코드 포화 대 의미 포화: 얼마나 많은 인터뷰가 필요한가? (Qual Health Res. 2017)
Code Saturation Versus Meaning Saturation: How Many Interviews Are Enough?
Monique M. Hennink1, Bonnie N. Kaiser2, and Vincent C. Marconi1,3

소개
Introduction
"질적 연구에 적합한 표본 크기는 얼마인가요?" 이 질문은 정답이 없는 일반적인 질문입니다. 질적 연구는 일반적으로 의도적으로 선택된 표본(확률 기반 표본과 반대)을 사용하며, 다양한 범위의 "정보가 풍부한" 소스를 찾고(Patton, 1990) 참여자 수보다는 데이터의 품질과 풍부함에 더 중점을 둡니다. 연구 목적, 연구 설계, 연구 모집단의 특성, 분석 접근 방식, 사용 가능한 리소스 등 [다양한 요인이 질적 연구의 표본 크기에 영향]을 미칩니다(Bryman, 2012; Malterud, Siersma, & Guassora, 2015; Morse, 2000). 그러나 목적 표본의 적절성을 평가하기 위한 가장 일반적인 지침 원칙은 포화입니다(Morse, 1995, 2015). "포화는 저자가 리뷰어와 독자에게 제공하는 질적 엄격성에 대한 가장 빈번한 보증이지만, 우리가 가장 잘 알지 못하는 것입니다."(Morse, 2015, 587쪽).
“What is an adequate sample size for qualitative studies?” This is a common question for which there is not a straightforward response. Qualitative studies typically use purposively selected samples (as opposed to probability-driven samples), which seek a diverse range of “information-rich” sources (Patton, 1990) and focus more on the quality and richness of data rather than the number of participants. Many factors influence sample sizes for qualitative studies, including the study purpose, research design, characteristics of the study population, analytic approach, and available resources (Bryman, 2012; Malterud, Siersma, & Guassora, 2015; Morse, 2000). However, the most common guiding principle for assessing the adequacy of a purposive sample is saturation (Morse, 1995, 2015). “Saturation is the most frequently touted guarantee of qualitative rigor offered by authors to reviewers and readers, yet it is the one we know least about” (Morse, 2015, p. 587).
포화는 질적 연구에서 효과적인 표본 크기의 지표로 사용되며 학술지 및 연구비 지원 기관의 질적 기준에서 볼 수 있지만, 실제로 포화가 무엇을 의미하는지는 아직 명확하지 않습니다. 또한 포화는 질적 연구에 대한 다양한 접근 방식에 적용될 때 여러 가지 의미를 갖습니다(O'Reilly & Parker, 2012). 따라서 포화를 평가하는 방법, 문서화하는 방법, 다양한 유형의 연구와 다양한 유형의 데이터에 대한 포화도의 의미에 대한 방법론적 연구의 지침 없이 포화를 표본의 적절성을 나타내는 일반적인 지표로 무조건 채택하는 것은 부적절합니다. 의도적인 표본에서 포화를 달성하는 데 필요한 표본 크기와 포화에 영향을 미칠 수 있는 매개변수를 조사하기 위한 방법론적 연구는 거의 수행되지 않았습니다. 본 연구는 질적 연구에서 포화에 대한 두 가지 접근 방식을 문서화하고 평가하여 연구자가 포화가 발생할 수 있는 시점을 효과적으로 측정할 수 있는 지침을 제공하고 연구 제안서 및 프로토콜의 표본 크기 추정을 강화하기 위한 방법론적 연구에 기여합니다.
Although saturation is used as an indicator of an effective sample size in qualitative research, and is seen in quality criteria of academic journals and research funding agencies, it remains unclear what saturation means in practice. Saturation also has multiple meanings when applied in different approaches to qualitative research (O’Reilly & Parker, 2012). Therefore, unquestioningly adopting saturation as a generic indicator of sample adequacy is inappropriate without guidance from methodological research on how to assess saturation, how to document it, and what it means for different types of studies and different types of data. Few methodological studies have been conducted to examine sample sizes needed to achieve saturation in purposive samples and the parameters that may influence saturation. Our study contributes methodological research to document and assess two different approaches to saturation in qualitative research, to provide guidance for researchers to effectively gauge when saturation may occur, and to strengthen sample size estimates for research proposals and protocols.
포화 정의
Defining Saturation
포화 개념은 원래 사회 현상을 설명하기 위해 텍스트 데이터로부터 사회학 이론을 개발하는 데 중점을 두는 질적 연구에 대한 영향력 있는 [근거 이론 접근법]의 일환으로 Glaser와 Strauss(1967)에 의해 개발되었습니다. 근거 이론에서는 [이론적 포화]라는 용어를 사용하는데, 이는 [데이터 수집 시 데이터에서 추가적인 문제나 통찰력이 나타나지 않고 관련 개념 범주가 모두 식별, 탐색, 소진된 시점]을 의미합니다. 이는 개념 범주가 "포화 상태"에 이르렀으며 새로운 이론이 포괄적이고 신뢰할 수 있다는 신호입니다. 따라서 [이론적 포화 상태]는 "이론적 구성에 대한 더 많은 데이터를 수집해도 새로운 속성이 드러나지 않거나 새로운 근거 이론에 대한 더 이상의 이론적 통찰력을 얻지 못하는 지점"입니다(Bryant & Charmaz, 2007, 611쪽). 이론적 포화의 강조점은 표본의 적절성보다는 표본 크기에 더 중점을 둡니다(Bowen, 2008).
The concept of saturation was originally developed by Glaser and Strauss (1967) as part of their influential grounded theory approach to qualitative research, which focuses on developing sociological theory from textual data to explain social phenomena.
- In grounded theory, the term theoretical saturation is used, which refers to the point in data collection when no additional issues or insights emerge from data and all relevant conceptual categories have been identified, explored, and exhausted. This signals that conceptual categories are “saturated”, and the emerging theory is comprehensive and credible.
- Thus, theoretical saturation is “the point at which gathering more data about a theoretical construct reveals no new properties nor yields any further theoretical insights about the emerging grounded theory” (Bryant & Charmaz, 2007, p. 611).
[이론적 포화]의 중요한 측면은 연구자가 샘플링, 데이터 수집, 데이터 분석을 동시에 수행하는 [반복적 프로세스에 포함]되어 있다는 것입니다(Sandelowski, 1995). 이러한 반복적인 프로세스는 ['이론적 샘플링']을 가능하게 하는데, 이는 참여자 모집을 안내하는 데 사용되는 데이터에서 개념을 식별하여 [이론적 포화 상태에 도달할 때까지 후속 데이터 수집에서 해당 개념을 추가로 탐색하는 것]을 포함합니다. 따라서 [이론적 샘플링]은 [이론적 포화]와 [불가분의 관계]에 있으며, 이는 현상의 모든 구성 요소(예: 이슈, 개념, 범주 및 연결)를 충분히 탐색하고 지원하여 새로운 이론이 타당하고 견고하도록 하기 위한 것입니다. 따라서 [이론적 포화]는 근거 이론의 목표와 인식론적 접근 방식에 내재되어 있습니다.
The emphasis of theoretical saturation is more toward sample adequacy and less about sample size (Bowen, 2008). An important aspect of theoretical saturation is that it is embedded in an iterative process, whereby researchers are concurrently sampling, collecting data, and analyzing data (Sandelowski, 1995). This iterative process enables “theoretical sampling”, which involves identifying concepts from data that are used to guide participant recruitment to further explore those concepts in subsequent data collection until theoretical saturation is reached. Theoretical sampling is thereby inextricably linked to theoretical saturation to ensure that all constructs of a phenomenon (i.e., issues, concepts, categories, and linkages) are fully explored and supported so that the emerging theory is valid and robust. Theoretical saturation is therefore embedded in the goals and epistemological approach of grounded theory.
포화 적용의 과제
Challenges in Applying Saturation
포화는 근거 이론에서 시작되었지만, 질적 연구에 대한 다른 많은 접근 방식에도 적용됩니다. [데이터 포화] 또는 [주제 포화]라고도 하며, [데이터 수집에서 추가적인 문제가 발견되지 않고 데이터가 반복되기 시작하며 더 이상의 데이터 수집이 불필요해지는 시점]을 말합니다(Kerr, Nixon, & Wild, 2010). 이러한 포화의 광범위한 적용은 이론을 개발하기 위한 데이터의 적절성("이론적 포화"에서와 같이)보다는 표본 크기를 측정하는 데 더 직접적으로 초점을 맞추고 있습니다. 포화의 개념을 방법론적 기원에서 벗어나 질적 연구에 더 일반적으로 적용하는 것은 다소 의문의 여지가 있지만 여전히 문제가 있습니다(Kerr et al., 2010). 근거 이론 외부에서 포화를 사용할 경우, 포화는 종종 표본 추출, 데이터 수집, 데이터 분석의 반복적인 프로세스와 분리되어 적용에 절차적 구조를 제공하지 못합니다. 이러한 [광범위한 맥락에서의 적용에 대한 적절한 지침]이 없으면 [포화가 무엇을 의미하고 어떻게 달성할 수 있는지 불분명]합니다(Kerr et al., 2010).
Despite its origins in grounded theory, saturation is also applied in many other approaches to qualitative research. It is often termed data saturation or thematic saturation and refers to the point in data collection when no additional issues are identified, data begin to repeat, and further data collection becomes redundant (Kerr, Nixon, & Wild, 2010). This broader application of saturation is focused more directly on gauging sample size rather than the adequacy of data to develop theory (as in “theoretical saturation”). Taking the concept of saturation out of its methodological origins and applying it more generically to qualitative research has been somewhat unquestioned but remains problematic (Kerr et al., 2010). When used outside of grounded theory, saturation often becomes separated from the iterative process of sampling, data collection, and data analysis, which provide procedural structure to its application. Without adequate guidance on its application in this broader context, it is unclear what saturation means and how it can be achieved (Kerr et al., 2010).
이 문제는 발표된 질적 연구에서도 명확하게 드러납니다. 포화가 언급되는 경우, 포화가 어떻게 달성되었는지 또는 포화가 정당화되는 근거가 무엇인지에 대한 설명 없이 그냥 넘어가는 경우가 많습니다(Bowen, 2008; O'Reilly & Parker, 2012).
- 예를 들어, Francis 등(2010)은 건강 관련 분야에서 데이터 포화가 어떻게 보고되는지 파악하기 위해 16개월 동안 다학제 저널인 사회과학 및 의학에 게재된 모든 논문을 검토했습니다. 데이터 포화를 언급한 18개 논문 중 15개 논문이 포화를 달성했다고 주장했지만, 이러한 연구에서 포화가 어떻게 정의, 달성 또는 정당화되었는지는 불분명했습니다.
- 칼슨과 글렌튼(2011)은 포커스 그룹 토론을 통해 220개의 연구를 체계적으로 검토하여 표본 크기가 어떻게 정당화되었는지 확인했습니다. 그 결과, 표본 크기를 설명한 연구 중 83%가 포화를 표본 크기의 정당화로 사용했습니다. 그러나 이러한 논문은 포화도에 대한 근거 없는 주장, 미리 정해진 표본 크기를 사용하면서 포화를 달성했다는 언급 등 포화를 달성한 방법에 대한 피상적인 보고를 제공한다는 사실을 발견했습니다.
- 포화를 평가한 방법이나 그 근거에 대한 정당성이나 설명을 제공하지 않고 포화를 주장하는 연구자들에 대한 우려가 커지고 있습니다(Bowen, 2008; Green & Thorgood, 2009; Guest, Bunce, & Johnson, 2006; Kerr et al., 2010; Malterud et al., 2015; Morse, 1995, 2000, 2015).
This issue is clearly reflected in published qualitative research. If saturation is mentioned, it is often glossed over with no indications for how it was achieved or the grounds on which it is justified (Bowen, 2008; O’Reilly & Parker, 2012).
- For example, Francis et al. (2010) reviewed all articles published in the multidisciplinary journal Social Science & Medicine over a 16-month period to identify how saturation is reported in health-related disciplines. Of the 18 articles that mentioned data saturation, 15 articles claimed they achieved saturation, but it was unclear how saturation was defined, achieved, or justified in these studies.
- Carlsen and Glenton (2011) conducted a systematic review of 220 studies using focus group discussions to identify how sample size was justified. They found that of those studies that explained sample size, 83% used saturation as the justification for their sample size. However, they found that these articles provided superficial reporting of how saturation was achieved, including unsubstantiated claims of saturation and reference to achieving saturation while still using the predetermined sample size.
- There is increasing concern over researchers claiming saturation without providing any justification or explanation of how it was assessed or the grounds on which it was achieved (Bowen, 2008; Green & Thorgood, 2009; Guest, Bunce, & Johnson, 2006; Kerr et al., 2010; Malterud et al., 2015; Morse, 1995, 2000, 2015).
Morse(1995)는 [포화 상태에 도달하는 데 필요한 표본 크기에 대한 공개된 지침]이 부족하다는 점을 오래 전에 강조했습니다. 10년이 지난 지금도 이러한 상황은 그대로 남아 있으며, 24권의 질적 연구 교과서와 7개의 데이터베이스를 검토한 Guest 외(2006)의 연구에서도 목적적 표본의 포화를 달성하는 방법에 대한 가이드라인을 찾을 수 없었습니다. 저자들은 문헌이 "포화 개념을 제대로 조작화하지 못하며, 포화를 결정하는 방법에 대한 설명과 의도적으로 표본 추출된 인터뷰의 표본 크기를 추정하기 위한 실질적인 지침을 제공하지 않는다"고 결론지었습니다(Guest 외, 2006, 60쪽). 10년이 지난 지금도 많은 사람들은 질적 연구에서 포화를 평가하는 지침이 여전히 모호하고 근거에 기반하지 않는다는 데 동의합니다(Carlsen & Glenton, 2011; Kerr et al., 2010). 포화는 단순한 매력에도 불구하고 조작 및 입증하기가 복잡합니다. 포화가 표본의 적절성을 평가하는 기준으로 유지되려면 포화를 달성하고 평가하는 방법을 조사하기 위한 추가적인 방법론적 연구를 수행해야 합니다. 궁극적으로 이러한 연구 없이는 '포화 상태에 도달했다'는 선언은 의미가 없어지고 용어의 목적이 훼손될 수 있습니다.
Morse (1995) highlighted long ago that there exists a lack of published guidelines on sample sizes needed to reach saturation. A decade later, this situation remains, as confirmed by Guest et al. (2006), who reviewed 24 qualitative research textbooks and seven databases and found no guidelines on how to achieve saturation in purposive samples. The authors concluded that the literature does a “poor job of operationalizing the concept of saturation, providing no description of how saturation might be determined and no practical guidelines for estimating sample sizes for purposively sampled interviews” (Guest et al., 2006, p. 60). Another decade has passed, and many still agree that guidelines for assessing saturation in qualitative research remain vague and are not evidence-based (Carlsen & Glenton, 2011; Kerr et al., 2010). Despite its simple appeal, saturation is complex to operationalize and demonstrate. If saturation is to remain a criterion for assessing sample adequacy, it behooves us to conduct further methodological studies to examine how saturation is achieved and assessed. Ultimately without these studies, declarations of “reaching saturation” become meaningless and undermine the purpose of the term.
