템플릿 분석 하기 (Qualitative Organizational Research, Chapter 24)
Doing Template Analysis
Nigel King

템플릿 분석이란?
What is Template Analysis?
이 책과 다른 책에 기술된 다양한 유형의 질적 연구 중 한 가지 공통점은 광범위하고 복잡한 텍스트 데이터를 만든다는 것이다. 연구자가 텍스트에 포착된 경험에 대한 이해를 도출하기 위해 이로부터 어떻게 나아가는가는가는 데이터 분석 기술의 선택에 달려 있다. 이 장에서는 그러한 기법 중 하나인 템플릿 분석(TA)에 대해 설명하겠습니다. 나는 그것의 뒤에 있는 원칙들을 개략적으로 설명하고 질적 데이터 분석의 잘 알려진 다른 형태보다 선호될 수 있는 상황을 고려할 것이다. 실제 연구 프로젝트의 확대된 예를 통해 저는 이 기술을 활용하기 위해 필요한 핵심 단계를 거치겠습니다.
One common feature of the many different types of qualitative research described in this and other books is that it produces extensive and complex textual data (and occasionally also visual data: see Vince and Warren, in this volume). How the researcher moves on from this to produce an understanding of the experiences captured in the texts depends on their choice of data analytical techniques. In this chapter, I will describe one such technique: template analysis (TA). I will outline the principles behind it and consider the circumstances in which it might be preferred to other well-known forms of qualitative data analysis. Through the use of an extended example from a real research project I will go through the key steps required to utilize the technique.
템플릿 분석은 텍스트 데이터를 분석하는 과정에서 상대적으로 [높은 수준의 구조적 균형]을 잡고, [특정 연구의 필요에 따라 유연하게 조정]하는 [주제 분석의 한 가지 스타일]이다. 개별 인터뷰의 데이터를 분석하는 데 주로 사용되지만, 다른 형태에도 적용할 수 있다.
Template analysis is a style of thematic analysis that balances a relatively high degree of structure in the process of analysing textual data with the flexibility to adapt it to the needs of a particular study. It has mostly been used to analyse data from individual interviews (see Alvesson and Ashcraft, in this volume, for more on qualitative interviewing), but it can be applied to other forms too. The example used in this chapter employed focus group interviews (see also Kandola, in this volume), while Kent (2000) used it to analyse free response items on a questionnaire, and it could certainly be applied to data from diaries or to observational field notes (see Yanow, Ybema and van Hulst on ethnography and Brennan on participant observation, in this volume).
이 기술의 중심은 일반적으로 데이터의 하위 집합을 기반으로 하는 [코딩 템플릿을 개발하는 것]이며, 이것은 이후 추가 데이터에 적용되고 수정 및 재적용된다. 이 접근법은 생성되는 템플릿의 스타일과 형식에 대해 매우 유연하며, 다른 주제적 접근법과 달리 코딩 수준의 일련의 순서를 미리 제안하지 않는다.
Central to the technique is the development of a coding template, usually on the basis of a subset of the data, which is then applied to further data, revised and reapplied. The approach is very flexible regarding the style and format of the template that is produced and unlike some other thematic approaches does not suggest in advance a set sequence of coding levels.
템플릿 분석 다시 방문
Template analysis revisited
이 장의 첫 번째 버전은 10여 년 전에 등장했습니다(사이먼과 캐셀, 1998). 그 이후로, TA를 사용한 연구를 설명하는 출판물의 수가 상당히 증가했다. 내가 제인 멜빈과 함께 편집하고 있는 현재 진행중인 문학 리뷰는 200개가 훨씬 넘는 그러한 기사들을 식별해냈다. 넓은 영역에서는 조직 연구(예: Kenny and Briner, 2010)가 분명히 가장 크고 그 다음이 보건(Howard 등, 2008)이다. 이 외에도, TA는 교육(Au, 2007), 임상 심리/심리 치료(Stratton et al., 2006), 스포츠 과학(Nash and Sproule, 2009)을 포함한 광범위한 다른 환경에서 사용된다. TA 연구는 단일 자전적 사례(King, 2008)에서 질적 측면에서 매우 큰 것으로 간주될 수 있는 연구(Donnelly, 2008, 예를 들어 81건의 인터뷰 포함)에 이르기까지 규모가 상당히 다양하다.
The first version of this chapter appeared more than ten years ago (Symon and Cassell, 1998). Since then, the number of publications describing studies that have used TA has grown considerably. An ongoing literature review I am compiling with Jane Melvin has identified well over 200 such articles. In terms of broad area, organizational research (including business and management) is clearly the largest (e.g. Kenny and Briner, 2010), followed by health (Howard et al., 2008). Beyond these, TA is used in a wide range of other settings, including education (Au, 2007), clinical psychology/psychotherapy (Stratton et al., 2006) and sports science (Nash and Sproule, 2009). TA studies vary considerably in size, from a single autobiographical case (King, 2008) to studies that in qualitative terms may be considered very large (Donnelly, 2008, for instance included 81 interviews).
