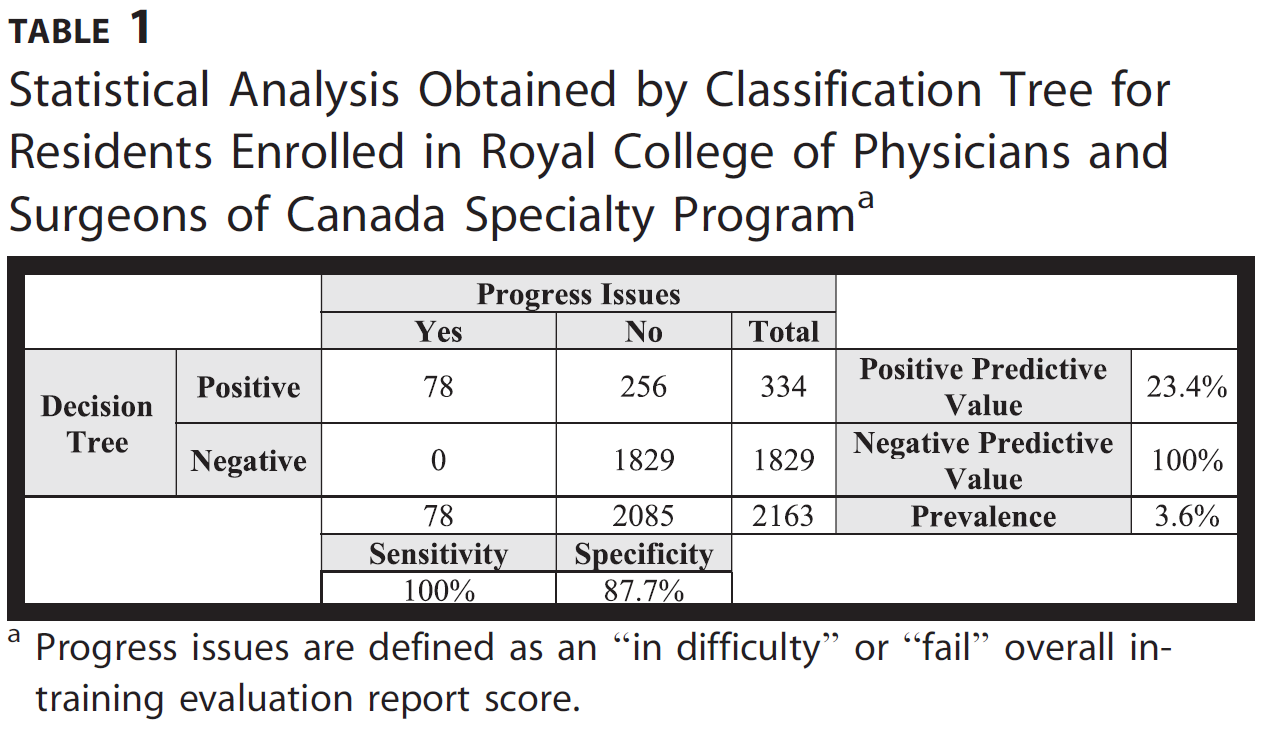
표 2는 가정의학과 프로그램에 등록한 레지던트를 분류할 때 선택한 분류 규칙의 성능을 보여줍니다. 이 분류 규칙은 민감도 100%를 달성하는 동시에 특이도는 79.2%로 최대화했습니다. 이 그룹에서는 1129명의 레지던트 중 67명(6%)에서 진행 문제가 확인되었습니다. 분류 규칙은 이러한 레지던트를 정확하게 식별했지만, 난이도 또는 실패를 나타내는 전체 점수는 없었지만 221명의 레지던트를 진행 문제가 있는 것으로 식별하여 23.3%의 양의 예측값을 얻었습니다.