또 다른 문제는 포화는 데이터 수집 중에만 작동할 수 있지만 표본 크기는 연구 제안서와 프로토콜에 미리 명시해야 한다는 것입니다. 표본 크기를 선험적으로 파악해야 하는 것은 "질적 연구에 대해 제도적으로 생성된 문제"(Hammersley, 2015, 687쪽)입니다. 또한 질적 표본은 일반적으로 현장에서 반복적인 접근 방식을 사용하여 정의, 개선 및 강화되기 때문에 [윤리 위원회 및 자금 지원 기관에서 요구하는 선험적 표본 크기 결정 요건]은 질적 연구에 어려움을 제공합니다. 그럼에도 불구하고 연구자들은 선험적으로 표본 크기를 추정해야 하지만, 이러한 추정을 뒷받침하기 위해 다양한 유형의 질적 연구에 대해 포화 상태에 도달하는 데 필요한 표본 크기를 입증하는 방법론적 연구는 거의 없습니다. 따라서 질적 연구에 대한 대부분의 표본 크기 권장 사항은 경험적 또는 '경험의 법칙'에 따른 것입니다(Bryman, 2012; Guest 외., 2006; Kerr 외., 2010; Morse, 1995; Sandelowski, 1995). 또한 적절한 표본 크기를 사용하는 것도 [윤리적 문제]입니다(Carlsen & Glenton, 2011; Francis 외, 2010). 필요 이상으로 큰 질적 표본은 연구비를 낭비하고 연구 모집단에 부담을 주며 미사용 데이터로 이어질 수 있으며, 표본이 너무 작으면 현상을 충분히 포착하지 못하고 연구 결과의 타당성을 떨어뜨리며 연구 결과를 바탕으로 개입을 구축하는 데 자원이 낭비될 수 있습니다. 따라서 다양한 유형의 질적 연구에 대한 표본 크기의 선험적 추정치를 안내할 수 있는 증거를 제공하기 위해 포화의 실제 적용에 대한 추가적인 방법론적 연구가 필요합니다.
A further challenge is that saturation can only be operationalized during data collection, but sample sizes need to be stated in advance on research proposals and protocols. The need to identify sample sizes a priori is to a large extent “an institutionally generated problem for qualitative research” (Hammersley, 2015, p. 687). In addition, requirements mandated by ethics committees and funding agencies for a priori determination of sample sizes provide challenges in qualitative research because qualitative samples are typically defined, refined, and strengthened using an iterative approach in the field. Nonetheless, researchers do need to estimate their sample size a priori, yet there is little methodological research that demonstrates sample sizes needed to reach saturation for different types of qualitative studies to support these estimates. Most sample size recommendations for qualitative research are thus experiential or “rules of thumb” (Bryman, 2012; Guest et al., 2006; Kerr et al., 2010; Morse, 1995; Sandelowski, 1995). Furthermore, using an appropriate sample size is also an ethical issue (Carlsen & Glenton, 2011; Francis et al., 2010): qualitative samples that are larger than needed waste research funds, burden the study population, and lead to unused data, while samples that are too small may not fully capture phenomena, reduce the validity of findings, and waste resources that build interventions on those findings. Therefore, further methodological research is needed on the practical application of saturation to provide a body of evidence that can guide a priori estimates of sample sizes for different types of qualitative research.
포화 평가
Assessing Saturation
많은 논문에서 포화를 보고할 때 투명성을 높여야 한다고 강조하지만(Carlsen & Glenton, 2011; Fusch & Ness, 2015; Kerr et al., 2010; Morse, 2015; O'Reilly & Parker, 2012), 포화를 효과적으로 평가, 보고 및 정당화하는 데 사용할 수 있는 포화 달성 방법에 대한 경험적 데이터를 제공하는 연구는 거의 없습니다. 두 가지 주목할 만한 예외가 있습니다.
- Guest 등(2006)은 서아프리카 2개국에서 60건의 심층 인터뷰를 실시한 연구 데이터를 사용하여 주제 분석 중 데이터 포화를 체계적으로 문서화하고, 주제 소진에 도달하는 데 필요한 인터뷰 횟수를 파악하고, 중요한 주제가 언제 개발되었는지 파악했습니다. 연구진은 6차례의 연속적인 인터뷰를 통해 제기된 콘텐츠 중심 주제의 수를 세고, 새로운 주제가 제기되거나 새로운 코드북에서 기존 주제가 변경된 시기를 파악하여 주제 개발의 진행 상황을 문서화했습니다. 또한 연구 데이터 전체에서 코드 적용 빈도를 기준으로 테마의 중요도를 평가했습니다.
- 연구팀은 12번의 인터뷰를 통해 테마의 포화 상태에 도달했지만, 6번의 인터뷰에서는 테마의 기본 요소가 이미 존재한다는 결론을 내렸습니다. 포화는 이러한 데이터에서 테마 개발의 정도와 테마의 중요도에 따라 평가되었습니다. 따라서 12번의 인터뷰를 통해 모든 신규 테마의 88%가 개발되었고, 모든 중요 테마의 97%가 개발되었으므로 12번의 인터뷰를 통해 코드북 구조가 안정화되었으며 그 이후에는 변경이나 추가가 거의 이루어지지 않았습니다.
- 저자들은 비교적 동질적인 표본, 집중된 연구 목표, 반구조화된 인터뷰 가이드가 12번의 인터뷰를 통해 데이터 포화 상태에 도달하는 데 기여했을 수 있다고 언급합니다. 또한 포화는 연구, 데이터, 연구자의 다양한 특성에 따라 달라질 수 있다고 강조하면서 12건의 인터뷰를 포화의 일반적인 표본 크기로 사용하는 것에 대해 주의를 당부합니다.
Numerous articles emphasize the need for more transparency in reporting saturation (Carlsen & Glenton, 2011; Fusch & Ness, 2015; Kerr et al., 2010; Morse, 2015; O’Reilly & Parker, 2012); however, few studies provide empirical data on how saturation was achieved that can be used to effectively assess, report, and justify saturation. There are two notable exceptions.
- Guest et al. (2006) used data from a study involving 60 in-depth interviews in two West African countries to systematically document data saturation during thematic analysis, identify the number of interviews needed to reach thematic exhaustion, and find when important themes were developed. They documented the progression of theme development by counting the number of content-driven themes raised in successive sets of six interviews, identifying when new themes were raised or changes were made to existing themes in the emerging codebook. They also assessed the importance of themes based on the frequency of code application across the study data.
- They concluded that saturation of themes was achieved by 12 interviews, but that the basic elements for themes were already present at six interviews. Saturation was assessed based on the extent of theme development and theme importance in these data. As such, by 12 interviews, 88% of all emergent themes had been developed, and 97% of all important themes were developed; therefore, the codebook structure had stabilized by 12 interviews with few changes or additions thereafter.
- The authors note that their relatively homogeneous sample, focused study objectives, and semistructured interview guide may have contributed to reaching data saturation by 12 interviews. They also caution against using 12 interviews as a generic sample size for saturation, stressing that saturation is likely dependent on a range of characteristics of the study, data, and researchers.
이 연구는 포화 상태에 도달하는 데 필요한 샘플 크기를 입증한 최초의 방법론적 연구이지만 몇 가지 한계가 있습니다. 정확한 포화 시점이 불분명합니다. 저자는 12개의 인터뷰로 포화 상태에 도달했다고 말하지만, 인터뷰는 6개씩 일괄적으로 검토되었기 때문에 실제로는 7~12개의 인터뷰 사이에서 포화 상태가 발생했습니다. 코드가 일률적으로 제시되어 있어 다양한 유형의 코드와 코드 특성에 따라 포화도가 어떻게 달라질 수 있는지에 대한 고려가 없습니다. 또한 반복적 다양성 샘플링을 사용하여 참가자를 모집했는지 여부도 불분명하므로 이것이 이 연구의 포화도에 영향을 미쳤는지 또는 어떻게 영향을 미쳤는지는 평가할 수 없습니다(Kerr et al., 2010). 아마도 가장 큰 한계는 테마의 의미를 평가하지 않고 테마의 발생 횟수를 세어 포화도를 평가했다는 점일 것입니다. 테마를 식별하는 것은 포화도에 도달하기 위한 첫 번째 단계에 불과합니다. "테마가 처음 등장했을 때 파악된 내용은 특별히 통찰력이 있거나 드러나지 않을 수 있습니다. 테마 또는 개념의 내용과 정의를 깊이 있게 개발하려면 추가 데이터 수집 및 분석이 필요할 수 있습니다."(Kerr 외., 2010, 276쪽). 마찬가지로 코드의 중요도는 현상 이해에 대한 기여도보다는 데이터 전반에서 코드의 유병률로 정의됩니다:
This was the first methodological study demonstrating the sample size required to achieve saturation; however, it has some limitations. The exact point of saturation is unclear. The authors state that saturation was achieved by 12 interviews, but interviews were reviewed in batches of six, so that saturation actually occurred somewhere between seven and 12 interviews. Codes are presented as uniform, so there is no consideration of different types of codes and how saturation may differ by code characteristics. It is also unclear whether iterative diversity sampling was used to recruit participants, so we cannot assess whether or how this may have influenced saturation in this study (Kerr et al., 2010). Perhaps the greatest limitation is the assessment of saturation by counting occurrences of themes, without also assessing the meaning of those themes. Identifying themes is just the first step in reaching saturation. “What is identified about the theme the first time it emerges may not be particularly insightful or revealing. Further data collection and analysis may be required to develop depth in the content and definition of a theme or concept” (Kerr et al., 2010, p. 276). Similarly, code importance is defined by the prevalence of codes across data rather than their contribution to understanding the phenomenon:
코드의 의미와 내용에 대한 질적 판단이 없다면, [덜 흔한 코드 중 하나]가 [더 적은 수의 인터뷰가 수행되었다면 놓쳤을 이해의 핵심 열쇠]가 아니라고 누가 말할 수 있겠는가. (Kerr 외, 2010, 274쪽)
Without any qualitative judgement of the meaning and content of codes who is to say that one of the less prevalent codes was not a central key to understanding that would have been missed if fewer interviews had been conducted. (Kerr et al., 2010, p. 274)
따라서 게스트와 동료들의 연구에서 놓친 중요한 요소는 이슈의 의미에서 포화 상태에 도달하는 데 필요한 표본 크기와 이것이 데이터에서 테마의 존재를 식별하여 제안한 표본 크기와 어떻게 비교될 수 있는지를 평가하는 것입니다. 따라서 이 연구에서는 데이터에서 제기된 이슈를 완전히 이해하는 데 필요한 인터뷰 횟수에 대한 지침을 제공하지 않습니다.
Therefore, a critical missing element in the work of Guest and colleagues is to assess the sample size needed to reach saturation in the meaning of issues and how this might compare with their sample size suggested by identifying the presence of themes in data. Therefore, this study does not provide guidance on the number of interviews needed to fully understand the issues raised in these data.
Francis 등(2010)의 또 다른 방법론 연구에서는 이론 기반 인터뷰 연구(계획된 행동 이론에 의해 개념 범주가 미리 결정된 경우)에서 개념의 포화 상태가 언제 발생하는지 확인했습니다. 이들은 분석을 통해 선험적으로 수행할 초기 인터뷰 횟수 지정, 사용할 중단 기준(더 이상 개념이 나오지 않는 연속 인터뷰 횟수 기준) 파악, 투명하고 검증 가능한 방식으로 포화 상태 보고 등 데이터 포화 상태를 설정하고 보고하기 위한 원칙을 제안했습니다. 분석에서 연구진은 초기 샘플로 10개의 인터뷰(이 숫자에 대한 근거는 제공하지 않음)를 사용하고, 중지 기준을 3개로 설정했으며, 개념의 포화와 전체 연구 포화를 보여주기 위해 누적 빈도 그래프를 제시했습니다.
- 이 매개변수 내에서 한 연구에서는 17번의 인터뷰를 통해 전체 연구 포화도에 도달했으며, 각 신념 범주가 다른 지점에서 포화에 도달하는 것으로 나타났습니다.
- 두 번째 연구에서는 한 신념 범주에서는 포화 상태에 도달했지만 다른 범주에서는 포화 상태에 도달하지 않았기 때문에 14번의 인터뷰에서는 전체 연구 포화 상태에 도달하지 못했습니다.
이러한 결과는 포화가 단차원적인 것이 아니라 [개별 구성 요소] 또는 [전체 연구 포화]에 따라 다양한 수준에서 평가(또는 달성)될 수 있다는 점을 강조합니다. 따라서 연구자들은 자신이 달성했다고 주장하는 포화의 유형을 명확히 해야 합니다. Francis 등의 연구는 데이터에서 이슈의 의미에 대한 포화도를 평가할 필요성을 인정하기 시작했지만, 귀납적인 내용 중심 주제가 아닌 외부에서 파생된 개념 범주를 사용하여 연구의 포화도를 입증하는 데 그치고 있습니다.
Another methodological study by Francis et al. (2010) identified when saturation of concepts occurs in theory-based interview studies (where conceptual categories were predetermined by the theory of planned behavior). They used their analysis to propose principles for establishing and reporting data saturation, including specifying a priori an initial number of interviews to conduct, identifying stopping criteria to use (based on the number of consecutive interviews that yield no further concepts), and reporting saturation in a transparent and verifiable way. In their analysis, they used an initial sample of 10 interviews (although they provide no justification for this number), a stopping criterion of three, and present cumulative frequency graphs to demonstrate saturation of concepts and overall study saturation.
- Within these parameters, they found that one study reached overall study saturation by 17 interviews, with each belief category reaching saturation at a different point.
- In a second study, saturation was achieved in one belief category but not in others; therefore, overall study saturation was not achieved in the 14 interviews conducted.
These results highlight that saturation is not unidimensional; it can be assessed (or achieved) at different levels—by individual constructs or by overall study saturation. Thus, researchers need to be clear on the type of saturation they claim to have achieved. Francis et al.’s study begins to acknowledge the need to assess saturation in the meaning of issues in data; however, the results are limited to demonstrating saturation in studies using externally derived conceptual categories, rather than more inductive content-driven themes.
연구 목표
Study Aims
본 연구는 포화도 운영에 대한 더 많은 방법론적 연구에 대한 요구에 부응합니다(Francis 외, 2010; Guest 외, 2006; Morse, 2015). 우리는 포화가 실제로 무엇을 의미하는지, 어떻게 평가하고 문서화할 수 있는지 탐구하고, 질적 연구에서 표본 크기를 추정하는 데 필요한 실용적인 지침을 제공합니다. 우리는 앞서 설명한 포화의 일반적인 적용, 즉 근거 이론의 맥락 밖에서 사용되는 포화의 일반적인 적용에 초점을 맞추고 있습니다. 이러한 초점은 다른 질적 접근법에서 포화가 어떻게 적용되거나 달성되었는지에 대한 설명 없이 포화도가 자주 사용되며, 위에서 설명한 바와 같이 이러한 광범위한 맥락에서 포화도 사용에 대한 방법론적 지침이 부족하기 때문에 적절하다고 판단됩니다.