정의론 및 인식론 문제
Definitional and epistemological issues
템플릿 분석은 완전하고 구별되는 방법론이 아니라 폭넓은 인식론적 위치의 범위 내에서 사용될 수 있는 기술이다(이 책의 더벌리, 존슨 및 캐셀 참조). 한편으로, 템플릿 분석은 주류 양적 사회과학의 전통적인 실증적 위치의 많은 부분을 수용하는 [현실주의적 질적 작업]의 한 유형으로도 사용될 수 있다. 인간 행동의 근본적인 원인을 '발견'하고 연구자의 객관성을 달성하고 코딩 신뢰성을 입증하고자 하는 연구를 말한다(Kidd, 2008).
Template analysis is not a complete and distinct methodology, but rather is a technique that may be used within a range of epistemological positions (see Duberley, Johnson and Cassell, in this volume). On the one hand, it can be employed in the kind of realist qualitative work that accepts much of the conventional positivistic position of mainstream quantitative social science. By this I mean research that is concerned with ‘discovering’ the underlying causes of human action and which seeks to achieve researcher objectivity and to demonstrate coding reliability (Kidd, 2008).
반면에, 템플릿 분석은 Madill 등이 ['맥락적 구성주의자']라고 부르는 입장에서도 사용될 수 있다. 이 경우, 연구자들은 어떤 현상에 대해서도 항상 여러 해석이 있을 것으로 가정한다. 그것은 연구자의 입장과 연구의 맥락에 따라 달라질 것이다. 따라서 코딩 신뢰성에 대한 우려는 무관하다; 대신 연구자의 성찰성, 다양한 관점에서 주제에 접근하려는 시도와 생성된 설명의 풍부함에 중점을 둔다. 현상학, 상호작용주의자 및 일부 서술적 접근법(이 책의 미틀리스 참조)이 이 범주에 속한다.
On the other hand, template analysis can be used within what Madill et al. (2000) call a ‘contextual constructivist’ position. Here, the researcher assumes that there are always multiple interpretations to be made of any phenomenon, which will depend upon the position of the researcher and the context of the research. Concern with coding reliability is therefore irrelevant; instead the emphasis is on the reflexivity of the researcher (see Haynes, in this volume), the attempt to approach the topic from differing perspectives and the richness of the description produced (Wimalasiri et al., 2008). Phenomenological, interactionist and some narrative approaches (see Maitlis, in this volume) fall within this category.
템플릿 분석은 다양한 형태의 담화 및 대화 분석에서처럼, 언어가 우리 세계의 버전을 구성하기 위한 상호작용에서 어떻게 사용되는지를 검토하기 위한 목적으로 [급진적인 상대론적 접근법]을 취하는 방법론에서는 일반적으로 사용되지 않는다. 그러나 상호작용에 대한 면밀한 분석보다는 담론 사용의 광범위한 패턴에 관심을 가지고 주제별 분석 스타일을 사용한 사회 구성주의 연구의 예도 일부 있다(예: Taylor와 Usher, 2001). 원칙적으로 본다면, 그러한 연구는 주제 분석을 목적으로 템플릿 스타일을 사용할 수 있다.
Template analysis is generally not used in methodologies that take a radical relativist approach to examining how language is used in interaction to construct versions of our world – as in various forms of discourse and conversation analysis (see Oswick, and Greatbatch and Clark respectively, in this volume). There are, however, examples of social constructionist studies that are concerned with broad patterns of discourse use rather than the close analysis of interactions, and that have used a thematic style of analysis (e.g. Taylor and Ussher, 2001). In principle, such studies could use a template style for their thematic analysis.
템플릿 분석을 사용하는 이유
Why use template analysis?
질적 연구 프로젝트에 착수하려는 사람이 템플릿 분석을 사용해야 하는 이유는 무엇입니까? 특히, 근거 이론(예: Corbin과 Strauss, 2008), 해석 현상학적 분석(예: Smith 등, 2009) 또는 보다 일반적인 형태의 주제 분석(예: Braun과 Clark, 2006)과 같이 그것과 유사한 다른 접근법보다 이를 선택해야 하는 이유는 무엇인가? 이 섹션에서는 템플릿 분석이 이러한 대안과 관련하여 제공할 수 있는 이점을 고려하겠습니다.
Why should anyone about to embark on a qualitative research project choose to use template analysis? In particular, why should they choose it over other approaches that resemble it, such as grounded theory (for example, Corbin and Strauss, 2008, and see Kenealy, in this volume), interpretative phenomenological analysis (IPA; for example, Smith et al., 2009) or more generic forms of thematic analysis (e.g. Braun and Clarke, 2006)? In this section I will consider the advantages that template analysis may offer in relation to these alternatives.