Table 2 presents the performance of the chosen classification rule when classifying residents enrolled in the family medicine program. The classification rule achieves 100% sensitivity while maximizing specificity at 79.2%. In this group, progress issues were identified in 67 of 1129 residents (6%). The classification rule identifies these residents correctly, but it identified 221 residents as having progress issues, although they did not have an overall score indicating difficulty or failure, resulting in a positive predictive value of 23.3%.
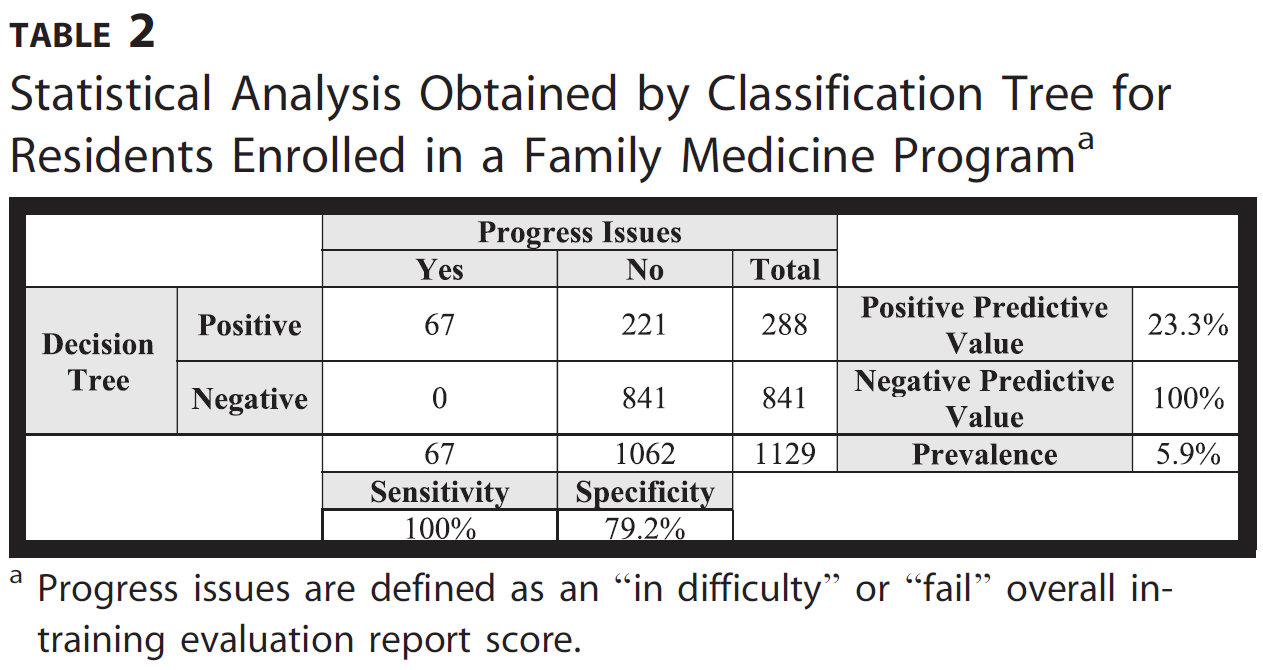
그림 1과 그림 2는 각각 RCPSC와 가정의학과 레지던트에 대해 선택한 분류 규칙을 분류 트리 형태로 보여줍니다. 트리의 각 노드는 키워드와 해당 빈도를 모두 포함하는 간단한 이진 기준을 나타내며, 기준이 충족되면 트리에서 왼쪽으로 이동합니다.
Figures 1 and 2, respectively, present the chosen classification rules for RCPSC and family medicine residents in classification tree form. Each node of the tree represents a simple binary criterion, which includes both a keyword and its frequency, with movement down the tree going to the left when the criterion is met.