Our study responds to calls for more methodological research on operationalizing saturation (by Francis et al., 2010; Guest et al., 2006; Morse, 2015). We explore what saturation means in practice, how it can be assessed and documented, and we provide pragmatic guidance on estimating sample sizes in qualitative research. We focus on the general application of saturation, described earlier, as used outside of the grounded theory context. This focus is warranted due to the frequent use of saturation in other qualitative approaches without explanation of how it was applied or achieved and due to the lack of methodological guidance on the use of saturation in this broader context, as described above.
본 연구에서는 [코드 포화]와 [의미 포화]라는 두 가지 포화 평가 접근법을 살펴봅니다.
- 먼저 [코드 포화]를 평가했는데, 코드 포화는 추가적인 문제가 발견되지 않고 코드집이 안정화되기 시작하는 시점으로 정의했습니다. 그런 다음 [코드 포화]가 식별된 문제를 완전히 이해하기에 충분한지 평가했습니다.
- 둘째, [의미 포화]를 평가했습니다. 이는 이슈를 완전히 이해하고 더 이상 이슈의 차원, 뉘앙스 또는 인사이트를 찾을 수 없는 시점으로 정의했습니다. 또한 코드의 특정 특성이 코드 또는 의미 포화에 영향을 미치는지 평가하여 연구에서 개발된 코드의 특성에 따라 포화를 추정할 수 있는 매개변수를 제공했습니다.
이 연구에서는 다음과 같은 연구 질문에 대한 답을 찾고자 했습니다:
Our study explores two approaches to assessing saturation, which we term code saturation and meaning saturation. We first assessed code saturation, which we defined as the point when no additional issues are identified and the codebook begins to stabilize. We then assessed whether code saturation is sufficient to fully understand issues identified. Second, we assessed meaning saturation, which we defined as the point when we fully understand issues, and when no further dimensions, nuances, or insights of issues can be found. We also assessed whether certain characteristics of codes influence code or meaning saturation, to provide parameters for estimating saturation based on the nature of codes developed in a study. Our study sought to answer the following research questions:
- 연구 질문 1: 코드 포화도에 도달하려면 얼마나 많은 인터뷰가 필요한가?
- 연구 질문 2: 의미 포화도에 도달하기 위해 얼마나 많은 인터뷰가 필요한가?
- 연구 질문 3: 코드 특성이 포화도에 어떤 영향을 미치는가?
- 연구 질문 4: 질적 표본 크기를 추정하기 위해 선험적으로 포화도를 평가하는 데 사용할 수 있는 매개변수는 무엇인가요
- Research Question 1: How many interviews are needed to reach code saturation?
- Research Question 2: How many interviews are needed to reach meaning saturation?
- Research Question 3: How do code characteristics influence saturation?
- Research Question 4: What parameters can be used to assess saturation a priori to estimate qualitative sample sizes?
이 연구는 건강 행동을 이해하고 중재를 개발하기 위해 일반적으로 보건 과학 및 공중 보건 연구에서 사용되는 응용 질적 연구의 포화도를 평가하는 데 중점을 두었습니다. 이러한 응용 분야에서는 민족지학적 연구와 같은 다른 유형의 질적 연구보다 연구 목적과 연구 집단이 더 명확하게 정의될 수 있습니다.
Our study focused on assessing saturation in applied qualitative research, typically used in health sciences and public health research to understand health behavior and develop interventions. In these applications, the research purpose and study population may be more defined than in other types of qualitative research, such as ethnographic studies.
연구 방법
Method
연구 배경
Study Background
데이터의 포화도에 대한 분석의 맥락으로 원본 연구의 데이터 수집에 대한 개요를 제공합니다. 원래 연구의 연구 질문은 "HIV 치료에서 환자 유지에 영향을 미치는 요인은 무엇인가?"였습니다. 항레트로바이러스 치료(ART)의 등장으로 HIV 감염은 치명적인 질병에서 만성 질환으로 전환되었습니다. ART는 질병의 진행을 늦추고 다른 사람에게 HIV를 전파하는 것을 줄이는 데 중요합니다(Attia, Egger, Müller, Zwahlen, & Low, 2009; Cohen 외., 2011; "Vital Signs", 2011). HIV 진단 직후 치료와 연계되는 것은 ART를 조기에 시작하고 바이러스 부하 및 기타 동반 질환을 정기적으로 모니터링하는 데 매우 중요합니다. 그러나 미국에서 HIV 양성으로 알려진 사람들 중 77%만이 치료와 연계되어 있으며, 그 이후에도 정기적인 치료를 받는 비율은 51%에 불과합니다(Hall et al., 2012; "Vital Signs," 2011). 따라서 [본 연구의 목적]은 미국 최대 규모의 재향군인병원인 애틀랜타 재향군인 의료센터(AVAMC)의 감염병 클리닉(IDC)에서 HIV 양성 환자를 치료하는 데 있어 무엇이 치료 유지에 영향을 미치는지 파악하는 것이었습니다.
We provide an overview of data collection for the original study as context for our analyses on saturation of these data. The research question of the original study was: what influences patient retention in HIV care? With the advent of antiretroviral therapy (ART), HIV infection has transitioned from a fatal disease to a chronic condition. ART is important for slowing progression of the disease and reducing HIV transmission to others (Attia, Egger, Müller, Zwahlen, & Low, 2009; Cohen et al., 2011; “Vital Signs,” 2011). Becoming linked to care soon after diagnosis with HIV is critical for early initiation of ART and regular monitoring of the viral load and other comorbidities. However, only 77% of those known to be HIV positive in the United States are linked to care, and only 51% are retained in regular care thereafter (Hall et al., 2012; “Vital Signs,” 2011). Therefore, the aim of the original study was to understand what influences retention in HIV care at the Infectious Disease Clinic (IDC) of the Atlanta VA Medical Center (AVAMC), the largest VA clinic caring for HIV-positive patients in the United States.
데이터 수집 및 분석
Data Collection and Analysis
연구 참여 자격은 18세 이상이고 2011년 1월 이전에 IDC에 처음 방문했으며 HIV 양성으로 진단받은 경우였습니다. 연구 참여자는 현재 IDC에서 치료를 받고 있는 환자(치료 중 그룹)와 IDC에서 6개월 이상 치료를 받았지만 최소 8개월 동안 클리닉 방문에 참석하지 않은 환자(치료 외 그룹)의 두 그룹으로 나뉘었습니다. 연구 기간 동안 클리닉 예약이 예정된 적격 참가자를 식별하기 위해 환자 기록을 선별했습니다. 진료 외 환자는 진료 외 시간에 따라 사분위수로 나눈 다음 각 사분위수에서 의도적으로 선정했습니다. 그런 다음 연령, 인종, 성별을 기준으로 진료 중인 환자를 진료 외 참여자와 일치하도록 선정했습니다. 참가자에게 전화로 연락하여 정기 진료 예약 시간 또는 다른 시간에 연구에 참여하도록 초대했습니다. 클리닉 기록을 사용하여 인구통계학적 특성 및 치료 유지 특성에 따라 의도적인 다양성 샘플링이 가능했으며, 이후 반복적인 모집을 통해 고용과 같은 다른 특성에서도 다양성을 확보할 수 있었습니다. 데이터는 2013년 2월부터 7월까지 25회의 심층 인터뷰를 통해 수집되었습니다: 16명은 보호 대상에서 벗어난 사람들을, 9명은 보호 대상에서 벗어난 사람들을 대상으로 심층 인터뷰를 진행했습니다. 돌봄을 받지 않는 그룹에서 더 다양한 문제가 제기되었기 때문에 이러한 문제를 완전히 이해하기 위해 더 많은 인터뷰가 필요했습니다. 인터뷰는 질적 연구에 대한 교육을 받고 HIV 치료 및 AVAMC에 대한 경험이 있는 연구자들이 수행했습니다. 연구자들은 반구조화된 인터뷰 가이드를 사용하여 군 복무가 건강 관리에 미치는 영향, HIV 진단, HIV에 대한 지식, HIV 치료, 돌봄 및 지원, AVAMC에서 HIV 치료를 받는 데 있어 장벽과 촉진 요인에 대한 주제를 다루었습니다. 모든 인터뷰는 IDC의 개인실에서 진행되었으며 디지털 방식으로 녹음되었고 약 60분 동안 진행되었습니다. 이 연구는 에모리대학교 기관윤리심의위원회(IRB00060643)의 승인을 받았습니다.
Participants were eligible for the study if they were 18 years or older, first attended the IDC before January 2011, and were diagnosed as HIV positive. Study participants included two groups: patients currently receiving care at the IDC (in-care group) and patients who received at least 6 months of care at the IDC but had not attended a clinic visit for at least 8 months (out-of-care group). Patient records were screened to identify eligible participants due for a clinic appointment during the study period. Out-of-care patients were divided into quartiles by their time out of care and then purposively selected from each quartile. In-care patients were then selected to match out-of-care participants based on age, ethnicity, and gender. Participants were contacted by telephone and invited to participate in the study at their routine clinic appointment or a different time. Using clinic records enabled purposive diversity sampling by demographic and treatment retention characteristics; thereafter iterative recruitment was used to achieve diversity in other characteristics like employment. Data were collected from February to July 2013, through 25 in-depth interviews: 16 with those out of care and nine with those in care. A greater diversity of issues was raised in the out-of-care group which required more interviews to fully understand these issues. Interviews were conducted by researchers trained in qualitative research and experienced with HIV care and the AVAMC. Interviewers used a semistructured interview guide on the following topics: influence of military service on health care; HIV diagnosis; knowledge of HIV; HIV treatment, care, and support; and barriers and facilitators for receiving HIV care at the AVAMC. All interviews were conducted in a private room at the IDC, digitally recorded, and lasted approximately 60 minutes. The study was approved by Emory University Institutional Review Board (IRB00060643).
모든 인터뷰는 그대로 전사하고 비식별 처리한 후 정성적 데이터 분석을 위해 MaxQDA11 소프트웨어(1989-2016)에 입력했습니다. 모든 데이터에서 핵심 주제를 식별하고 설명하기 위해 주제별 분석을 사용했습니다. 여기에는 모든 녹취록을 읽고 두 명의 분석가가 확인한 참가자가 [제기한 문제를 식별]하고, 각 문제에 [코드명을 부여]하고, [코드북에 모든 코드와 코드 정의를 나열]하는 작업이 포함되었습니다. [코드북]에는 인터뷰 가이드의 주제에 따른 연역적 코드와 귀납적 내용 중심 코드가 모두 포함되었습니다. 코딩된 데이터의 일부에 대해 두 코더 간에 코더 간 일치도를 평가하고 전체 데이터 세트가 코딩되기 전에 코딩 불일치를 해결했습니다.
All interviews were transcribed verbatim, de-identified, and entered into MaxQDA11 software (1989-2016) for qualitative data analysis. We used thematic analysis to identify and describe core themes across all data. This involved reading all transcripts to identify issues raised by participants, which were verified by two analysts; giving each issue a code name; and listing all codes and code definitions in a codebook. The codebook included both deductive codes from topics in the interview guide and inductive content-driven codes. Intercoder agreement was assessed between two coders on a portion of coded data and coding discrepancies resolved before the entire data set was coded.
이러한 데이터의 포화도를 평가하기 위해 코드 개발과 관련된 추가 정보를 수집한 다음 이러한 추가 데이터에 대한 별도의 분석을 수행해야 했습니다. 이러한 추가 데이터와 분석은 다음 섹션에서 설명하며, 분석 방법에 대한 개요는 그림 1에 나와 있습니다.
To assess saturation in these data, we needed to collect additional information regarding code development and then conduct separate analyses of these additional data. These additional data and analyses are described in the subsequent sections, and an overview of analytic methods is shown in Figure 1.

코드 포화도 평가를 위한 데이터
Data for Assessing Code Saturation
코드 포화도를 평가하기 위해 인터뷰가 진행된 순서대로 인터뷰 녹취록을 검토하여 코드 개발 과정을 문서화했습니다. 각 인터뷰마다 코드 이름, 코드 정의, 코드 유형(귀납적 또는 연역적), 새 코드에 대한 참고 사항(예: 문제의 명확성, 코드 정의의 완전성), 이전에 개발된 코드가 인터뷰에 포함되었는지 여부 등 새로 개발된 코드와 코드 특성을 기록했습니다. 각 코드 정의에는 해당 코드가 포착한 문제에 대한 설명, 코드 적용 기준 및 예외 사항, 코드와 관련된 텍스트의 예가 포함되었습니다. 코드 개발의 진화를 파악하기 위해 이전 인터뷰에서 개발된 코드에 대한 변경 사항과 변경 사항의 성격, 각 변경 사항이 발생한 인터뷰 번호도 기록했습니다. 이러한 코드 개발 문서화와 반복적인 코드 개선 작업은 25개의 인터뷰가 모두 검토되고 코드북이 완성될 때까지 각 인터뷰에 대해 개별적으로 계속되었습니다.
To assess code saturation, we documented the process of code development by reviewing interview transcripts in the order in which they were conducted. For each interview, we recorded new codes developed and code characteristics, including the code name, code definition, type of code (inductive or deductive), any notes about the new code (e.g., clarity of the issue, completeness of the code definition), and whether any previously developed codes were present in the interview. Each code definition included a description of the issue it captured, criteria for code application and any exceptions, and an example of text relevant to the code. To identify the evolution of code development, we also recorded any changes made to codes developed in previous interviews, including the nature of the change and the interview number at which each change occurred. This documentation of code development and iterative refinement of codes continued for each interview individually until all 25 interviews were reviewed and the codebook was complete.
그런 다음 분석을 위해 코드를 다음과 같이 분류했습니다.
- 첫째, 코드는 귀납적 코드와 연역적 코드로 분류했습니다.
- 귀납적 코드는 내용 중심적이며 참가자들이 자발적으로 제기한 반면,
- 연역적 코드는 연구자 중심적이며 인터뷰 가이드에서 비롯된 것입니다.
- 둘째, 코드의 변경은 코드명 변경, 코드 정의 변경, 코드 병합, 코드 분할로 분류했습니다.
- 코드 정의 변경은 개념 확장, 예시 추가, 포함/제외 기준 수정, 부정적 요소 추가 등으로 다시 분류했습니다.
- 셋째, 코드도 구체적 코드와 개념적 코드로 분류했습니다.
- 구체적 코드는 데이터에서 명시적이고 명확한 문제를 포착하는 코드로,
- 예를 들어 '시간' 코드는 이동 시간, 대기 시간, 약속 시간 등 구체적인 문제를 포착합니다. 마찬가지로 '업무 약속' 코드는 장시간 근무, 교대 근무 또는 휴가 사용과 같은 명시적인 문제를 캡처했습니다.
- 개념적 코드는 지각, 감정, 판단 또는 느낌과 같은 추상적 구성을 포착하는 코드입니다.