먼저 근거 이론에 초점을 맞추면, 일부 연구자들에게 템플릿 분석에 대한 선호는 그들의 철학적 입장에 기초할 수 있다. 글레이저와 스트라우스가 1967년 기초이론의 발견에서 시작한 이래, 기초이론은 원작자들(스트라우스와 코빈, 1990년; 글레이저, 1992년)과 차마즈(1995년)가 제안한 사회구성주의 버전 사이의 차이를 포함하여 여러 다른 방향으로 발전해 왔다. 스트라우스와 코빈의 접근법은 아마도 가장 잘 알려져 있고 널리 사용되고 있으며, 이것과 글레이저의 접근법은 모두 현실주의적인 경향을 유지하고 있다. 즉, 사용자들은 대부분 연구 참여자들의 '진정한real' 신념, 태도, 가치 등을 발견한다고 주장해왔다. 따라서 경험적 연구를 통해 발견될 '실제real' 내부 상태의 존재에 회의적인 [맥락적 구성주의자 입장]을 취하는 질적 연구자들은 [템플릿 분석이 그들의 입장에 더 도움이 된다]고 느낄 수 있다.
Focusing first on grounded theory, for some researchers a preference for template analysis may be based on their philosophical position. Since its inception by Glaser and Strauss in The Discovery of Grounded Theory (1967), grounded theory has developed in a number of different directions, including a divergence between the original authors (Strauss and Corbin, 1990; Glaser, 1992) and a social constructionist version proposed by Charmaz (1995). The Strauss and Corbin approach is probably the best known and most widely used, and both it and Glaser’s version retain a realist orientation. That is to say, its users have mostly claimed to be discovering the ‘real’ beliefs, attitudes, values and so on of the participants in their research. Those qualitative researchers taking a contextual constructivist stance that is sceptical of the existence of ‘real’ internal states to be discovered through empirical research may therefore feel that template analysis is more conducive to their position.
템플릿 분석은 또한 근거이론의 가정에 적대적이지는 않더라도 (따라야 할 데이터 수집과 분석을 위한 절차를 명시한다는 점에서) [너무 규범적이라고 생각하는 사람들]이 선호할 수 있다(Corbin and Strauss, 2008). 대조적으로, 템플릿 분석은 전반적으로 지정된 절차의 숫자가 더 적은 [더 유연한 기법]이며, 연구자들이 자신의 요구사항에 맞게 조정할 수 있다.
Template analysis may also be preferred by those who are not inimical to the assumptions of grounded theory but find it too prescriptive (especially in the Strauss and Corbin version), in that it specifies procedures for data gathering and analysis that must be followed (Corbin and Strauss, 2008). By contrast, template analysis is, on the whole, a more flexible technique with fewer specified procedures, permitting researchers to tailor it to match their own requirements.
광범위한 현상학적 접근법에서 사용될 때, 템플릿 분석은 실제로 IPA와 매우 유사하다. 접근방식 간의 주요 차이점은 템플릿 분석에서 [선험적 코드]를 사용하고 [사례 내, 사례 간 분석의 균형]을 유지하는 것이다. IPA는 전체 사례의 통합을 시도하기 전에 개별 사례를 더 깊이 분석하는 경향이 있다. 이러한 차이로 인해 일반적으로 템플릿 분석이 IPA보다 다소 [시간이 적게 걸리고 더 큰 데이터 세트를 보다 편안하게 처리]할 수 있다는 효과가 있다. IPA 연구는 일반적으로 10개 이하의 표본을 기반으로 한다.
When employed within a broadly phenomenological approach, template analysis is in practice very similar to IPA. The main differences between approaches are the use of a priori codes in template analysis and the balance between, within and across case analysis. IPA tends to analyse individual cases in greater depth before attempting any integration of a full set of cases. The net effect of these differences is that template analysis is generally somewhat less time-consuming than IPA and can handle rather larger data sets more comfortably. IPA studies are commonly based on samples of 10 or fewer; template analysis studies usually have rather more participants, with 15 to 30 being common.
브라운과 클라크(2006) 등 일부 저자들은 특정 방법론 및 이론적 입장과 결부되지 않은 일반적인 형태의 주제 분석을 사용해야 한다고 주장한다. 이것은 내가 템플릿 분석은 사실상 '방법론'이라기보다는, 다양한 철학적 입장에서 사용될 수 있는 하나의 기법이라고 언급할 때와 같은 입장이다. 브라운과 클라크가 설명하는 주제 분석보다는 템플릿 분석을 선택할 수 있는 이유를 고려할 가치가 있다. 나는 기술마다 다양하며 연구자의 선택에 영향을 미칠 수 있는 세 가지 특징이 있다고 제안하고 싶다: 코딩 구조의 유연성, 선험적 테마의 사용, 초기 템플릿의 사용.
Some writers – notably Braun and Clarke (2006) – argue for the use of a generic form of thematic analysis, one that is not wedded to a particular methodological and theoretical position. This is in effect the same position that I would take in stating that template analysis is a technique rather than a methodology, which can be used from varying philosophical positions. It is worthwhile considering why one might choose template analysis rather than the kind of thematic analysis Braun and Clarke describe. I would suggest that there are three features that vary between the techniques and that might influence a researcher’s choice: the flexibility of the coding structure, the use of a priori themes, and use of the initial template.
코딩 구조의 유연성
Flexibility of the coding structure
일부 접근법은 코딩이 어떻게 구조화되어야 하는지를 미리 명시한다. 일반적으로는,
- 데이터에 가까운 서술적 주제에서
- 적은 수의 해석적 주제로 이동한 다음
- 소수의 주요(또는 '중요한') 테마로 이동한다(Langdridge, 2004; King and Horrocks, 2010 참조).