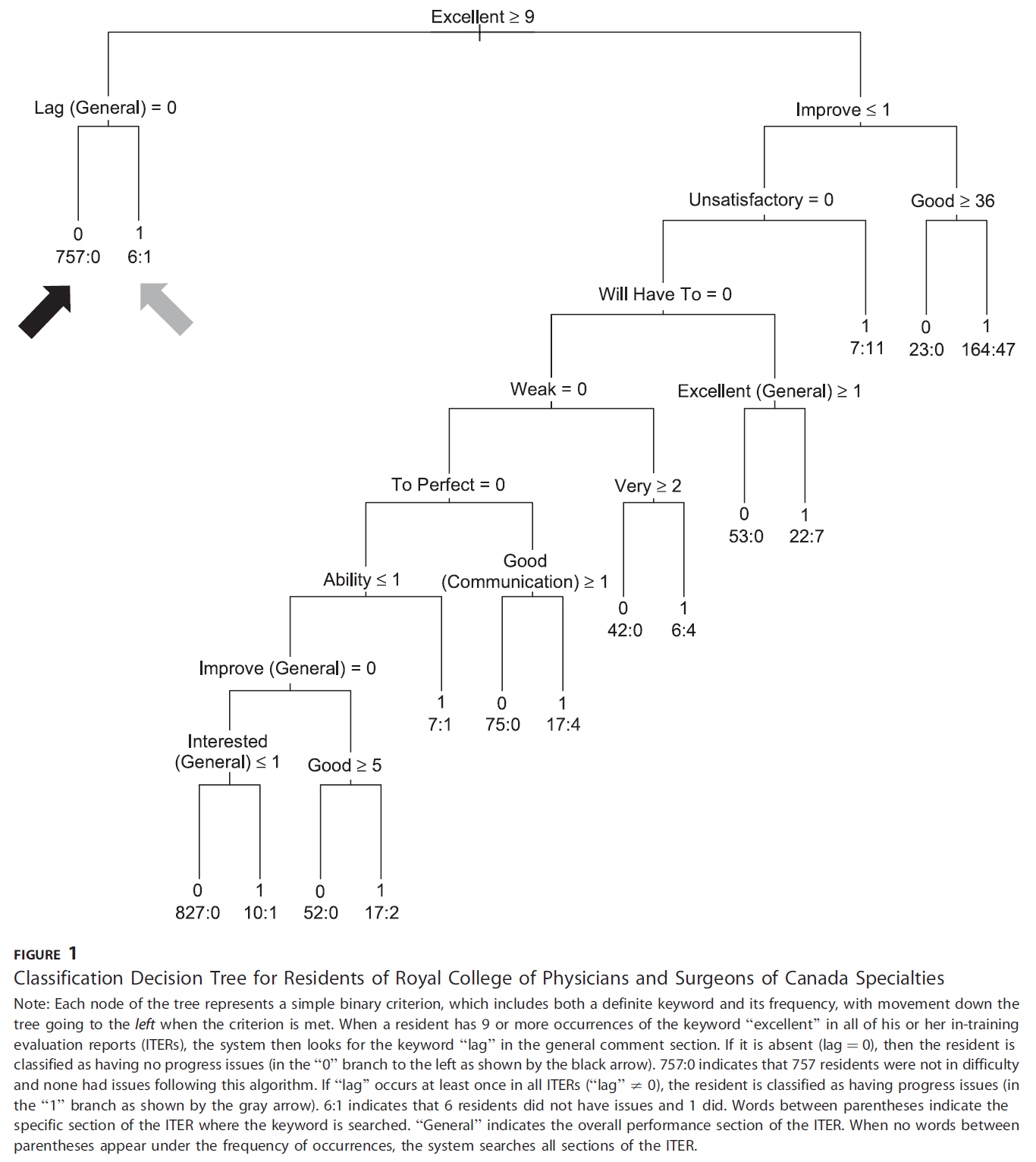
참고: 트리의 각 노드는 명확한 키워드와 해당 빈도를 모두 포함하는 간단한 이진 기준을 나타내며, 기준이 충족되면 트리에서 왼쪽으로 이동합니다. 레지던트의 모든 수련 중 평가 보고서(ITER)에 "우수excellent" 키워드가 9회 이상 포함된 경우, 시스템은 일반 코멘트 섹션에서 "지연lag" 키워드를 찾습니다. 이 키워드가 없는 경우(지연 = 0), 해당 레지던트는 진도 문제가 없는 것으로 분류됩니다(검은색 화살표로 표시된 왼쪽의 "0" 분기). 757:0은 이 알고리즘에 따라 757명의 레지던트에게 문제가 발생하지 않았음을 나타냅니다. 모든 ITER에서 "지연"이 한 번 이상 발생하면("지연" ≠ 0), 해당 레지던트는 진행에 문제가 있는 것으로 분류됩니다(회색 화살표로 표시된 "1" 분기점). 6:1은 6명에게는 문제가 없었고 1명에게는 문제가 있었음을 나타냅니다. 괄호 안의 단어는 해당 키워드가 검색된 ITER의 특정 섹션을 나타냅니다. "일반"은 ITER의 전체 성능 섹션을 나타냅니다. 발생 빈도에 괄호 사이의 단어가 나타나지 않으면 시스템은 ITER의 모든 섹션을 검색합니다.