- 예를 들어, 개념 코드 '바이러스에 대한 편안함'은 HIV에 대한 미묘한 태도, 자신감, 통제감을 포착하는 것으로, "나는 내가 HIV 양성인이라는 사실을 받아들였다. 나는 바이러스에 대해 좀 소극적인 것 같아요. 난 괜찮을 거야."
- 마찬가지로 '건강에 대한 책임감'이라는 개념 코드는 다음 문구에서 볼 수 있듯이 자신의 건강에 대해 책임을 지고 책임진다는 개념을 담고 있습니다: "아프면 뭔가 조치를 취해야 한다"(책임감) 또는 "HIV에 집중하지 않아서 ... 약을 먹지 않았다"(책임감 부족). 이러한 코드 분류는 코드 유형, 코드 개발 변경 유형, 코드 개발 시기를 정량화하여 결과에 보고될 패턴을 식별하는 데 사용되었습니다.
- 구체적 코드는 데이터에서 명시적이고 명확한 문제를 포착하는 코드로,
Codes were then categorized for analysis as follows.
- First, codes were categorized as inductive or deductive.
- Inductive codes were content-driven and raised by participants spontaneously, whereas
- deductive codes were researcher-driven and originated from the interview guide.
- Second, changes to codes were categorized as change in code name, change in code definition, code merged, and code split into separate codes.
- Code definition changes were further categorized as expanded conceptually, added examples, edited inclusion/exclusion criteria, and added negative component.
- Third, codes were also categorized as concrete or conceptual.
- Concrete codes were those capturing explicit, definitive issues in data;
- for example, the code “time” captured concrete issues such as travel time, waiting time, and appointment time. Similarly, the code “work commitments” captured explicit issues such as long hours, shift work, or getting time off work.
- Conceptual codes were those capturing abstract constructs such as perceptions, emotions, judgments, or feelings.
- For example, the conceptual code “comfort with virus” captures a subtle attitude toward HIV, a feeling of confidence, and a sense of control, as captured in this phrase: “I’ve embraced the fact that I am HIV positive . . . I guess I’m kinda passive to my virus . . . I’m gonna be OK.”
- Similarly, the conceptual code “responsibility for health” captures the concept of taking charge and being accountable for one’s own health, as shown in these phrases: “If you get sick you need to do something about it” (taking responsibility) or “I wasn’t focused on my HIV and . . . didn’t take medication” (lack of responsibility). These categorizations of codes were used to quantify the types of codes, types of changes to code development, and timing of code development to identify patterns that will be reported in the results.
- Concrete codes were those capturing explicit, definitive issues in data;
[코드 포화]가 인터뷰 기록을 검토하는 순서에 영향을 받는지 평가하기 위해 인터뷰 순서를 무작위로 지정하고, 가상의 코드 개발을 무작위 순서로 매핑한 다음, 이를 실제로 인터뷰 기록을 검토한 순서에 따른 코드 개발 결과와 비교했습니다. 이를 위해 먼저 난수 생성기를 사용하여 인터뷰 순서를 무작위로 정했습니다. 이미 동일한 인터뷰가 실제 순서대로 완료되었기 때문에 편향될 수 있으므로 코드 개발을 위해 녹취록을 검토하는 과정을 반복하지 않았습니다. 대신, 인터뷰 전체에 걸쳐 해당 주제가 동일한 횟수만큼 반복된 후에 코드가 개발될 것이라고 가정했습니다. 예를 들어, 실제 코드 개발에서 '약속을 잊어버림' 코드는 인터뷰 1과 3에서 이 문제가 언급된 후 세 번째 인터뷰에서 생성되었습니다. 따라서 무작위 순서로 '약속 잊음' 코드도 마찬가지로 이 주제가 두 번 언급된 후에 생성될 것이라고 가정했습니다. 이는 가상의 코드 개발이 실제 순서와 마찬가지로 연구자의 코드 개발 스타일을 무작위 순서에 반영하여 인터뷰 순서가 코드 개발에 미치는 영향을 보다 직접적으로 평가할 수 있도록 하기 위함이었습니다. 무작위 인터뷰의 코드 개발 패턴을 재현하기 위해 코드가 생성된 인터뷰 전에 코드가 코딩된 데이터에 적용된 인터뷰 횟수로 표시된 테마가 나타난 횟수를 계산했습니다. 그런 다음 이 숫자를 사용하여 무작위 인터뷰에서 가상의 코드 개발을 매핑했습니다. 이 계산은 모든 코드에 대해 수행되었으며 무작위 인터뷰의 코드 개발 매핑에 사용되었습니다.
To assess whether code saturation was influenced by the order in which interview transcripts were reviewed, we randomized the order of interviews, mapped hypothetical code development in the random order, and compared this with results from code development in the order in which interviews were actually reviewed. To do this, we first randomized interviews using a random number generator. We did not repeat the process of reviewing transcripts to develop codes, as this would be biased given that this process had already been completed with the same interviews in their actual order. Instead, we assumed that codes would be developed after the same number of repetitions of that theme across the interviews. For example, in actual code development, the code “forgot appointment” was created in the third interview, after this issue had been mentioned in Interviews 1 and 3. Thus, in the random order, we assumed that the “forgot appointment” code would likewise be created after two mentions of the theme. The aim here was that our hypothetical code development would reflect the researchers’ style of code development in the random order as in the actual order, so that we could assess the effect of interview order on code development more directly. We replicated the pattern of code development in the randomized interviews by calculating the number of times a theme was present (as indicated by the number of interviews in which the code was applied to the coded data) before the interview in which the code was created. We then used these numbers to map hypothetical code development in the randomized interviews. This calculation was done for all codes and was used to map code development in the randomized interviews.
의미 포화도 평가를 위한 데이터
Data for Assessing Meaning Saturation
코드 포화도에 도달하는 데 필요한 샘플 크기가 의미 포화도를 달성하기에 충분한지 평가하기 위해, [코드 포화]와 [개별 코드의 의미 포화]를 비교했습니다. 또한 코드의 유형이나 데이터에서 코드가 차지하는 비중이 어떤 코드의 포화에 영향을 미치는지도 평가했습니다.
To assess whether the sample size needed to reach code saturation was also sufficient to achieve meaning saturation, we compared code saturation with meaning saturation of individual codes. We also assessed whether the type of code or its prevalence in data influenced saturation of a code.
[의미 포화]를 파악하기 위해 원래 연구의 연구 질문에 중심이 되는, [구체적 코드와 개념적 코드](위에 정의된 대로)와 [고빈도 및 저빈도 코드](아래에 정의된 대로)가 혼합된 9개의 코드를 선택했습니다. 이러한 각 코드에 대한 궤적을 개발하여 연속적인 인터뷰를 통해 코드에 대해 알게 된 내용을 파악했습니다. 여기에는 코딩된 데이터를 사용하여 첫 번째 인터뷰에서 코드를 검색하고 설명된 문제의 다양한 차원을 기록한 다음, 두 번째 인터뷰에서 코드를 검색하고 설명된 새로운 차원을 기록한 다음, 25개의 인터뷰가 모두 검토될 때까지 이러한 방식으로 코드를 계속 추적하는 것이 포함되었습니다. 추적한 9개의 코드 모두에 대해 이 과정을 반복했습니다. [코드 궤적]을 사용하여 각 코드의 의미 포화도를 파악한 후, 추가 인터뷰에서는 코드에 대한 추가적인 차원이나 이해가 제공되지 않고 반복만 이루어졌습니다. 그런 다음 개별 코드의 [의미 포화]에 도달하는 데 필요한 인터뷰 횟수를 앞서 결정한 [코드 포화]와 비교했습니다.
To identify meaning saturation, we selected nine codes central to the research question of the original study and comprising a mix of concrete and conceptual codes (as defined above) and high- and low-prevalence codes (as defined below). We developed a trajectory for each of these codes to identify what we learned about the code from successive interviews. This involved using the coded data to search for the code in the first interview, noting the various dimensions of the issue described, then searching for the code in the second interview and noting any new dimensions described, and continuing to trace the code in this way until all 25 interviews had been reviewed. We repeated this process for all nine codes we traced. We used the code trajectories to identify meaning saturation for each code, whereby further interviews provided no additional dimensions or understanding of the code, only repetition of these. We then compared the number of interviews needed to reach meaning saturation for individual codes with code saturation determined earlier.
코드의 유형에 따라 포화도가 영향을 받는지 평가하기 위해 구체적 코드('시간', '기분 좋음', '충분한 약물', '업무 약속')의 코드 포화와 개념적 코드('바이러스에 대한 편안함', '사형 선고가 아님', '공개', '건강에 대한 책임', 'HIV 낙인')의 코드 포화를 비교했습니다. 마지막으로 코드 포화가 코드 빈도의 영향을 받는지 평가하기 위해 빈도가 높거나 낮은 코드별로 코드 포화도를 비교했습니다. [코드 빈도prevalence]는 [코드가 존재한 인터뷰의 수]로 정의했습니다. 평균적으로 14.5개의 인터뷰에 코드가 존재했기 때문에 고빈도 코드는 14.5개 이상의 인터뷰에 나타난 코드로, 저빈도 코드는 14.5개 미만의 인터뷰에 나타난 코드로 정의했습니다. 의미 포화도를 평가한 코드 중
- 고빈도 코드에는 "시간", "공개", "HIV 낙인", "건강에 대한 책임"이 포함되었고,
- 저빈도 코드에는 "건강함", "직장 생활", "충분한 약물", "바이러스에 대한 편안함", "사형 선고가 아님"이 포함되었습니다.
To assess whether saturation was influenced by the type of code, we compared code saturation for the concrete codes (“time,” “feel well,” “enough medications,” and “work commitments”) with saturation for the conceptual codes (“comfort with virus,” “not a death sentence,” “disclosure,” “responsibility for health,” and “HIV stigma”). Finally, to assess whether code saturation was influenced by code prevalence, we compared code saturation by high- or low-prevalence codes. Code prevalence was defined by the number of interviews in which a code was present. On average, codes were present in 14.5 interviews; thus, we defined high-prevalence codes as those appearing in more than 14.5 interviews and low-prevalence codes as those appearing in fewer than 14.5 interviews. Of the codes assessed for meaning saturation, the high-prevalence codes included “time,” “disclosure,” “HIV stigma,” and “responsibility for health,” whereas the low-prevalence codes included “feel well,” “work commitments,” “enough medications,” “comfort with virus,” and “not a death sentence.”
결과
Results
파트 1: 코드 포화도
Part I: Code Saturation
코드 개발
Code development
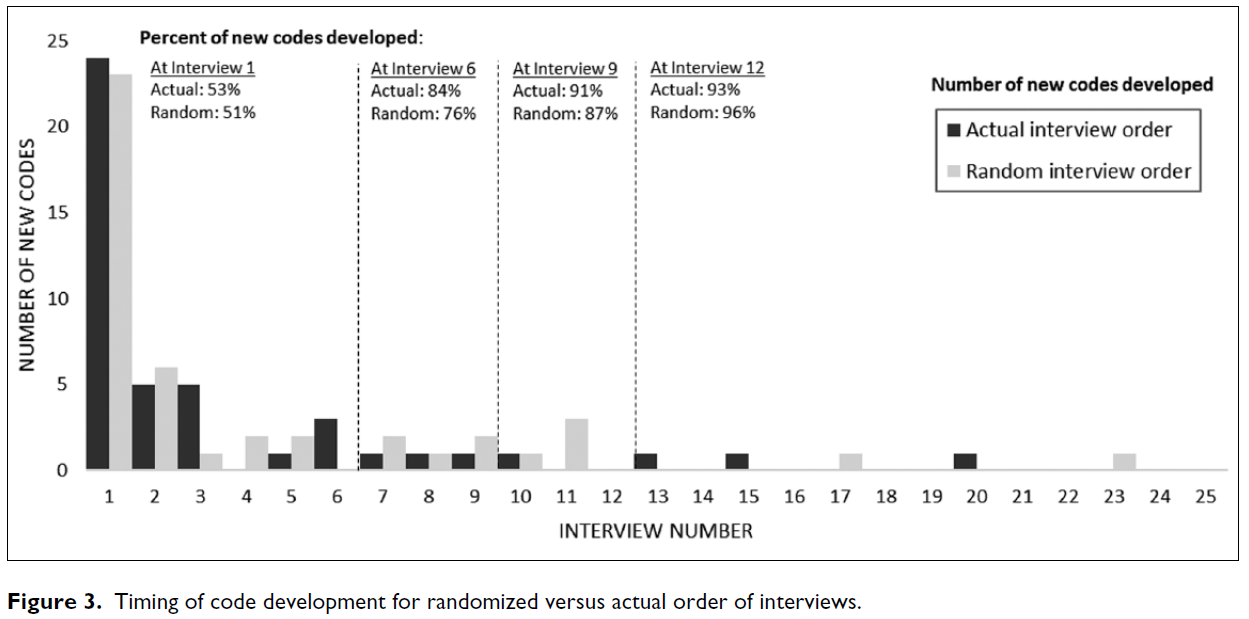
그림 2는 코드 개발 시기를 보여줍니다. 인터뷰가 진행된 순서, 개발된 코드의 유형(귀납적 또는 연역적), 코드가 개발된 연구 집단(치료 외 그룹 또는 치료 중인 그룹)에 따라 각 연속 인터뷰에서 개발된 새로운 코드의 수를 확인했습니다. 귀납적 코드와 연역적 코드 모두 인터뷰 1에서 개발되었으며 이후에는 귀납적 코드만 추가되었습니다. 이 연구에서는 총 45개의 코드가 개발되었으며, 이 중 절반 이상(53%)의 코드가 첫 번째 인터뷰에서 개발되었습니다. 인터뷰 2와 인터뷰 3에서는 각각 5개의 코드만 추가되었고, 인터뷰 6에서는 84%의 코드가, 인터뷰 9에서는 91%의 새로운 코드가 개발되었습니다. 나머지 16번의 인터뷰에서는 4개의 코드만 추가되었습니다(전체 코드의 8%). 인터뷰 9 이후에 개발된 4개의 코드는 이전 인터뷰에서 개발된 보다 구체적인 주제 코드에 비해 개념적인 코드('약물 휴가', '체계적 무관심', '사형 선고가 아님', '타인 돕기')였습니다. 치료 외 그룹 인터뷰가 완료된 16번 인터뷰까지 연구 코드의 98%를 개발했으며, 두 번째 연구 집단(치료 중 그룹)을 추가한 결과 이 그룹의 의료적 맥락은 다르지만 추가 코드는 단 하나에 불과했습니다.
Figure 2 shows the timing of code development. We identified the number of new codes developed from each successive interview in the order in which they were conducted, the type of code that was developed (inductive or deductive), and the study population in which codes were developed (out-of-care or in-care group). Both inductive and deductive codes were developed from Interview 1 and thereafter only inductive codes were added. A total of 45 codes were developed in this study, with more than half (53%) of codes developed from the first interview. Interviews 2 and 3 added only five additional codes each; by Interview 6, 84% of codes were identified, and by Interview 9, 91% of all new codes had been developed. The remaining 16 interviews yielded only four additional codes (8% of all codes). These four codes developed after Interview 9 were more conceptual codes (“drug vacation,” “systemic apathy,” “not a death sentence,” and “helping others”) compared with the more concrete topic codes developed in earlier interviews. By Interview 16, when out-of-care group interviews were completed, we had developed 98% of the codes in the study, and adding the second study population (in-care group) yielded only one additional code, despite the different health care context of this group of participants.