이러한 접근법은 [구체적이고 데이터에 기반한 단계]에서 [추상적이고 해석적인 단계]로의 단계적 이동을 요구하기 때문에, [경험이 부족한 질적연구자]들이 이른 단계에서 데이터에 강력한 해석을 서둘러 부과하지 않도록 하는데 유용할 수 있다. 그러나 [서술 코딩]과 [해석 코딩] 사이에 그렇게 명확한 차이가 있는지는 논쟁의 여지가 있다. 또한, 3단계 계층의 규범으로 인해 분석가가 데이터의 가장 풍부한 측면을 실제 깊이에서 탐색하는 것이 제한될 수 있다. 템플릿 분석은 고정된 수의 코딩 계층 구조를 요구하지 않는다. 대신 분석가가 (연구 질문과 관련하여) 가장 풍부한 데이터가 발견되는 곳에서 테마를 보다 광범위하게 개발하도록 장려한다. 마찬가지로, 템플릿 분석은 서술적 주제와 해석적 주제 사이의 명시적인 구별을 주장하지 않으며, 구조의 각 유형별로 특정한 위치를 주장하지 않는다.
Some approaches specify in advance how the coding should be structured, typically moving
- from descriptive themes that are close to the data,
- to feeding into a smaller number of interpretive themes and
- then in turn into a few major (or ‘overarching’) themes (see Langdridge, 2004; King and Horrocks, 2010).
By requiring a step-by-step move from the more concrete and data-grounded to the more abstract and interpretive, such techniques can be useful in discouraging inexperienced qualitative researchers from rushing to impose strong interpretations on the data at an early stage. However, it is debatable whether there is ever such a clear distinction between descriptive and interpretive coding. Furthermore, the norm of a three-level hierarchy may restrict analysts from exploring the richest aspects of the data in any real depth. Template analysis does not insist on a fixed number of levels of coding hierarchy – instead it encourages the analyst to develop themes more extensively where the richest data (in relation to the research question) are found. Equally, template analysis does not insist on an explicit distinction between descriptive and interpretive themes, nor on a particular position for each type in the structure.
선험 테마 사용
Use of a priori themes
주제 분석의 유형은 '상향식' 또는 '하향식' 접근법을 취하는 범위 측면에서 고려될 수 있다.
- 전자의 경우 데이터로부터 테마가 귀납적으로 개발될 수 있도록 기존의 이론적 또는 실제적 헌신을 적극적으로 피한다. IPA와 근거 이론에서 사용되는 주제 분석이 그렇다.
- 대조적으로, 하향식 접근법은 이론이나 실천에 의해 알려진 주제를 정의하고 적용하려고 한다. (예를 들어, 여기서 '실천'은 평가 기준 주위에 코딩 구조를 기초하는 것을 의미할 수 있다.) 매트릭스 분석(Nadin and Cassell, 2004)과 프레임워크 분석(Pope 등, 2000)은 일반적으로 이러한 종류의 접근방식을 채택한다.
Types of thematic analysis can be considered in terms of the extent to which they take a ‘bottom up’ or ‘top down’ approach.
- In the former, existing theoretical or practical commitments are actively avoided, to allow themes to be developed inductively from the data. This is the case in the thematic analysis used in IPA and grounded theory.
- By contrast, top down approaches seek to define and apply themes that are informed by theory or practice (‘practice’ here could mean, for example, basing the coding structure around evaluation criteria). Matrix analysis (Nadin and Cassell, 2004) and framework analysis (Pope et al., 2000) generally adopt this kind of approach.
템플릿 분석은 [하향식 및 상향식 분석 스타일 사이의 중간지점]에 배치할 수 있습니다. 이를 통해 연구자는 일부 주제(선험적 주제)를 미리 정의할 수 있지만, 대개 연구의 주요 개념이나 관점에 해당하는 제한된 수의 주제만 정의할 수 있다. 또한 선험적 주제가 재정의되거나 폐기될 필요가 있을 수 있는 가능성을 항상 고려하여 이러한 주제들이 잠정적으로 사용된다고 주장한다.
Template analysis can be positioned in the middle ground between top down and bottom up styles of analysis. It allows the researcher to define some themes in advance (a priori themes), but usually only a limited number that correspond to key concepts or perspectives for the study. It also insists that these are used tentatively, with the possibility always considered that any a priori theme may need to be redefined or discarded.
초기 템플릿 사용
Use of the initial template
대부분의 주제적 접근법은 연구자가 각 사본(또는 다른 텍스트 데이터 부분)에 대한 분석의 각 단계를 수행해야 한다. 템플릿 분석에서 [데이터의 하위 집합에 기반한 초기 템플릿을 사용]하는 방식으로 변화를 줄 수 있다. [초기 템플릿]의 구성에 따라 연구자는 다음 및 후속 사본에 대해서는 예비 코딩preliminary coding부터 시작할 필요가 없어진다. 이 장의 뒷부분에 나오는 예에서 볼 수 있듯이 초기 템플릿을 적용, 수정 및 다시 적용하는 반복적인 프로세스를 통해 분석이 대신 진행됩니다. 이러한 유형의 분석은 모든 데이터에 대해 모든 단계를 수행해야 하는 분석보다 더 효율적일 수 있습니다. 결정적으로, 내 경험상, 초기 템플릿을 사용하는 것은 이것이 적절하게 수행될 경우 분석의 깊이를 감소시키는 심각한 위험을 감수하지 않는다.