Note: Each node of the tree represents a simple binary criterion, which includes both a definite keyword and its frequency, with movement down the tree going to the left when the criterion is met. When a resident has 9 or more occurrences of the keyword “excellent” in all of his or her in-training evaluation reports (ITERs), the system then looks for the keyword “lag” in the general comment section. If it is absent (lag = 0), then the resident is classified as having no progress issues (in the “0” branch to the left as shown by the black arrow). 757:0 indicates that 757 residents were not in difficulty and none had issues following this algorithm. If “lag” occurs at least once in all ITERs (“lag” ≠ 0), the resident is classified as having progress issues (in the “1” branch as shown by the gray arrow). 6:1 indicates that 6 residents did not have issues and 1 did. Words between parentheses indicate the specific section of the ITER where the keyword is searched. “General” indicates the overall performance section of the ITER. When no words between parentheses appear under the frequency of occurrences, the system searches all sections of the ITER.

참고: 코멘트 1은 가정의학과 수련 평가 보고서(ITER)의 의료 전문가 섹션, 코멘트 2는 의사소통 능력 및 전문성, 코멘트 3은 협업 및 관리, 일반은 전반적인 성과 섹션을 의미합니다. 괄호 안의 단어는 해당 키워드가 검색된 ITER의 특정 섹션을 나타냅니다. 괄호 사이의 단어가 발생 빈도 아래에 나타나지 않으면 시스템은 ITER의 모든 섹션을 검색합니다.
Note: Comment 1 refers to the medical expert section of the family medicine in-training evaluation report (ITER), comment 2 to communication skills and professionalism, comment 3 to collaboration and management, and general to the overall performance section. Words between parentheses indicate the specific section of the ITER where the keyword is searched. When no words between parentheses appear under the frequency of occurrences, the system searches all sections of the ITER.
트리의 각 노드는 명확한 키워드와 그 빈도를 모두 포함하는 간단한 이진 기준을 나타내며, 기준이 충족되면 트리에서 왼쪽으로 이동합니다. 레지던트가 모든 ITER의 의료 전문가 섹션에서 "독립independent" 키워드가 1회 이상 발생하면 시스템은 커뮤니케이션 및 전문성 섹션에서 "작업 중work on" 키워드를 찾습니다. 이 키워드가 존재하면("작업 중" ≠ 0), 시스템은 ITER의 모든 섹션에서 "관심interested"을 찾습니다. 2개 미만인 경우, 해당 레지던트는 진행 문제가 없는 것으로 분류됩니다(검은색 화살표로 표시된 왼쪽의 "0" 지점). 30:0은 이 알고리즘에 따라 30명의 레지던트가 어려움을 겪지 않았고 문제가 없었음을 나타냅니다. 모든 ITER에서 "관심"이 두 번 이상 발생하면(관심 < 2 아님), 해당 레지던트는 진행 문제가 있는 것으로 분류됩니다(회색 화살표로 표시된 "1" 분기). 13:3은 실제로 13명의 레지던트에게 문제가 없었고 3명에게 문제가 있음을 나타냅니다.