그림 2는 대부분의 코드가 가장 먼저 검토된 인터뷰로부터 개발되었음을 보여줍니다. 우리는 인터뷰를 검토하는 순서가 새로운 코드 개발 패턴에 영향을 미치는지, 특히 치료 외 그룹을 먼저 검토하는 것이 코드 개발에 영향을 미치는지 질문했습니다. 이를 평가하기 위해 무작위 인터뷰 순서로 개발된 신규 코드의 수와 실제 인터뷰를 검토한 순서에 따른 코드 개발 수를 비교했습니다. 그림 3은 무작위 인터뷰와 실제 인터뷰 검토 순서 모두에서 동일한 코드 개발 패턴이 나타났으며, 첫 번째 인터뷰에서는 여전히 절반 이상의 코드가 개발되었고 이후 인터뷰가 계속될수록 신규 코드 개발이 급격히 줄어드는 것을 보여줍니다. 두 시나리오 모두에서 여전히 대부분의 코드가 9번 인터뷰에 의해 개발되었습니다(실제 순서와 무작위 순서에서 각각 91%와 87%). 따라서 코드 개발을 위해 인터뷰를 검토하는 순서와 관계없이 초기 인터뷰가 대부분의 새로운 코드를 생성하는 동일한 패턴의 신규 코드 개발이 나타납니다.
Figure 2 shows that the majority of codes were developed from the very first interview reviewed. We asked whether the order in which interviews were reviewed had any influence on the pattern of new code development and in particular whether reviewing the out-of-care group first influenced code development. To assess this, we compared the number of new codes developed in our randomized interview order with code development in the actual order in which interviews were reviewed. Figure 3 shows that the same pattern of code development emerged in both the random and the actual order in which interviews were reviewed, whereby more than half of codes were still developed in the first interview and new code development tapers sharply with successive interviews. In both scenarios, the majority of codes were still developed by interview 9 (91% and 87% in the actual and random order, respectively). Thus, regardless of the order in which interviews are reviewed for code development, the same pattern of new code development is seen, whereby early interviews produce the majority of new codes.
코드 정의 변경 사항
Code definition changes
표 1은 코드 개발 과정에서 변경된 코드 정의를 보여줍니다. 20개의 코드 정의(44%)는 코드 개발 프로세스 내내 전혀 변경되지 않았습니다. 뚜렷한 패턴은 없었지만, 변경되지 않은 코드의 절반은 보다 구체적인 문제를 포착했거나 인터뷰 가이드에서 질문한 문제에서 직접 파생된 것으로서 사전에 정의하기가 더 쉬웠을 수 있습니다. 이러한 구체적/연역적 코드의 대부분은 코드 개발 프로세스 초기(인터뷰 6)에 개발되었으며 이후 인터뷰를 검토할 때 변경되지 않은 채로 남아있었습니다. 변경되지 않은 구체적인 코드의 예로는 'HIV에 대한 지식', 'HIV 치료 시작', '치료 중단', '치료 복귀', '수감', '충분한 약물 복용' 등이 있습니다. 변경되지 않은 다른 유형의 코드는 개념 코드, 특히 감정을 포착하는 코드였습니다. 이러한 유형의 변경되지 않은 코드는 일반적으로 코딩 과정 후반부(인터뷰 6 이후)에 개발되었는데, 아마도 문제의 성격이 더 완전히 이해된 후 데이터에 잘 맞는 보다 포괄적인 초기 코드 정의가 만들어져 변경할 필요가 없었기 때문일 것입니다. 이러한 문제는 이전 인터뷰에서도 존재했지만 더 많은 데이터를 검토할 때까지 명확성이 부족했을 수 있습니다. 이러한 변경되지 않은 개념 코드의 예로는 분노, 감사, HIV 거부, 공개, 전신적 무관심, 약물 휴가 등이 있습니다.
Table 1 shows changes to code definitions during the process of code development. Twenty code definitions (44%) did not change at all throughout the code development process. Although there were no strong patterns, we did note that half of the unchanged codes captured more concrete issues or were derived directly from issues asked on the interview guide, and thus may be easier to define up front. Most of these concrete/deductive codes were developed early in the code development process (by Interview 6) and remained unchanged when reviewing later interviews. Examples of unchanged concrete codes include “knowledge of HIV”, “HIV treatment initiated”, “time out of treatment”, “return to treatment”, “incarceration”, and “having enough medication”. The other type of code that remained unchanged were conceptual codes, particularly those capturing emotions. This type of unchanged code was generally developed later in the coding process (after Interview 6), possibly once the nature of the issue was more fully understood, resulting in more inclusive initial code definitions that fit data well, thus requiring no changes. These issues may have been present in earlier interviews but lacked clarity until more data were reviewed. Examples of these unchanged conceptual codes were anger, gratitude, denial of HIV, disclosure, systemic apathy, and drug vacation.

나머지 25개 코드의 경우, 총 63개의 코드 정의가 변경되었습니다(표 1 참조). 이 중 4분의 3(75%)이 귀납적 내용 중심 코드에 대한 변경이었지만, 연역적 코드에 대한 변경은 최초 개발 이후에도 계속 이루어졌습니다. 예상대로 코드 개발 프로세스 초기에 많은 정의 변경이 발생했습니다. 코드 정의 변경의 약 절반(49%)이 인터뷰 2~4(데이터 미표시)를 검토하는 동안 발생했고, 인터뷰 6에서 정의 변경의 78%, 인터뷰 9에서 정의 변경의 92%가 이루어졌습니다(데이터 미표시). 따라서 코드 정의는 9번의 인터뷰를 검토한 후 안정화되기 시작했습니다. 두 번째 연구 집단(치료 중인 그룹)의 인터뷰를 검토할 때 코드 정의에 대한 변경 사항은 거의 없었습니다. 따라서 처음에 첫 번째 연구 집단에서 인터뷰를 통해 개발하고 개선한 코드 구조와 정의는 두 번째 연구 집단에도 그대로 적용되었습니다.
For the remaining 25 codes, a total of 63 changes were made to the code definitions (see Table 1). Three quarters (75%) of these changes were made to inductive, content-driven codes; however, changes were still made to the deductive codes after their initial development. As expected, many definition changes occurred early in the code development process. About half (49%) of the changes to code definitions occurred while reviewing Interviews 2 to 4 (data not shown), 78% of definition changes were made by Interview 6, and 92% of definition changes were made by Interview 9 (data not shown). Thus, the code definitions began to stabilize after reviewing nine interviews. When reviewing interviews from the second study population (in-care group), there were very few changes to the code definitions. Therefore, the code structure and definitions initially developed and refined using interviews in the first study population remained applicable to the second study population.
표 1에는 코드 정의에 대한 변경 유형도 나와 있습니다. 코드 정의를 확장하고 코드 적용 매개변수를 세분화하는 두 가지 유형의 변경이 일반적이었습니다. 코드 정의 변경의 1/3(36%)은 포착된 문제의 다양한 측면을 더 포괄할 수 있도록 정의를 개념적으로 확장하는 것과 관련이 있었습니다. 이러한 유형의 변경은 주로 귀납적 내용 중심 코드에 이루어졌으며, 추가 인터뷰를 검토하고 특정 코드 내의 다양성이 드러나면서 개선되었기 때문에 일부 코드 정의는 이 과정을 통해 여러 번 변경되었습니다. 예를 들어, '너무 아픔' 코드는 처음에는 독감과 같은 일회성 신체 질환으로 인해 병원에 방문하지 못하는 경우를 포착하기 위해 정의되었지만, HIV 감염인 생활로 인한 누적된 피로와 피로, 그리고 여러 HIV 관련 건강 상태를 경험하여 병원 방문을 놓친 경우까지 포착하도록 확장되었습니다. 마찬가지로 '부작용' 코드는 처음에는 HIV 치료제 복용으로 인한 부작용 경험을 포착하기 위해 정의되었다가 부작용으로 인한 HIV 치료제 기피도 포함하도록 확장되었고, 이후에는 약을 복용하지 않아 증상을 피하기 위해 HIV 약을 복용하는 순응도까지 포착하도록 확장되었습니다.
Table 1 also shows the types of changes made to code definitions. Two types of changes were common: expanding the code definition and refining the parameters of code application. One third (36%) of changes to a code definition involved conceptually expanding the definition to be more inclusive of different aspects of the issue captured. This type of change was mostly made to inductive content-driven codes that were refined as further interviews were reviewed and the variation within specific codes was revealed; thus, some code definitions changed multiple times through this process. For example, the code “too sick” was initially defined to capture a one-off physical illness preventing clinic visits, such as a flu-like illness, but was expanded to also capture cumulative exhaustion and fatigue from living with HIV and experiencing multiple HIV-related health conditions that led to missed clinic visits. Similarly, the code “side effects” was initially defined to capture experiences of side effects from taking HIV drugs, then expanded to also include avoidance of HIV drugs due to the side effects caused, and then further expanded to capture compliance with taking HIV drugs to avoid symptoms from not taking these drugs.
두 번째로 흔한 변경 유형은 코드가 포착하는 문제의 예시 추가(25%), 포함 또는 제외 기준 구체화(10%), 정의에 부정적 요소 추가(16%) 등 코드 적용의 매개변수를 세분화하는 것이었습니다. 예를 들어, '지원 출처'의 코드 정의에 '지원 부족'을, 'HIV 낙인' 코드 정의에 'HIV 낙인 경험 없음'을 포함시켰습니다. 문제를 더 잘 반영하기 위해 코드명을 수정하거나 문제의 다른 구성 요소를 개별적으로 포착하기 위해 코드를 두 개의 개별 코드로 분리하는 등의 기타 코드 변경은 그다지 흔하지 않았습니다. 코드 정의를 좁히기 위해 변경된 코드는 없었습니다.
The second common type of change involved refining the parameters of code application, such as adding examples of the issue being captured by a code (25%), refining inclusion or exclusion criteria (10%), and adding negative components to a definition (16%). For example, we included lack of support in the code definition of “source of support,” and no experience of HIV stigma in the “HIV stigma” code definition. Other changes to codes were less common, such as editing the code name to better reflect the issue and splitting a code into two separate codes to capture different components of the issue separately. No codes were changed to narrow the code definition.
코드 빈도
Code prevalence
연구에서 가장 많이 사용된 코드가 언제 개발되었는지 알아보고자 했습니다. 그림 4는 각 코드를 별도의 막대로 표시합니다: X축에서 코드의 위치는 해당 코드가 어느 인터뷰에서 개발되었는지를 나타내며, 막대의 높이는 해당 코드가 사용된 인터뷰의 수를 나타냅니다. 예를 들어, 처음 4개의 막대는 이 4개의 코드가 인터뷰 1에서 개발되어 25개의 모든 인터뷰에서 사용되었음을 나타냅니다. 가로 점선은 이 연구에서 코드가 나타난 평균 인터뷰 횟수인 14.5회를 나타냅니다. 따라서 점선 위에 나타나는 코드는 데이터 세트 전체에서 평균보다 높은 빈도를 나타냅니다. 따라서 이 데이터에서 24개의 코드가 높은 유병률을 보였고 21개의 코드가 낮은 유병률을 보였습니다. 그림 4를 보면 고빈도 코드의 75%(18/24)는 첫 번째 인터뷰에서 이미 확인되었고, 87%(21/24)는 인터뷰 6에서, 92%(22/24)는 인터뷰 9에서 고빈도 코드가 개발되었음을 알 수 있습니다. 따라서 고빈도 코드의 대부분은 초기 인터뷰에서 확인되었습니다. 인터뷰 1 이후에 개발된 대부분의 코드는 데이터 세트 전체에서 그 빈도가 낮았습니다.
We wanted to determine when the most prevalent codes in the study were developed. Figure 4 represents each code as a separate bar: The location of a code on the x-axis indicates in which interview a code was developed, and the height of the bar indicates the number of interviews in which a code was used. For example, the first four bars indicate that these four codes were developed in Interview 1 and were used in all 25 interviews. The horizontal dashed line shows the average number of interviews in which a code appears in this study, which is 14.5 interviews. Thus, a code appearing above the dashed line has a higher than average prevalence across the data set as a whole. Thus, 24 codes were of high prevalence and 21 of low prevalence in these data. Figure 4 shows that 75% (18/24) of high-prevalence codes were already identified from the first interview, 87% (21/24) by Interview 6, and 92% (22/24) of high-prevalence codes were developed by Interview 9. Therefore, the vast majority of the high-prevalence codes are identified in early interviews. Most of the codes developed after Interview 1 were less prevalent across the data set.

그림 4는 또한 개발된 코드 유형(구체적 또는 개념적), 각 코드 유형이 개발된 시기, 그리고 이러한 데이터 전체에 걸쳐 다양한 유형의 코드가 얼마나 널리 퍼져 있는지를 보여줍니다. 이 그림에 따르면 첫 번째 인터뷰에서 개발된 코드의 4분의 3(18/24)이 구체적인 코드였으며, 첫 번째 인터뷰에서 개발된 코드의 25%만이 개념적인 코드였습니다. 인터뷰 6 이후에 개발된 코드는 주로 저빈도 코드였으며 거의 전적으로 개념적 코드(7/9, 78%)였고, 이러한 개념적 코드 중 43%(3/7)는 유병률이 높은 코드였습니다. 전반적으로 이 수치는
- [초기에 개발된 코드]는 [고빈도, 구체적 코드]인 반면,
- [나중에 개발된 코드]는 [저빈도, 개념적 코드]임을 보여 주지만,
연구의 후반 인터뷰에서는 빈도가 높고 개념적인 코드가 일부 개발되었습니다.
Figure 4 also shows the type of codes developed (concrete or conceptual), when each type of code was developed, and the prevalence of different types of codes across these data as a whole. This figure shows that three quarters (18/24) of codes developed from the first interview were concrete codes, with only 25% of codes from the first interview being conceptual. Codes developed after Interview 6 were mainly low-prevalence codes and were almost exclusively conceptual codes (7/9, 78%), with 43% (3/7) of these conceptual codes being high-prevalence codes. Overall, these figures show that codes developed early were high prevalence, concrete codes, while those developed later were less prevalent, conceptual codes, although some high prevalent, conceptual codes were developed in later interviews in the study.
코드 포화
Code saturation
코드 포화도를 결정하기 위한 선험적 임계값은 없었으며, 분석 결과에 따라 결정되었습니다. 코드 식별률(코드의 91%가 식별됨), 코드 유병률(유병률이 높은 코드의 92%가 식별됨), 코드집 안정성(코드 정의 변경의 92%가 이루어짐)의 조합을 기준으로 [9번의 인터뷰]를 통해 [코드 포화]에 도달했다고 판단했습니다. 이러한 데이터에서 제기된 새로운 이슈의 범위를 파악하는 데는 9번의 인터뷰로 충분했지만, 당시의 이슈를 단순히 개괄적으로 설명하는 것과 비교했을 때 제기된 모든 이슈를 완전히 이해하는 데도 9번의 인터뷰로 충분한지 질문했습니다. 9번의 인터뷰로도 데이터 전반에서 제기된 이슈의 의미 포화도에 도달할 수 있었을까요? 다음 섹션에서 이 질문에 대해 살펴보겠습니다.