Most thematic approaches will require the researcher to carry out each step of the analysis on each transcript (or other piece of textual data). In template analysis, the use of an initial template based on a sub-set of the data changes the process. Following the construction of the initial template, the researcher does not need to begin with preliminary coding for the next and subsequent transcripts. As will be seen in the example later in this chapter, analysis progresses instead through an iterative process of applying, modifying and re-applying the initial template. This style of analysis can be more efficient than those that require all the steps to be carried out on all the data. Crucially, using the initial template does not, in my experience, seriously risk reducing the depth of the analysis if this is carried out properly.
템플릿 분석의 주요 특징
Key Features of Template Analysis
테마 및 코드 정의
Defining themes and codes
질적 분석의 [주제]는 [연구자가 특정 연구의 연구 질문과 관련되었다고 본, 참자가의 인식 및 경험을 특징짓는 account(인터뷰, 일기, 블로그 등)의 반복적이고 독특한 특징]으로 정의될 수 있다. '테마'의 개념을 정의하는 데 관련된 문제는 브라운과 클라크(2006)와 킹과 호록스(2010)에서 더 자세히 탐구한다. 이 장의 목적상, 이 정의와 관련하여 다음과 같은 세 가지 논점이 있다.
Themes in qualitative analysis may be defined as the recurrent and distinctive features of participants’ accounts (in interviews, diaries, blogs and so on) that characterize perceptions and/or experiences, seen by the researcher as relevant to the research question of a particular study. The issues involved in defining the concept of ‘theme’ are explored further in Braun and Clarke (2006) and King and Horrocks (2010). For the purposes of the present chapter, there are three points related to this definition that require some comment:
1 '테마'라는 용어는 [반복]을 의미한다. 뷰가 표현되거나 경험이 기술된 단일 격리된 인스턴스에 적용해서는 안 됩니다. 테마는 일반적으로 여러 케이스에 걸쳐 식별되지만, 단일 사례 내에서 여러 번 식별되는 중요한 것은 여전히 테마로 정의될 수 있다.
1 The term ‘theme’ implies repetition. It should not be applied to a single isolated instance where a view is expressed or an experience described. While themes are usually identified across several cases, something important that is identified several times within a single case could still be defined as a theme.
2 테마는 그것을 정의하는 연구자와는 독립적이지 않습니다. 그들은 바위의 화석처럼 발견되기를 기다리며 거짓말을 하지 않습니다. 가장 현실주의적인 질적 연구조차도 주제가 객관적인 '사실'이 아니라는 것을 인정한다.
2 Themes are not independent of the researcher who defines them. They do not lie waiting to be discovered, like a fossil in a rock. Even the most realist-oriented qualitative research recognizes that themes are not objective ‘facts’.
3 유용하기 위해서는, 주제들이 서로 상대적으로 구별되어야 합니다. 일부 중복은 불가피하지만 주제 간의 광범위한 경계가 모호해지는 것은 피해야 한다.
3 To be useful, themes must be relatively distinct from each other. Some overlap is inevitable, but an extensive blurring of boundaries between themes is to be avoided.
코딩(coding)은 텍스트의 한 섹션에 레이블(코드)을 부착하여 테마와 관련된 색인화하는 과정이다. 템플릿 내에는 엄격하게 말해서 테마를 인덱싱하지 않고 관련 테마를 구성하는 데 도움이 되는 '플레이스홀더' 역할을 하는 일부 코드가 있을 수 있다(Gibbs, 2002). 예를 들어, 새로운 IT 시스템에 대한 직원 견해 연구에서 각 그룹과 관련된 테마가 구성되는 자리 표시자 코드로 직원 그룹을 사용할 수 있습니다.
Coding is the process of attaching a label (code) to a section of text to index it as relating to a theme. Within a template there may also be some codes that strictly speaking do not index themes but rather serve as ‘placeholders’ (Gibbs, 2002) to help organize associated themes. For instance, in a study of staff views on a new IT system, we might use staff groups as placeholder codes under which themes relating to each group are organized.
계층적 코딩
Hierarchical coding
템플릿 분석의 주요 특징은 [코드들의 계층적 조직으로, 유사한 코드들의 그룹들이 함께 모여 보다 일반적인 고차 코드를 만드는 것]이다. 계층적 코딩은 연구자가 다양한 수준의 특수성으로 텍스트를 분석할 수 있게 해주며, 연구자가 유용하다고 생각하는 만큼 다양한 수준의 테마가 있을 수 있다. 중요한 것은 주요(즉, 최상위 수준) 주제가 정교해지는 정도(하위 테마의 수와 수준)는 [특정 연구의 주제 영역에 대한 통찰력의 제공]이라는 측면에서 얼마나 풍부한지 반영해야 한다. 그러나 너무 많은 수준은 데이터를 정리하고 해석하는 데 있어 명확성을 확보하려는 목표에 역행할 수 있다는 점을 명심할 필요가 있다.