Each node of the tree represents a simple binary criterion, which includes both a definite keyword and its frequency, with movement down the tree going to the left when the criterion is met. When a resident has more than 1 occurrence of the keyword “independent” in the medical expert section of all ITERs, the system then looks for the keyword “work on” in the communication and professionalism section. If it is present (“work on” ≠ 0), the system looks for “interested” in all sections of the ITER. If there are fewer than 2 occurrences, the resident is classified as having no progress issues (in the “0” branch to the left as shown by the black arrow). 30:0 indicates that 30 residents were not in difficulty and none had issues following this algorithm. If “interested” occurs at least twice in all ITERs (interested not < 2), the resident is classified as having progress issues (in the “1” branch as shown by the gray arrow). 13:3 indicates that 13 residents in fact did not have issues and 3 did.
토론
Discussion
이 후향적 연구에서 우리는 성과가 미흡한 레지던트와 관련된 키워드를 기반으로 한 알고리즘이 프로그램 디렉터가 어려움을 겪고 있는 레지던트를 식별하는 데 도움이 된다는 것을 입증할 수 있었습니다. 이 알고리즘은 100%의 민감도와 100%의 음의 예측값에서 알 수 있듯이 진행에 어려움을 겪고 있는 모든 레지던트의 순위를 정확하게 매겼습니다.
In this retrospective study, we were able to demonstrate that an algorithm based on keywords associated with a suboptimal performance would help a program director identify a struggling resident. The algorithm correctly ranked all residents who had difficulty progressing, as evidenced by the 100% sensitivity and 100% negative predictive value.
진행에 문제가 있는 모든 전공의를 감지하는 알고리즘의 이러한 능력은 알고리즘 설계에 내재되어 있습니다. 이러한 절충안이 더 낮은 양의 예측 값을 제공한다는 것을 알기 때문에 특이성을 극대화했습니다. 저희의 의견으로는, 성과가 좋은 레지던트의 파일을 검토하는 것보다 어려움에 처한 레지던트의 탐지가 지연되는 결과가 훨씬 더 중요하다고 생각합니다. RCPSC 데이터 세트에서 총 334명의 레지던트가 진도 문제가 있는 것으로 확인되었습니다(그림 1). 그러나 이 데이터베이스에는 36개 프로그램의 평가 양식이 포함되어 있으며 12년 동안의 기간이 포함되어 있습니다. 따라서 매년 평균적으로 프로그램 디렉터가 검토해야 하는 레지던트 파일은 알고리즘에 의해 어려움에 처한 것으로 잘못 식별된 1건 미만이었습니다. 가정의학과에서는 그림 2에 제시된 알고리즘이 어려움에 처한 레지던트를 감지하는 데 가장 효과적인 것으로 입증되었습니다(민감도 100%, 음의 예측값). 가정의학과 프로그램의 규모가 크다는 점을 고려할 때, 12년 동안 221건의 오탐지false positives 은 교육 현장 책임자에게 이미 잘 알려진 레지던트 그룹에서 교육 현장당 1년에 1~2건에 불과합니다. 이 연구의 목적상 알고리즘을 테스트한 기준은 전체 글로벌 점수입니다. 일부 오탐false positives은 수퍼바이저의 피드백에 따라 성과가 개선되어 이후 성과가 좋은 코호트에 합류한 고군분투하는 레지던트를 나타낼 가능성이 높습니다. 또는 수퍼바이저가 "어려움" 또는 "실패"에 해당하는 전체 점수를 부여하지 않고 내러티브에서 저성과를 설명할 수도 있습니다.4,5 따라서 일부 오탐에는 실제 고군분투하는 레지던트가 포함될 수 있습니다.