We did not have an a priori threshold to determine code saturation; rather, it was determined based on results of our analysis. We determined that code saturation was reached at nine interviews based on the combination of
- code identification (91% of codes were identified),
- code prevalence (92% of high-prevalence codes were identified), and
- codebook stability (92% of code definition changes had been made).
Although nine interviews were sufficient to identify the range of new issues raised in these data, we asked whether nine interviews were also sufficient to fully understand all of the issues raised, compared with having simply outlined the issues at that point. Were nine interviews also sufficient to reach meaning saturation of the issues across data? We explore this question in the next section.
2부: 의미 포화
Part II: Meaning Saturation
의미 포화
Meaning saturation
2부에서는 9번의 인터뷰가 데이터에서 제기된 이슈를 포괄적으로 이해하기에 충분한지 평가합니다. 따라서 [코드 포화]와 [의미 포화] 사이의 일치 여부를 평가합니다. 이를 위해 연구의 각 연속적인 인터뷰에서 코드에 대해 얻은 정보를 기록하여 개별 인터뷰에서 코드에 대해 배운 내용을 더 자세히 파악하고 개별 코드가 의미 포화 상태에 도달하는 시점을 평가했습니다. 원래 연구의 연구 질문에 중심이 되는 9개의 코드를 추적했으며, 구체적 코드, 개념적 코드, 고빈도 또는 저빈도 코드를 혼합하여 포함했습니다. 표 2는 우리가 추적한 9개의 코드를 보여주며, 인터뷰를 통해 확인된 각 코드의 다양한 차원을 나열합니다. 의미 포화도는 새로운 코드 차원이 확인된 마지막 인터뷰에서 발생하는 것으로 결정되었습니다. 예를 들어,
- '기분 좋음' 코드는 인터뷰 1, 3, 4에서 확인된 5개의 차원으로 구성되어 있어 인터뷰 4에서 의미 포화 상태에 도달했고,
- '공개' 코드는 여러 인터뷰에서 확인된 13개의 차원으로 구성되어 있어 인터뷰 17에서 의미 포화 상태에 도달했습니다.
그림 5는 9개의 코드가 각각 언제 개발되었는지, 그리고 각 코드가 언제 의미 포화 상태에 도달했는지를 시각적으로 보여줍니다.
In Part II, we assess whether nine interviews were indeed sufficient to gain a comprehensive understanding of the issues raised in the data. Thus, we assess the congruence between code saturation and meaning saturation. To do so, we recorded the information gained about a code from each successive interview in the study, to identify in greater detail what we learn about a code from individual interviews and to assess when individual codes reach meaning saturation. We traced nine codes central to the research question of the original study and included a mix of concrete, conceptual, and high- and low-prevalence codes. Table 2 shows the nine codes we traced, listing the various dimensions of each code that were identified by interview. Meaning saturation was determined to occur at the last interview in which a novel code dimension is identified.
- As such, the code “feel well” comprises five dimensions that were identified from Interviews 1, 3, and 4; thus, it reached meaning saturation at Interview 4.
- The code “disclosure” has 13 dimensions, identified across numerous interviews, and it reached meaning saturation at Interview 17.
Figure 5 visually depicts when each of these nine codes was developed and when each code reached meaning saturation.
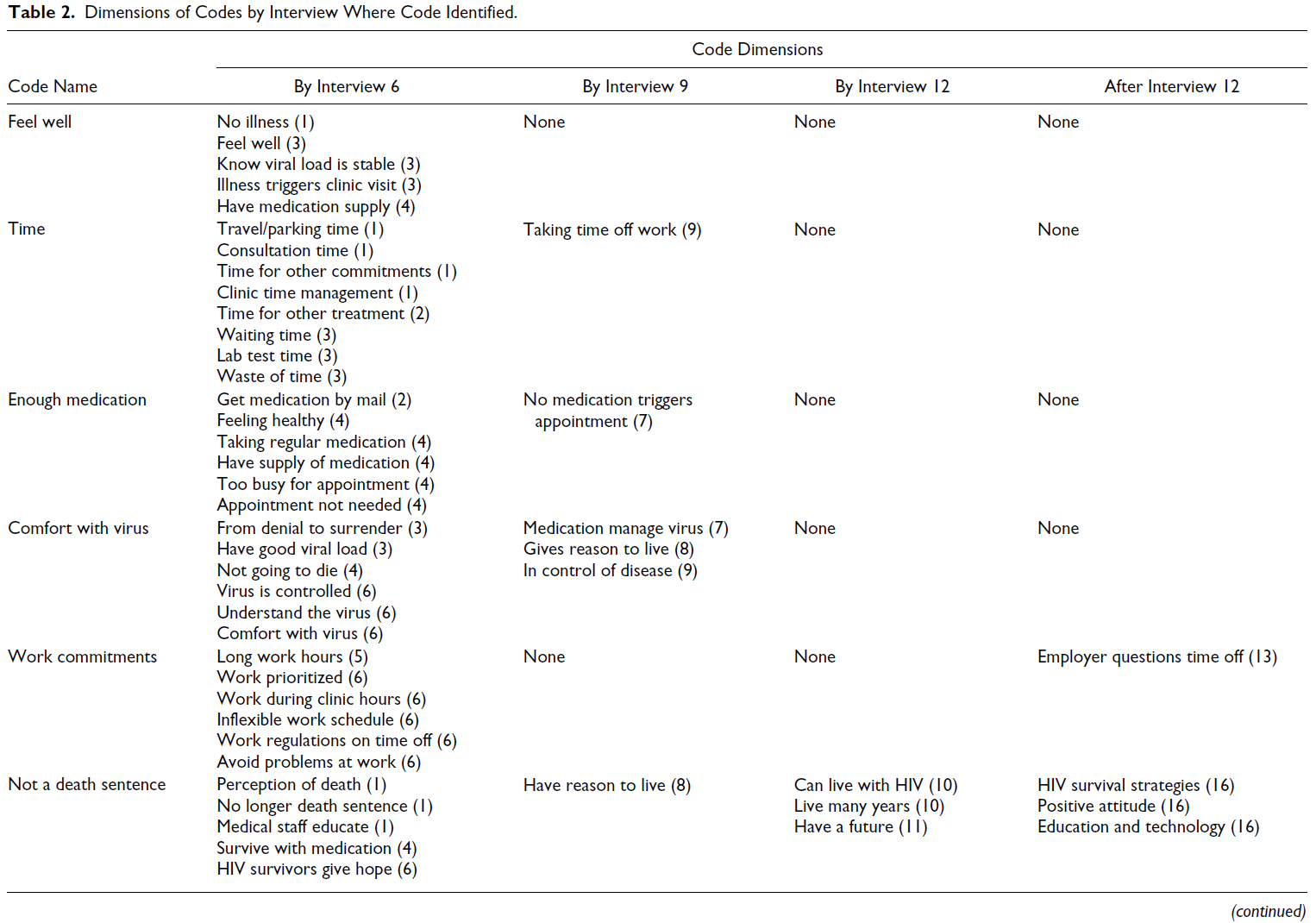

표 2는 초기 인터뷰에서 많은 차원의 코드가 포착되었음을 보여줍니다.
- 인터뷰 6에서는 이미 각 코드의 여러 차원이 식별되었으며, 이 시점에서 하나의 코드가 의미 포화 상태에 도달했습니다.
- 인터뷰 9와 12에서는 각 코드에 추가되는 새로운 차원이 줄어들고, 5개의 코드가 의미 포화 상태에 도달했습니다.
- 인터뷰 12 이후에도 여러 코드가 의미 포화 상태에 도달하지 않았으며, 마지막 인터뷰까지 여러 차원의 코드가 여전히 식별되고 있습니다.
따라서 9개의 인터뷰 표본 크기로는 일부 코드의 모든 차원을 파악할 수 있지만 다른 코드의 차원은 파악할 수 없는데, 이에 대해서는 아래에서 자세히 살펴봅니다.
Table 2 shows that many dimensions of codes are captured in early interviews.
- By Interview 6, multiple dimensions of each code are already identified, with one code reaching meaning saturation at this point.
- By Interviews 9 and 12, fewer new dimensions are added to each code, and five codes have now reached meaning saturation.
- After Interview 12, several codes have not reached meaning saturation, with multiple dimensions of codes still being identified until the last interview.
Therefore, a sample size of nine interviews is sufficient for capturing all dimensions of some codes but not others; we explore this further below.
표 2는 또한 의미 포화도에는 다양한 인터뷰가 필요하며, 다양한 인터뷰는 문제에 대한 포괄적인 이해를 위해 코드의 새로운 차원이나 뉘앙스에 기여한다는 점을 강조합니다.
- 예를 들어, '공개'라는 코드의 다양한 차원은 9개의 서로 다른 인터뷰를 통해 확인되었으며, 일부 인터뷰에서는 공개에 대한 여러 차원을 제공하기도 했습니다.
- '시간'과 같은 구체적인 코드의 경우에도 모든 차원을 완전히 포착하여 문제를 이해하려면 4가지 다른 인터뷰가 필요합니다.
따라서 처음에는 한 번의 인터뷰로 코드를 식별할 수 있지만, 문제를 완전히 이해하려면 코드의 모든 차원을 포착하기 위해 여러 번의 인터뷰가 필요합니다. 이는 포화를 평가할 때 코드가 단순히 식별되는 [코드 포화]를 넘어 더 많은 데이터가 필요한 [의미 포화](코드가 완전히 이해되는 의미 포화도)로 나아가야 할 수 있음을 의미합니다.
Table 2 also highlights that meaning saturation requires a range of interviews, with different interviews contributing a new dimension or nuance of the code toward a comprehensive understanding of the issue.
- For example, the various dimensions of the code “disclosure” were identified from nine different interviews, with some interviews providing several dimensions of disclosure.
- Even a concrete code such as “time” requires four different interviews to fully capture all dimensions and thus understand the issue.
Therefore, a code may be initially identified in one interview, but it requires multiple interviews to capture all dimensions of the code to fully understand the issue. This implies that assessing saturation may need to go beyond code saturation (whereby codes are simply identified) toward meaning saturation (where codes are fully understood), which requires more data.
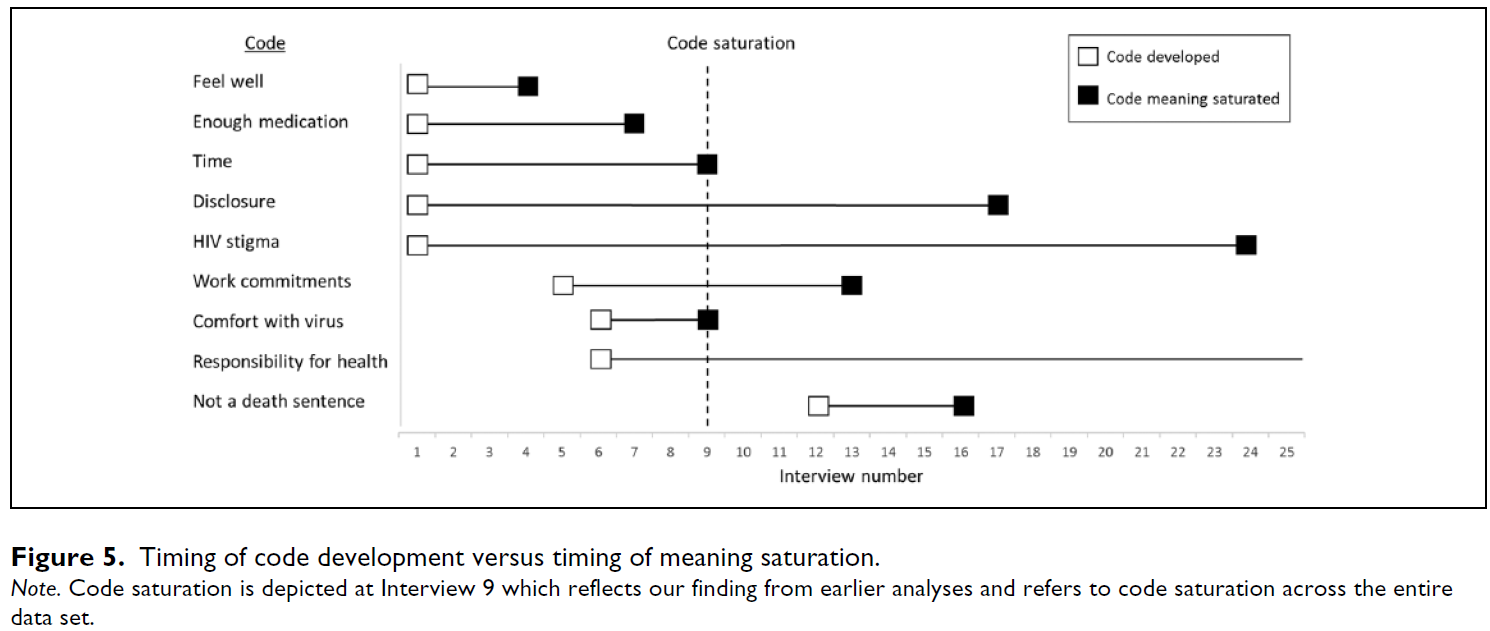
그림 5는 개별 코드가 데이터의 여러 지점에서 의미 포화에 도달했음을 보여줍니다.
- 일부 코드는 인터뷰 9에서 의미 포화도에 도달했지만, 다른 코드는 훨씬 늦게 또는 전혀 도달하지 못했습니다.
- 구체적인 문제를 나타내는 코드는 인터뷰 9에서 의미 포화도에 도달하거나 그보다 더 빨리 도달했습니다.
- 예를 들어, 구체적인 코드인 '기분 좋음', '충분한 약', '시간'은 각각 인터뷰 4, 7, 9에서 의미 포화도에 도달했습니다.
- 그러나 보다 개념적인 문제를 나타내는 코드는 데이터의 후반부인 인터뷰 16과 24 사이에 의미 포화도에 도달했습니다.
- 예를 들어, "사형 선고가 아님", "공개", "HIV 낙인" 코드는 각각 인터뷰 16, 17, 24에서 의미 포화도에 도달했습니다. '건강에 대한 책임' 코드는 마지막 인터뷰에서도 새로운 차원이 확인되었기 때문에 의미 포화 상태에 도달하지 않았습니다.
Figure 5 demonstrates that individual codes reached meaning saturation at different points in these data. While some codes reached meaning saturation by Interview 9, other codes reached meaning saturation much later or not at all. Codes representing concrete issues reached meaning saturation by Interview 9 or sooner. For example, the concrete codes “feel well,” “enough medications,” and “time” reached meaning saturation by Interviews 4, 7, and 9, respectively. However, codes representing more conceptual issues reached meaning saturation much later in the data, between Interviews 16 and 24. For example, the codes “not a death sentence,” “disclosure,” and “HIV stigma” reached meaning saturation by Interviews 16, 17, and 24, respectively. The code “responsibility for health” did not reach meaning saturation, as new dimensions were still identified at the last interview conducted.