A key feature of template analysis is the hierarchical organization of codes, with groups of similar codes clustered together to produce more general higher order codes. Hierarchical coding allows the researcher to analyse texts at varying levels of specificity and there can be as many levels of themes as the researcher finds useful. Importantly, the extent to which main (i.e. top level) themes are elaborated – in terms of the number and levels of sub-themes – should reflect how rich they prove to be in terms of offering insights into the topic area of a particular study. It is worth bearing in mind, though, that too many levels can be counter productive to the goal of attaining clarity in organizing and interpreting the data.
템플릿은 계층적으로 구성될 뿐만 아니라 [테마 간의 측면 링크lateral link]를 표시할 수도 있습니다. 이것은 많은 주요 주제들을 가로지르는 소수의 통합 테마의 형태일 수도 있고, 개별 주제들 간의 더 복잡한 연결을 포함할 수도 있다. 템플릿에서 이러한 측면 링크lateral link를 사용하고 묘사하는 방법은 아래에 설명되어 있습니다.
As well as being organized hierarchically, the template can present lateral links between themes. This may be in the form of a small number of integrative themes that cut across many of the main themes or it may involve more complex links between individual themes. Using and depicting such lateral links on the template is discussed below.
병렬 코딩
Parallel coding
템플릿 분석은 일반적으로 텍스트 세그먼트의 병렬 코딩을 허용하며, 여기서 [동일한 세그먼트가 동일한 수준에서 두 개 이상의 다른 코드에 분류]된다. 병렬 코딩은 연구자들이 템플릿 분석과 정량적 내용 분석 요소를 결합하기를 원할 수 있는 [질적 연구 스펙트럼에서 실증적 지향성을 강하게 갖는 연구]에서만 문제가 될 수 있다.
Template analysis usually permits a parallel coding of segments of text, whereby the same segment is classified within two (or more) different codes at the same level. Parallel coding is only likely to be problematic in research that is located strongly towards the positivist end of the qualitative research spectrum, where researchers may wish to combine template analysis with elements of quantitative content analysis.
통합적 주제
Integrative themes
때때로 템플릿을 개발하는 과정에서 [데이터의 많은 부분에 걸쳐 있는 것처럼 보이는 특정 주제]가 있다는 것이 명확해진다. 이러한 주제는 다른 주제 클러스터 중 다수에 걸쳐 있다. 예를 들어, 당뇨병 신장 질환의 경험에 대한 연구(King et al., 2002)에서 우리는 데이터의 많은 부분에 '불확실성'이 스며들어 있음을 발견했다. 단순히 이 주제를 최상위 테마로 취급하는 것만으로도 다른 모든 주제 군집과 관련된 방식에 충분한 관심을 끌지 못했을 것이다. 마찬가지로, '불확실성'을 각 최상위 테마에 하위 테마로 추가하는 것은 우리가 보기에 그 중요성을 충분히 분명하게 하지 못했다. 따라서 템플릿을 만들 때 [여러 테마를 횡으로 연결하는 것]으로 표시한 [통합적 주제]를 식별했습니다.
Sometimes as the template develops it will become clear that there are certain themes that seem to pervade much of the data, cross-cutting many or all of the other thematic clusters. For example, in a study of experiences of diabetic renal disease (King et al., 2002), we found that ‘uncertainty’ permeated much of the data. To have simply treated this as a top-level theme in itself would not have drawn sufficient attention to the way it related to all the other thematic clusters. Equally, adding ‘uncertainty’ as a sub-theme to each top-level theme would not in our view have made its importance apparent enough. We therefore identified it as an integrative theme, shown on the template as connecting the other themes laterally.
통합적 주제를 개념화하는 한 가지 방법은 참가자의 account에 있는 undercurrent이다. 이것은 종종 명시적으로 다루지 않지만, 신중하게 읽어본다면 매우 명백하다. 당뇨병 신장병 연구에서 우리는 거의 모든 참가자가 취하는 그들의 질병에 대한 전형적인 입장을 나타내기 위해 '금욕stoicism'이라는 두 번째 통합적 주제를 확인했다. 그들은 자신들을 명시적으로 '금욕적'이라고 설명하지는 않았지만, 그들의 질병 경험에 대한 많은 다른 측면에서 그것을 보여주었다. '금욕주의'라는 통합적 주제는 사람들이 더 이상 개인의 고통에 대해 '강렬한 윗입'을 유지할 필요성을 느끼지 못한다는 문헌의 주장과 모순되는 것으로 보였기 때문에 관심을 끌었다.
One way to conceptualize integrative themes is as undercurrents running through participants’ accounts; often, perhaps, not addressed explicitly but very apparent to the careful reader. In the diabetic renal disease study we identified a second integrative theme of ‘stoicism’ to indicate the typical stance towards their illness taken by almost all participants. They did not explicitly describe themselves as ‘stoical’ but demonstrated it in many different aspects of their accounts of their illness experience. The integrative theme of ‘stoicism’ was of interest because it appeared to contradict claims in the literature that people no longer felt the need to maintain a ‘stiff upper-lip’ towards personal suffering.