This ability of the algorithm to detect all residents with progress issues is embedded in its design. Specificity was maximized, knowing that this compromise would give a lower positive predictive value. In our opinion, the consequences of delaying the detection of a resident in difficulty are much more important than reviewing the file of an otherwise well-performing resident. A total of 334 residents were identified as having progress issues in the RCPSC data set (figure 1). However, this database includes assessment forms from 36 programs and covers a period of 12 years. Therefore, each year, on average, a program director would have to review less than 1 resident file that was falsely identified by the algorithm as being in difficulty. As for family medicine, the algorithm presented in figure 2 proved to be the most effective in detecting residents in difficulty (100% sensitivity and negative predictive value). Considering the large size of the family medicine program, the 221 false positives over the 12-year period represent only 1 or 2 cases per year per teaching site, among a group of residents already well known to the teaching site director. For the purpose of this study, the standard against which the algorithm was tested is the overall global score. It is likely that some of the false positives represent struggling residents who improved their performance following feedback from their supervisors, and joined the well-performing cohort thereafter. Alternatively, supervisors could describe underperformance in the narratives without assigning the corresponding overall score “in difficulty” or “fail.”4,5 Therefore, some false positives may include true strugglers.
그림 1과 2의 알고리즘은 어려움을 겪는 전공의를 감지하는 데 필요한 키워드의 시리즈와 빈도를 강조합니다. 또한 평가자의 평가 관행에 대한 통찰력도 제공합니다.
- 예를 들어, "양호good"의 빈도가 높다는 것은 이 단어가 대부분의 ITER에서 일반적으로 사용되며 심지어 어려움을 겪는 전공의를 묘사하는 데에도 사용되기 때문에 평가자가 일반적으로 이 단어를 남용하고 있음을 시사합니다.
- "지연lag"이라는 키워드는 "우수excellent"라는 키워드와 여러 번 일치했습니다(그림 1).
- 마찬가지로 그림 2에서 볼 수 있듯이 '관심interested'과 같은 일부 긍정적인 키워드는 부정적인 성과와 연관되어 있었습니다. 이는 고군분투하는 전공의의 ITER에서 특정 격려 문구가 우선적으로 사용될 수 있음을 시사할 수 있습니다.
The algorithms in figures 1 and 2 highlight a series and frequency of keywords needed to detect struggling residents. They also provide some insight into the evaluation practices of assessors.
- For example, the high frequency of “good” suggests that this word is generally overused by assessors, as it is commonly used in most ITERs, even to describe struggling residents.
- The keyword “lag” has coincided with several occurrences of the keyword “excellent” (figure 1).
- Likewise, some positive keywords, such as “interested,” were associated with negative performance, as indicated in figure 2. This might suggest that specific encouragement wording may be preferentially used in ITERs of struggling residents.
이 연구의 결과는 블라인드 교수진이 34명의 내과 레지던트의 ITER를 개별적으로 검토한 이전 연구에서 발견한 결과와 유사하며, 이 연구에서 댓글 섹션의 단어 수와 부정적이거나 모호한 댓글이 있는 ITER의 비율은 심각한 진도 문제와 관련이 있었습니다.6 유사한 디자인을 사용하여 일반 외과 레지던트를 대상으로 한 후향적 연구에서는 수련 첫 해에 84%의 어려움을 겪는 레지던트를 식별할 수 있음을 보여주었습니다.16
The results of this study parallel the findings found in a previous study of 34 internal medicine residents' ITERs, reviewed individually by blinded faculty members, in which the number of words in the comment section and the percentage of ITERs with negative or ambiguous comments were associated with serious progress issues.6 Using a similar design, a retrospective study of general surgical residents demonstrated that 84% of struggling residents could be identified in their first year of training.16
캐나다 의사 위원회 시험의 첫 번째 파트에 대한 자동화된 에세이 채점이 신뢰할 수 있는 것으로 입증되었다는 점을 고려할 때,17 자동화된 컴퓨터 의미 분석을 사용하면 프로그램 디렉터와 대학원 의학교육 사무실의 업무를 용이하게 할 수 있습니다. 어려움에 처한 레지던트의 유병률이 낮다는 점을 고려할 때, 키워드 접근법은 레지던트 코호트가 많은 프로그램 디렉터와 경험이 적은 프로그램 디렉터, 그리고 대학원 부학장에게 유용한 플래깅 도구가 될 수 있습니다. 각 프로그램별로 ITER를 하위 분석하는 것도 흥미로운 추가 기능이었지만, 진행에 어려움을 겪은 전공의의 비율이 낮고 데이터 기밀성 문제로 인해 불가능했습니다.