또한 그림 5는 코드가 개발된 시점과 해당 코드의 모든 차원이 포착된 시점을 시각적으로 보여줌으로써 [코드 생성 후 각 코드를 완전히 이해하는 데 필요한 추가 인터뷰 횟수]를 강조합니다(가로선의 길이로 표시됨). 이는 [개념적 코드]의 모든 차원을 완전히 이해하려면 [구체적 코드]를 완전히 이해하는 것보다 훨씬 더 많은 데이터가 필요하다는 점을 강조합니다. 예를 들어,
- '기분 좋음'이라는 [구체적 코드]는 모든 차원을 파악하는 데 4번의 인터뷰만 필요했지만,
- '공개'라는 개념적 코드는 여러 차원을 파악하는 데 17번의 인터뷰가 필요했습니다.
일부 [개념적 코드]의 경우, 해당 코드의 구체적인 차원을 조기에 파악할 수 있는 반면, 추상적인 차원일수록 [모든 차원]을 파악하기 위해 더 많은 데이터가 필요합니다.
- 예를 들어, 'HIV 낙인' 코드의 경우, 초기 인터뷰에서는 구체적인 유형의 낙인을 파악할 수 있지만, 자기 낙인, 낙인으로 인한 스트레스, HIV로 인한 사망에 대한 낙인, 낙인을 피하기 위한 HIV 상태 공개 등 보다 미묘한 차원의 낙인을 파악하려면 더 많은 데이터가 필요합니다(표 2 참조).
요약하자면, 9개의 표본 크기는 이러한 데이터의 [구체적 코드]를 이해하는 데는 충분하지만, 이러한 [개념적 코드]나 구체적인 코드의 [개념적 차원을 완전히 이해]하기에는 충분하지 않습니다.
Figure 5 also visually depicts the point at which a code was developed and the point at which all dimensions of that code were captured, thus highlighting the number of additional interviews after code creation that are needed to gain a full understanding of each code (as depicted by the length of the horizontal line). This highlights that fully understanding all dimensions of conceptual codes requires much more data than fully understanding concrete codes. For example, the concrete code “feel well” required only four interviews to identify all its dimensions, whereas the conceptual code “disclosure” required 17 interviews to identify its multiple dimensions. For some conceptual codes, the more tangible concrete dimensions of that code are captured early, whereas the more abstract dimensions require more data to capture all dimensions. For example, in the code “HIV stigma”, the concrete types of stigma are identified from early interviews, but more data are required to reveal the more nuanced dimensions of stigma such as self-stigma, stress of stigma, stigma of dying from HIV, and disclosure of HIV status to avoid stigma (see Table 2). In sum, a sample size of nine would be sufficient to understand the concrete codes in these data, but it would not be sufficient to fully understand conceptual codes or conceptual dimensions of these concrete codes.
의미 포화도가 데이터에서 코드의 유병률이 높은지 낮은지에 따라 영향을 받는지 질문했지만 코드 빈도에 따른 명확한 패턴은 발견되지 않았습니다. 그림 5에서 '시간', '공개', 'HIV 낙인', '건강에 대한 책임'의 고빈도 코드는 9번과 24번 인터뷰 사이에 의미 포화도에 도달하거나 포화도에 도달하지 않았습니다. 저빈도 코드는 인터뷰 6과 16 사이에 의미 포화 상태에 도달했습니다. 이는 데이터에서 더 자주 발견되는 코드가 덜 자주 발견되는 코드보다 문제를 이해하는 데 더 적은 수의 인터뷰가 필요하지 않을 수 있음을 시사합니다. 이 데이터에서는 고빈도 코드와 저빈도 코드 모두 원래 연구의 연구 질문에 똑같이 중요했습니다.
We asked if meaning saturation is influenced by whether a code is of high or low prevalence in these data but found no clear patterns by code prevalence. In Figure 5, high-prevalence codes of “time,” “disclosure,” “HIV stigma,” and “responsibility for health” reached meaning saturation between Interviews 9 and 24 or did not reach saturation. Low-prevalence codes reached meaning saturation between Interviews 6 and 16. This suggests that codes found more frequently in data may not require fewer interviews to understand the issue than codes found less frequently. In these data, both the high- and low-prevalence codes were equally important for the research question of the original study.
토론
Discussion
이 연구는 질적 연구의 포화를 평가하는 제한된 방법론 연구에 기여합니다. 우리는 포화도에 대한 두 가지 접근 방식, 각 접근 방식별로 포화도에 도달하는 데 필요한 샘플 크기, 코드의 특성이 포화도에 영향을 미치는지 여부를 문서화하고자 했습니다. 그 결과를 사용하여 포화도에 도달하기 위한 샘플 크기에 영향을 미치는 매개변수를 개발했습니다.
This study contributes to a limited body of methodological research assessing saturation in qualitative research. We sought to document two approaches to saturation, the sample sizes needed to reach saturation for each approach, and whether the nature of codes influences saturation. We used our results to develop parameters that influence sample sizes for reaching saturation.
그 결과 9번의 인터뷰 끝에 [코드 포화에 도달]했으며, 두 번째 연구 모집단을 추가한 후에도 포화도는 변하지 않았습니다. 또한 [첫 번째 인터뷰]가 신규 코드의 절반 이상(53%)과 고빈도 코드의 4분의 3(75%)을 차지했으며, 포화 상태에 이를 때까지 후속 인터뷰가 각각 몇 개의 신규 코드를 추가한 것으로 나타났습니다. 따라서 9번의 인터뷰를 통해 공통적인 주제별 이슈의 범위가 파악되었고 코드북이 안정화되었습니다. 이러한 결과는 7~12개의 인터뷰 사이에 데이터 포화 상태가 발생하고, 인터뷰 1과 6 사이에 주제의 기본 요소가 많이 존재한다는 것을 확인한 Guest 등(2006)의 연구 결과와 매우 유사합니다. 또한 우리의 연구 결과는 원하는 포화도에 따라 8~16개의 인터뷰 사이에 포화도가 발생한다는 것을 확인한 Namey, Guest, McKenna, Chen(2016)의 연구 결과와도 일치합니다. 그러나 본 연구는 Guest 등이 수행한 것처럼 6개의 일괄 인터뷰가 아닌 개별 인터뷰에서 개발된 코드를 묘사함으로써 이전 연구보다 더 높은 정밀도를 제공하므로 코드 개발에 대한 첫 번째 인터뷰의 중요한 기여도를 파악하고 코드 포화의 시기와 궤적을 더 정확하게 지정할 수 있습니다.
Our results show that code saturation was reached after nine interviews; even after adding the second study population, saturation was not altered. We also show that the first interview conducted contributed more than half (53%) of new codes and three quarters (75%) of high-prevalence codes, with subsequent interviews adding a few new codes each until saturation. Thus, by nine interviews, the range of common thematic issues was identified, and the codebook had stabilized. These results are remarkably similar to those of Guest et al. (2006), who identified that data saturation occurred between seven and 12 interviews, with many of the basic elements of themes present between Interviews 1 and 6. Our findings also concur with Namey, Guest, McKenna, and Chen (2016), who identified that saturation occurred between eight and 16 interviews, depending on the level of saturation sought. However, our study provides greater precision than previous work by delineating codes developed in individual interviews (rather than in batches of six as done by Guest et al.); thus, we identify the significant contribution of the first interview to code development and specify the timing and trajectory of code saturation more precisely.
[코드 포화]는 [데이터 수집 중에 연구 주제와 관련된 이슈의 범위가 파악되고 더 이상 새로운 이슈가 발생하지 않는다]고 주장하여 포화도를 평가하는 데 자주 사용됩니다. 그러나 연구 결과에 따르면 [코드 포화]에 도달하는 것만으로는 충분하지 않을 수 있습니다. [코드 포화]는 문제를 식별하고 강력한 코드북으로 이어질 수 있지만, 이러한 문제를 완전히 이해하려면 더 많은 데이터가 필요합니다. 포화에 영향을 미치는 것은 이슈의 존재 여부나 빈도뿐만 아니라 이슈를 이해하는 데 도움이 되는 이슈에서 파생된 데이터의 풍부함입니다(Emmel, 2015; Morse, 1995):
Code saturation is often used during data collection to assess saturation, by claiming that the range of issues pertinent to the study topic have been identified and no more new issues arose. However, our results show that reaching code saturation alone may be insufficient. Code saturation will identify issues and lead to a robust codebook, but more data are needed to fully understand those issues. It is not only the presence or frequency of an issue that contributes to saturation but more importantly the richness of data derived from an issue that contributes to understanding of it (Emmel, 2015; Morse, 1995):
[포화도에 대한 잘못된 생각]은 연구자가 "모든 것을 다 들었을 때" 데이터가 포화 상태가 된다는 것입니다. 이 기준은 단독으로 사용할 경우 부적절하며 연구 중인 주제에 대한 이해가 얕을 수 있습니다. (모스, 2015, 587쪽)
[A] mistaken idea about saturation is that data become saturated when the researcher has “heard it all” . . . When used alone, this criterion is inadequate and may provide a shallow . . . understanding of the topic being studied. (Morse, 2015, p. 587)
따라서 [코드 포화]는 주요 탐구 영역에 대한 개요를 제공하기 때문에 [적은 수의 인터뷰]로 도달할 수 있지만, 관심 있는 현상을 이해하는 데 중요한 의미를 지닌 데이터의 깊이, 풍부함, 복잡성을 제공하려면 [더 많은 데이터]가 필요합니다.
Thus, code saturation may be reached with few interviews as it provides an outline of the main domains of inquiry, but further data are needed to provide depth, richness, and complexities in data that hold important meaning for understanding phenomena of interest.
이번 연구에서 가장 설득력 있는 결과는 [의미 포화]를 평가하는 두 번째 접근 방식과 다른 연구에서 평가되지 않은 [코드 특성이 의미 포화에 미치는 영향]과 관련이 있을 것입니다. 연구 결과에 따르면 코드는 균일하지 않고 서로 다른 지점에서 의미 포화도에 도달하거나 포화도에 도달하지 않는 것으로 나타났습니다.
- 일부 코드의 경우 코드 포화도에 도달하는 것만으로도 의미 포화도를 달성할 수 있었지만,
- 다른 코드의 경우 문제를 완전히 이해하려면 훨씬 더 많은 데이터가 필요했습니다.
- [고빈도 구체적 코드]는 일반적으로 초기 인터뷰에서 식별되었으며 [9번의 인터뷰 또는 그 이전]에 의미 포화 상태에 도달하는 것으로 나타났습니다.
- 그러나 후기 인터뷰에서 확인된 코드는 [저빈도 개념적 코드]로, 의미 포화 상태에 도달하기 위해 [16~24회의 인터뷰]를 통해 더 많은 데이터가 필요했거나 의미 포화 상태에 도달하지 못했습니다.
Perhaps the most compelling results of our study relate to our second approach of assessing meaning saturation and how code characteristics influence meaning saturation, which has not been assessed in other studies. Our results show that codes are not uniform; rather, they reach meaning saturation at different points or do not reach saturation.
- For some codes, reaching code saturation was also sufficient to achieve meaning saturation,
- but for other codes, much more data were needed to fully understand the issue.
- We found that high-prevalence concrete codes were typically identified in early interviews and reached meaning saturation by nine interviews or sooner.
- However, codes identified in later interviews were low-prevalence conceptual codes that required more data to reach meaning saturation, between 16 and 24 interviews, or they did not reach meaning saturation.
따라서 코드 포화도에서 제안하는 [9개의 표본 크기]는 데이터의 명시적인 구체적인 문제를 포괄적으로 이해하는 데만 충분할 뿐, 훨씬 더 많은 데이터가 필요한 구체적인 코드의 미묘한 개념적 문제와 개념적 차원을 놓칠 수 있습니다. 이를 고려하는 또 다른 방법은 코드를 이해하려면 [다양한 인터뷰]가 필요하며, [다양한 인터뷰]는 문제에 대한 완전한 이해를 구축하는 새로운 차원에 기여한다는 것입니다. 구체적 코드의 경우에도 모든 차원을 이해하려면 4~9개의 인터뷰가 필요하지만, 개념적 코드는 그 의미를 완전히 파악하기 위해 훨씬 더 많은 데이터(즉, 4~24개의 인터뷰)가 필요합니다. 따라서 하나의 코드가 한 인터뷰에서 식별되어 다른 인터뷰에서 반복될 수 있지만, 이를 완전히 이해하려면 문제의 모든 차원을 파악하기 위해 추가 인터뷰가 필요합니다. 이러한 결과는 [코드를 식별하는 것 이상으로 더 많은 데이터를 수집]하고 '모든 것을 들었는지'가 아니라 '모든 것을 이해했는지'를 물어야만 데이터 포화 상태라고 주장할 수 있다는 점을 강조합니다. 또한 의미 포화도를 달성하려면 반복적인 샘플링 프로세스를 사용하여 데이터의 다양성, 명확성 및 깊이를 모니터링하고 이해도가 낮은 참가자 또는 도메인에 데이터 수집을 집중해야 합니다.
Thus, a sample size of nine—as suggested by code saturation—would only be sufficient to develop a comprehensive understanding of explicit concrete issues in data and would miss the more subtle conceptual issues and conceptual dimensions of concrete codes, which require much more data. Another way to consider this is that understanding any code requires a range of interviews, with different interviews contributing new dimensions that build a complete understanding of the issue. Even concrete codes required between four and nine interviews to understand all dimensions; however, conceptual codes required an even greater range of data (i.e., between 4 and 24 interviews) to fully capture their meaning. Therefore, a code may be identified in one interview and repeated in another, but additional interviews are needed to capture all dimensions of the issue to fully understand it. These findings underscore the need to collect more data beyond the point of identifying codes and to ask not whether you have “heard it all” but whether you “understand it all”—only then could data saturation be claimed. Achieving meaning saturation also necessitates using an iterative process of sampling to monitor diversity, clarity, and depth of data, and to focus data collection on participants or domains that are less understood.