템플리트 표시: 목록 및 마인드맵
Displaying the template: lists and mind-maps
템플릿 자체는 중요한 의사소통 기능을 가지고 있기 때문에, 그것을 가장 잘 표현할 수 있는 방법에 대해 신중하게 생각해 볼 가치가 있다. 사용할 수 있는 스타일은 크게 두 가지가 있습니다.
- 첫째, 테마는 들여쓰기, 타이포그래피(예: 글꼴 크기 및 스타일) 및/또는 번호 체계로 표시된 레벨과 함께 목록으로 표시될 수 있습니다.
- 둘째, 테마는 '마인드맵'과 유사한 형식으로 배치될 수 있으며, 계층적 수준을 나타내기 위해 화살표 연결뿐만 아니라 타이포그래피 세부 정보를 사용할 수도 있다. 마인드맵 버전은 주제 클러스터 사이의 측면 링크를 목록 스타일보다 더 명확하게 표시할 수 있도록 한다. 그러나 이것은 더 복잡하고 전체 템플릿은 목록 버전보다 디스플레이에서 훨씬 더 많은 공간을 차지한다.
The template itself has an important communicative function; it is therefore worthwhile to think carefully about how best to present it. There are two main styles that can be used.
- First, themes can be presented in a list, with levels indicated by indentation, typography (e.g. font size and style) and/or a numbering system.
- Second, themes can be laid out in a format similar to a ‘mindmap’, which might also use typographic details as well as connecting arrows to indicate hierarchical levels. The mind-map version allows lateral links between thematic clusters to be shown more clearly than in the list style. It is, however, more complex and for the full template would take up considerably more space in its display than the list version.
비록 템플릿 분석을 사용하여 발표된 대부분의 연구가 [템플릿을 목록 형식으로 제시]하지만, 주제 클러스터 간의 측면 링크가 중요한 경우 마인드맵 스타일을 사용하는 것을 고려하는 것이 유용하다. 스터디의 서면 설명에서 더 잘 작동하는 경우 언제든지 목록 형식으로 변환할 수 있습니다.
Although most published studies using template analysis present the template in list form, it is useful to think about using the mind-map style when the lateral links between thematic clusters are important. It is always possible to convert this to a list format if that works better in a written account of the study.
품질 검사
Quality checks
질적 연구의 질적 문제는 이 책에서 사이먼과 캐셀이 자세히 다루고 있다. 여기서는 템플릿 분석과 관련된 특정 사항을 강조하겠습니다. 데이터 분석의 품질을 향상시키기 위해 [일반적으로 사용되는 전략]에는 연구자와 전문가 패널 간의 독립적인 코딩 및 비판적 비교, 응답자 피드백 및 감사 추적 제공이 포함된다. 이 모든 것은 템플릿 분석의 체계적인 특성과 템플릿의 수정을 통해 떠오르는 사고를 문서화할 수 있는 가능성에 의해 도움을 받는다.
- 특히 [감사 추적]의 모아두는 것은 이러한 접근법과 매우 잘 부합한다. [감사 추적]은 연구자가 분석을 수행하면서 거쳤던 단계와 그 혹은 그녀의 사고가 발전한 방식을 기록한 것이다. 분석 과정에서 템플릿이 어떻게 발전하는지, 연속된 버전에 번호를 매기고 날짜를 기입하고, 템플릿에 큰 변화가 생긴 이유에 대해 메모해 두는 것이 좋습니다.
The issue of quality in qualitative research is dealt with in detail by Symon and Cassell in this volume. Here I will highlight specific points relating to template analysis. Some of the commonly used strategies for enhancing the quality of data analysis include: independent coding and critical comparison among researchers and by expert panels; respondent feedback; and the provision of audit trails. All of these are assisted by the systematic nature of template analysis and the possibility it offers to document emerging thinking through the modification of the template.
- The compiling of an audit trail, in particular, fits very well with this approach. An audit trail in qualitative research is a record of the steps the researcher has gone through in carrying out an analysis and the way his or her thinking has developed. I would always recommend that a full record is kept of how the template develops over the course of the analysis, numbering and dating successive versions and keeping notes as to the reasons for any major changes made to it.
템플릿 개발: 예
Developing the Template: An Example
접근 방식을 일반적인 용어로 설명한 후, Huddersfield 대학의 팀원들에 의해 수행된 꽤 최근의 연구의 데이터 분석에 사용하는 데 수반되는 단계를 여기에 발표하겠습니다. 우리가 작업하고 있던 자료를 이해하기 위해서는 프로젝트의 배경이 필요합니다.
Having described the approach in general terms, I will present here the steps involved in using it for the analysis of data from a quite recent study carried out by members of my team at the University of Huddersfield. Some background to the project is necessary here in order to understand the material that we were working with.