Considering that automated essay scoring of the first part of the Canadian Medical Council examinations has been shown to be reliable,17 the use of an automated computer semantic analysis could facilitate the work of program directors and the office of postgraduate medical education. Given the low prevalence of residents in difficulty, a keyword approach would be a valuable flagging tool for program directors with large resident cohorts and those with little experience, as well as for the postgraduate associate dean. A subanalysis of ITERs for each program would have been an interesting addition, but the low rate of residents who experienced progress difficulties and data confidentiality concerns made this impossible.
이 알고리즘을 통해 데이터베이스에서 진행에 문제가 있는 전공의을 정확하게 식별할 수 있었지만, 부정적 키워드의 첫 사용과 "어려움" 또는 "실패"라는 글로벌 ITER 등급 사이의 리드 타임은 확인할 수 없었습니다. 또한 컴퓨터 알고리즘은 훈련생을 평가할 때 때때로 사용되는 외교적 언어의 미묘한 차이를 이해하지 못합니다.11 부정적 예측 값과 민감도는 데이터 세트에 따라 달라질 수 있습니다. 또 다른 한계는 연구 당시 가정의학과 전공의에 대한 별도의 데이터 세트를 사용했다는 점인데, 이는 이 프로그램이 RCPSC 전문과목과 상당히 다른 ITER 양식을 사용했기 때문입니다. 또한 모든 데이터는 단일 대학에서 수집되었습니다. 따라서 일부 언어 패턴은 보다 광범위한 기관 문화의 결과일 수 있으며, 일반화 가능성을 제한할 수 있습니다. 교육생의 성별18 또는 인종적 배경에 따라 언어가 다르게 사용되어 편견을 유발할 수 있습니다. 이러한 알고리즘이 부적절하게 사용될 경우, 전공의를 어려움에 처한 사람으로 잘못 분류할 수 있습니다. 마지막으로, 출판을 위해 이 글에 제시된 알고리즘의 키워드는 영어로 번역되었지만 통계 분석은 프랑스어로 작성된 ITER를 사용하여 수행되었습니다. 프랑스어 이외의 언어로 이 알고리즘을 사용하려면 키워드에 대한 문화 간 검증이 필요합니다.
While this algorithm made it possible to accurately identify residents in the database who have shown progress issues, it remains unable to determine the lead time between the first use of the negative keywords and the global ITER rating of “in difficulty” or “fail.” Moreover, a computerized algorithm does not understand the subtleties in the diplomatic language sometimes used in assessing trainees.11 The negative predictive value and sensitivity could also vary with a different data set. Another limitation was the separate data set for family medicine residents, since at the time of the study this program used an ITER form that was significantly different from the RCPSC specialties. Moreover, all data were collected at a single university. Thus, some of the linguistic patterns could be a result of a broader institutional culture, potentially limiting its generalizability. Language could be used differently according to the gender18 or ethnic background of trainees, inducing a bias. If used inappropriately, such an algorithm could lead to false labeling of residents as strugglers. Finally, for publishing purposes, the keywords of the algorithms presented in this article were translated into English, but the statistical analysis was done using ITERs written in French. Using this algorithm in a language other than French would require transcultural validation of the keywords.