코드 사용률에 따른 포화도 패턴은 발견되지 않았습니다. 데이터에서 더 자주 언급된 이슈는 덜 자주 언급된 이슈보다 의미 포화도에 더 빨리 도달하지 않았습니다. 따라서 코드 유병률은 해당 이슈의 의미가 언제 도달할 수 있는지를 알려주지 않기 때문에 포화도를 나타내는 강력한 지표가 아닙니다. "중요한 것은 주제와 관련된 데이터가 발생하는 빈도가 아니라 특정 데이터 세그먼트가 유익한 분석 논거를 개발하고 테스트할 수 있는지 여부"이기 때문에 이는 놀라운 일이 아닙니다(Hammersley, 2015, p.688). 즉, 빈도가 높은 코드가 대부분 식별되었다고 해서 반드시 중요한 문제가 포착된 것과 동일시해서는 안 됩니다. 빈도가 낮은 코드도 데이터의 주제를 이해하는 데 똑같이 기여할 수 있으며, 따라서 빈도가 아니라 이해에 기여하는 정도가 중요해집니다. Morse(2015)는 데이터가 정상 곡선을 따라 발생하며, 일반적인 데이터는 중간에, 덜 일반적인 데이터는 곡선의 꼬리에 위치한다는 점을 강조하여 이를 잘 설명했습니다. 하지만
We found no pattern of saturation by code prevalence. Issues raised more frequently in data did not reach meaning saturation sooner than issues mentioned less frequently. Therefore, code prevalence is not a strong indicator of saturation, as it provides no indication of when the meaning of that issue may be reached. This should not be surprising because “it is not so much the frequency with which data relevant to a theme occurs that is important but rather whether particular data segments allow a fruitful analytic argument to be developed and tested” (Hammersley, 2015, p.688). Code prevalence should also not be equated with code importance; in other words, if most high-prevalence codes have been identified, this does not necessarily equate to important issues having been captured. Less prevalent codes may contribute equally to understanding themes in data; thus, they become important not for their frequency but for their contribution to understanding. Morse (2015) described this well by highlighting that data accrue along a normal curve, with common data in the middle and less common data at the tails of the curve. However,
질적 조사에서는 곡선의 꼬리에 있는 데이터도 똑같이 중요합니다. 곡선의 중앙에 있는 데이터가 덜 일반적인 데이터를 압도하고 꼬리에 있는 똑같이 중요한 데이터를 무시할 위험이 있습니다. (p. 587)
in qualitative inquiry, the data at the tails of the curve are equally important . . . The risk is that the data in the center of the curve will overwhelm the less common data, and we will ignore the equally significant data at the tails. (p. 587)
따라서 빈도가 높은 코드를 포착하여 포화도를 정당화하는 것은 포화도의 요점을 놓치는 것이며, [의미 포화]를 추구하면 곡선을 평평하게 만들어 현상 이해에 기여할 수 있는 코드의 잠재력을 동등하게 취급할 수 있습니다. 이는 포화도를 주장할 때 [코드의 빈도를 계산]하는 것이 아니라, [코드의 의미를 포착]했음을 입증하는 것이 중요하다는 점을 강조합니다.
Therefore, justifying saturation by capturing high-prevalence codes misses the point of saturation; striving for meaning saturation flattens the curve to treat codes equally in their potential to contribute to understanding phenomena. This stresses the importance of demonstrating that the meaning of codes were captured instead of counting the prevalence of codes when claiming saturation.
연구 결과는 [포화가 여러 매개변수의 영향을 받는다]는 점을 강조합니다(그림 6). 이러한 매개변수는 연구 제안서에서 특정 연구에 선험적으로 필요한 표본 크기를 추정하는 데 사용할 수 있으며, 포화도를 평가하고 달성한 근거를 입증하여 사용된 표본 크기를 정당화하는 데 사용할 수도 있습니다. 각 매개변수는 지렛대 역할을 하며 특정 연구의 맥락에서 '가중치'를 부여해야 합니다. 따라서 표본 크기는 단일 매개변수 단독이 아닌 [모든 매개변수의 영향력을 합산]하여 결정됩니다. 예를 들어, 일부 매개변수가 포화도에 대해 더 작은 표본을 나타내고 다른 매개변수가 더 큰 표본을 제안하는 경우, 결합된 영향력을 고려하면 중간 표본 크기가 필요하다는 것을 알 수 있습니다.
Our results highlight that saturation is influenced by multiple parameters (Figure 6). These parameters can be used in a research proposal to estimate sample sizes needed a priori for a specific study or they can be used to demonstrate the grounds on which saturation was assessed and achieved thereby justifying the sample size used. Each parameter acts as a fulcrum and needs to be “weighed up” within the context of a particular study. A sample size is thus determined by the combined influence of all parameters rather than any single parameter alone. For example, where some parameters indicate a smaller sample for saturation and others suggest a larger sample, the combined influence would suggest the need for an intermediate sample size.

- 연구 목적이 포화도에 영향을 미칩니다. 코드 포화도는 9번의 인터뷰로 도달할 수 있으며, 이는 광범위한 주제에 대한 개요를 제시하거나 설문조사 도구의 항목을 개발하는 것을 목표로 하는 연구에는 충분할 수 있지만 복잡한 현상을 이해 또는 설명하거나 이론을 개발하기 위해 의미 포화도가 필요한 경우에는 더 많은 표본이 필요합니다.
- 연구 모집단의 특성은 포화도에 영향을 미칩니다. 본 연구에는 특정 클리닉에서 HIV 치료를 받는 퇴역군인의 비교적 동질적인 표본이 포함되었지만, 연구 집단이 더 다양하다면 코드와 의미 포화도를 모두 달성하기 위해 더 큰 표본 크기가 필요할 것으로 예상됩니다.
- 사용된 샘플링 전략이 포화도에 영향을 미칠 수 있는데, 반복 샘플링은 고정 모집 기준을 사용하는 것보다 포화도에 도달하기 위해 더 작은 표본이 필요할 수 있지만, 반복 샘플링은 궁극적으로 표본 크기를 확장하는 새로운 데이터 소스를 발견할 수도 있습니다. 따라서 샘플링 전략에 따라 표본 크기에 서로 다른 영향을 미칠 수 있습니다.
- 데이터 품질은 포화도에 영향을 미치는데, '두꺼운' 데이터는 '얇은' 데이터보다 더 깊고 풍부한 인사이트를 제공하지만, 연구 목표에 부합한다면 후자의 데이터로도 코드 포화를 달성하기에 충분할 수 있습니다.
- 개발된 코드의 유형은 포화도에 영향을 미칩니다. 데이터에서 명시적이고 구체적인 문제를 포착하려면 더 작은 샘플이 필요하고, 미묘하거나 개념적인 문제를 포착하려면 훨씬 더 큰 샘플이 필요하다는 것을 보여줍니다.
- 코드북의 복잡성과 안정성은 포화도에 영향을 미칩니다. 코드북에는 명시적, 미묘한, 개념적 코드를 포함한 광범위한 코드가 포함되어 있어 일부 코드는 안정화되어 포화 상태에 도달한 반면, 다른 코드의 차원은 25번의 인터뷰에서도 여전히 나타나고 있었습니다.
- 마지막으로, 포화의 목표와 초점이 포화에 도달하는 위치에 영향을 미쳤습니다. 연구 결과는 '포화 상태에 도달하는 것'이 일률적인 성과가 아님을 보여줍니다. [코드 포화]에 도달하는 것은 [의미 포화]에 도달하는 것과는 다르며, 각각 다른 샘플 크기가 필요합니다. 개별 코드도 데이터의 다른 지점에서 포화에 도달하며, 원하는 포화의 전체 비율은 연구 또는 연구자마다 다를 수 있습니다(예: 80% 대 90%).
따라서 포화의 목표(예: 핵심 코드 또는 전체 데이터), 포화의 초점(예: 코드 포화 또는 의미 포화), 원하는 포화 수준(예: 80%, 90%)을 파악하면 샘플 크기가 결정되고 포화가 달성되는 지점을 결정할 때 더 큰 뉘앙스를 제공합니다.
- The study purpose influences saturation. We show that code saturation may be reached at nine interviews, which may be sufficient for a study aiming to outline broad thematic issues or to develop items for a survey instrument, but a larger sample is needed if meaning saturation is needed to understand or explain complex phenomena or develop theory.
- Characteristics of the study population influence saturation. Our study included a relatively homogeneous sample of veterans receiving HIV care at a specific clinic, but we anticipate a larger sample size would be needed to achieve both code and meaning saturation if the study population were more diverse.
- The sampling strategy used may influence saturation, whereby iterative sampling may require a smaller sample to reach saturation than using fixed recruitment criteria; however, iterative sampling may also uncover new data sources that ultimately expand the sample size. Thus, sampling strategies may have differing influences on sample size.
- Data quality influences saturation, as “thick” data provide deeper, richer insights than “thin” data; however, the latter may be sufficient to achieve code saturation if that aligns with the study goals.
- The type of codes developed influences saturation. We show that a smaller sample is needed to capture explicit, concrete issues in our data, and a much larger sample is needed to capture subtle or conceptual issues.
- The complexity and stability of the codebook influences saturation. Our codebook included a broad range of codes, including explicit, subtle, and conceptual codes; therefore, some codes stabilized and reached saturation, while dimensions of other codes were still emerging at 25 interviews.
- Finally, the goal and focus of saturation influence where saturation is achieved. Our results show that “reaching saturation” is not a uniform accomplishment. Achieving code saturation is different from reaching meaning saturation, and each requires different sample sizes. Individual codes also reach saturation at different points in the data, and overall percentage of saturation desired may differ between studies or researchers (e.g., 80% vs. 90%).
Therefore, identifying the goal of saturation (e.g., in core codes or in all data), the focus of saturation (e.g., code saturation or meaning saturation), and the level of saturation desired (e.g., 80%, 90%) also determines the sample size and provides greater nuance in determining where saturation is achieved.
포화를 평가하는 것은 처음에 보이는 것보다 더 복잡합니다. 연구자는 포화를 평가하는 과정, 포화에 도달한 매개변수, 포화에 도달하지 못한 매개변수 및 그 이유에 대해 보다 미묘한 설명을 제공해야 합니다. 이 선언을 한계로 간주해서는 안 되며, 포화 평가에 대한 연구자의 관심과 특정 연구에 어떻게 적용되는지에 대한 인식을 나타내는 지표로 간주해야 합니다.
Assessing saturation is more complex than it appears at the outset. Researchers need to provide a more nuanced description of their process of assessing saturation, the parameters within which saturation was achieved and where it was not achieved and why. This declaration should not be viewed as a limitation but an indicator of researchers’ attention to assessing saturation and awareness of how it applies to a particular study.
연구의 한계
Study Limitations
의미 포화 분석은 다양한 코드를 대상으로 수행되었지만, 본 연구에서 모든 코드가 이 분석에 사용된 것은 아닙니다. 발견한 패턴이 다른 연구 데이터에서도 재현될 수 있는지 확인하기 위해 추가적인 방법론적 연구를 권장합니다. 또한 다른 유형의 질적 연구보다 연구 목적과 연구 참여자가 더 명확하게 정의될 수 있는 응용 질적 연구의 데이터를 사용하여 포화를 평가했습니다. 따라서 본 연구 결과를 다른 유형의 데이터나 질적 연구 접근 방식에 대한 일반적인 것으로 간주해서는 안 됩니다. 마지막으로, 질적 연구자는 코드 개발 스타일(예: 광범위한 코드 또는 특정 코드)이 다를 수 있으며, 본 연구 결과도 코드 개발 스타일을 반영할 수 있습니다.
Our analysis of meaning saturation was conducted on a diverse range of codes, but not all codes in our study were used for this analysis. We encourage further methodological research to confirm whether the patterns we found can be replicated in other study data. Also, we assessed saturation using data for applied qualitative research, in which the study purpose and study participants may be more defined than in other types of qualitative research. Our results should not be taken as generic for other types of data or approaches to qualitative research. Finally, qualitative researchers may have different styles of developing codes (i.e., broad or specific codes), and our results may also reflect our code development style.
결론
Conclusion
"포화는 엄격성의 중요한 구성 요소입니다. 이는 모든 질적 연구에 존재하지만, 안타깝게도 주로 선언을 통해 드러납니다."(Morse, 2015, 587쪽). 본 연구는 포화에 대한 두 가지 접근 방식을 문서화하고 각 접근 방식에서 포화에 영향을 미치는 매개변수를 도출하여 질적 연구를 위한 표본 크기 추정 지침을 제공하는 방법론적 연구를 제공합니다. 적은 수의 인터뷰만으로도 데이터에서 포괄적인 범위의 문제를 파악할 수 있지만, 이러한 문제에 대한 풍부한 이해를 위해서는 더 많은 데이터가 필요하다는 것을 확인했습니다. 얼마나 많은 추가 데이터가 필요한지는 연구 목적, 연구 모집단, 코드 유형, 코드북의 복잡성 및 안정성 등 다양한 포화 매개변수에 따라 달라집니다. 이러한 포화 매개변수를 사용하여 특정 연구에 대한 표본 크기 추정치를 선험적으로 안내하고 출판물 내에서 포화를 평가하거나 달성한 근거를 입증하면 연구 목적과 질적 연구의 목표를 반영하는 보다 적절한 표본 크기가 도출될 가능성이 높습니다.
“Saturation is an important component of rigor. It is present in all qualitative research, but unfortunately, it is evident mainly by declaration” (Morse, 2015, p. 587). Our study provides methodological research to document two different approaches to saturation and draws out the parameters that influence saturation in each approach to guide sample size estimates for qualitative studies. We identified that a small number of interviews can be sufficient to capture a comprehensive range of issues in data; however, more data are needed to develop a richly textured understanding of those issues. How much additional data are needed will depend on a range of parameters of saturation, including the purpose of the study, study population, types of codes, and the complexity and stability of the codebook. Using these parameters of saturation to guide sample size estimates a priori for a specific study and to demonstrate within publications the grounds on which saturation was assessed or achieved will likely result in more appropriate sample sizes that reflect the purpose of a study and the goals of qualitative research.
Code Saturation Versus Meaning Saturation: How Many Interviews Are Enough?
PMID: 27670770
PMCID: PMC9359070
Free PMC article
Abstract
Saturation is a core guiding principle to determine sample sizes in qualitative research, yet little methodological research exists on parameters that influence saturation. Our study compared two approaches to assessing saturation: code saturation and meaning saturation. We examined sample sizes needed to reach saturation in each approach, what saturation meant, and how to assess saturation. Examining 25 in-depth interviews, we found that code saturation was reached at nine interviews, whereby the range of thematic issues was identified. However, 16 to 24 interviews were needed to reach meaning saturation where we developed a richly textured understanding of issues. Thus, code saturation may indicate when researchers have "heard it all," but meaning saturation is needed to "understand it all." We used our results to develop parameters that influence saturation, which may be used to estimate sample sizes for qualitative research proposals or to document in publications the grounds on which saturation was achieved.
Keywords: HIV/AIDS; USA; behavior; in-depth interviews; infection; methodology; qualitative; saturation.
'Articles (Medical Education) > 의학교육연구(Research)' 카테고리의 다른 글
| 질적 연구에서 주제 포화를 평가하고 보고하는 단순한 방법(PLoS One, 2020) (0) | 2023.03.17 |
|---|---|
| 인터뷰 기반 연구에서 표본 크기 충분성의 특성화 및 정당화: 15년간 질적 건강연구의 체계적 문헌고찰(BMC Med Res Methodol. 2018) (0) | 2023.03.17 |
| 질적연구에서 포화를 위한 표본 수: 실증 시험의 체계적 문헌고찰(Soc Sci Med. 2022) (0) | 2023.03.17 |
| 양적연구 질문과 질적연구 질문 및 가설 작성의 실용 가이드 (J Korean Med Sci. 2022) (0) | 2023.03.04 |
| 주관적 평가를 측정할 때 동의-비동의 문항 사용의 재고(Res Social Adm Pharm. 2022) (0) | 2023.01.17 |