현재 코호트에서 알고리즘의 키워드 사용에 대한 유효성 증거를 제공하려면 추가적인 전향적 분석이 필요합니다. 성과가 저조한 훈련생을 조기에 발견하는 알고리즘의 효율성을 평가하고 하나의 키워드 세트를 모든 프로그램에 사용할 수 있는지 여부를 결정하기 위한 추가 연구는 모든 ITER가 동일한 구조를 공유하는 지금 중요한 다음 단계입니다.
Additional prospective analyses are required to provide validity evidence for the use of the keywords of the algorithm in current cohorts. Further study to assess the algorithm's efficacy for earlier detection of underperforming trainees and to determine whether one set of keywords could be used for all programs are key next steps now that all ITERs share the same structure.
결론
Conclusions
회귀 트리를 사용한 분류에서 도출된 알고리즘을 사용하여 전향적 컴퓨터 의미 분석을 통해 레지던트의 진행 상황을 체계적으로 모니터링하는 것은 특히 역량 기반 의학교육의 일환으로 점점 더 많은 서술형 평가를 분석해야 할 필요성을 고려할 때 어려움에 처한 레지던트를 식별하는 효과적인 방법이 될 수 있습니다.
Systematic monitoring of resident progress through a prospective computerized semantic analysis using an algorithm derived from a classification with regression trees may be an effective way to identify residents in difficulty, especially given the need to analyze increasing numbers of narrative evaluations as part of competency-based medical education.
Detection of Residents With Progress Issues Using a Keyword-Specific Algorithm
PMID: 31871565
PMCID: PMC6919172
DOI: 10.4300/JGME-D-19-00386.1
Free PMC article
Background: The literature suggests that specific keywords included in summative rotation assessments might be an early indicator of abnormal progress or failure.
Objective: This study aims to determine the possible relationship between specific keywords on in-training evaluation reports (ITERs) and subsequent abnormal progress or failure. The goal is to create a functional algorithm to identify residents at risk of failure.
Methods: A database of all ITERs from all residents training in accredited programs at Université Laval between 2001 and 2013 was created. An instructional designer reviewed all ITERs and proposed terms associated with reinforcing and underperformance feedback. An algorithm based on these keywords was constructed by recursive partitioning using classification and regression tree methods. The developed algorithm was tuned to achieve 100% sensitivity while maximizing specificity.
Results: There were 41 618 ITERs for 3292 registered residents. Residents with failure to progress were detected for family medicine (6%, 67 of 1129) and 36 other specialties (4%, 78 of 2163), while the positive predictive values were 23.3% and 23.4%, respectively. The low positive predictive value may be a reflection of residents improving their performance after receiving feedback or a reluctance by supervisors to ascribe a "fail" or "in difficulty" score on the ITERs.
Conclusions: Classification and regression trees may be helpful to identify pertinent keywords and create an algorithm, which may be implemented in an electronic assessment system to detect future residents at risk of poor performance.
Accreditation Council for Graduate Medical Education 2019.
'Articles (Medical Education) > 임상교육(Clerkship & Residency)' 카테고리의 다른 글
| 어떻게 근무현장-기반 평가가 졸업후교육에서 학습을 가이드하는가: 스코핑 리뷰 (Med Educ, 2023) (0) | 2023.11.10 |
|---|---|
| 임상환경에서 문화가 학습, 실천, 정체성 발달에 영향을 주는 방식에 대한 시야 넓히기(Med Educ, 2021) (0) | 2023.09.14 |
| 임상진료상황에서 능숙한 의사소통가의 특징 식별하기(Med Educ, 2022) (0) | 2023.06.30 |
| 가능성과 불가피성: AI-관련 임상역량의 격차와 그것을 채울 필요성(Med Sci Educ. 2021) (0) | 2023.05.27 |
| 구름낀 푸른하늘: 의대생-전공의 이행에서의 지속적 긴장을 식별하고 미래의 이상적 상태 그리기(Acad Med, 2023) (0) | 2023.05.14 |