배경: 커뮤니티 그룹 참여 연구
Background: the community group participation study
영국 정부는 2002년부터 광범위한 보건 전략의 일환으로 350개의 건강 생활 센터(HLCs)를 설립했다. 이는 심각한 빈곤 지역의 건강과 복지를 개선하기 위한 지역사회 기반 이니셔티브와 활동의 초점 역할을 했다. 허더즈필드 대학의 응용심리연구센터(CAPR)는 영국 북부의 빈곤한 도시 지역에서 HLC에 대한 일련의 평가 연구를 수행하도록 의뢰되었으며, 이를 브룸빌 헬스 파트너십(BHP)이라고 부른다. 나, 엠마 커크비-게데스, 앨리슨 브라빙턴으로 구성된 프로젝트 팀은 BHP의 지원을 받는 세 커뮤니티 그룹의 멤버들과 함께 포커스 그룹(칸돌라 참조)을 수행했다. 그룹의 세부사항은 아래의 표 24.1에 제시되어 있다.
As part of their wider health strategy (Department of Health, 1999) from 2002 the UK government set up 350 Health Living Centres (HLCs) . These served as a focus for community-based initiatives and activities to improve health and wellbeing in areas of significant deprivation. The Centre for Applied Psychological Research (CAPR) at the University of Huddersfield was commissioned to carry out a series of evaluation studies for an HLC in a deprived urban area in northern England, which I will refer to as the Broomville Health Partnership (BHP). The project team of myself, Emma Kirkby-Geddes and Alison Bravington carried out focus groups (see Kandola, in this volume) with members of three community groups supported by the BHP. Details of the groups are given in Table 24.1 below.
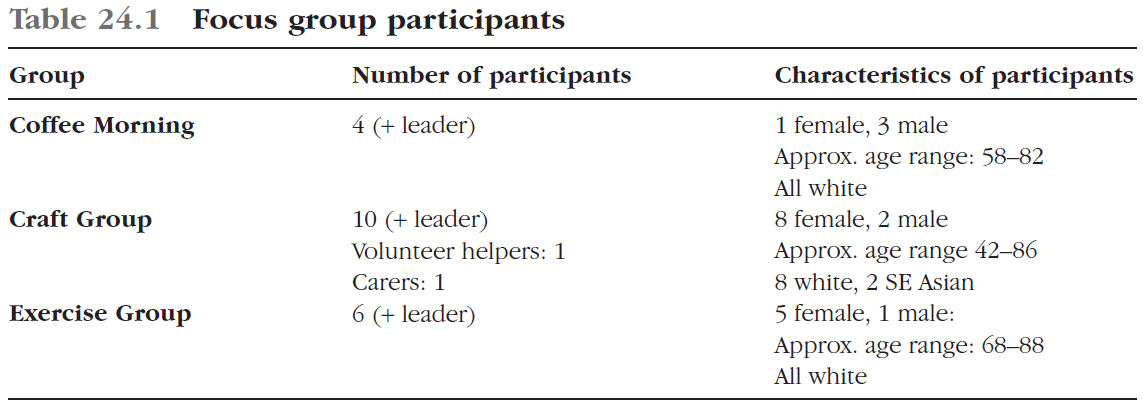
포커스 그룹은 오디오 녹음, 문자 그대로 옮겨지고 템플릿 분석을 사용하여 분석되었다. 이 분석 프로세스의 단계가 아래에 설명되어 있습니다. 특히 초기 단계에서 분석을 용이하게 하기 위해 대본은 여백이 넓고 줄 번호가 매겨진 이중 간격으로 배치되었다.
The focus groups were audio-recorded, transcribed verbatim and analysed using template analysis. The stages of this analytical process are described below. The transcripts were laid out double spaced with wide margins, and line numbered, to facilitate analysis – especially in the early stages.
평가 프로그램의 이 부분의 전체적인 목표는 다음과 같다.
The overall aim of this part of the evaluation programme was:
•• 브룸빌을 공동체로 바라보는 시각에서 BHP가 지원하는 그룹 활동에 참여하는 이들이 건강생활동반자 관계와 어떤 관계를 경험하는지 살펴본다.
•• To examine how those participating in group activities supported by BHP experience their involvement with the Healthy Living Partnership, in the context of their views of Broomville as a community.
'참여'라는 것은 그들 자신의 그룹에 참여하는 것과 그들이 BHP와 그것이 지원하는 활동과 시설에 대한 더 넓은 참여를 의미한다.
By ‘involvement’ we meant both participation in their own group and their wider engagement with the BHP and the activities and facilities it supported.
선험적 주제 및 예비 코딩
A priori themes and preliminary coding
예비 코딩을 시작하기 전에, 익숙해지기 위해 대본을 훑어보고 혹시 모를 전사 오류를 확인하는 것이 필수적이다. 첫 번째 대본을 가져가서 연구 질문에 답하는 것과 관련이 있는 것으로 보이는 텍스트의 모든 부분을 여백에 관심 있는 내용을 요약한 예비 코드 제목을 적어두어야 한다. [선험적 주제]를 사용하는 경우, 원고를 나열하고 정의하는 문서 옆에 시트를 두는 것이 가장 좋습니다. 선험적 주제 중 하나에 포함될 수 있는 텍스트 섹션이 나타나면 여백에 이를 기록해 두십시오. 이 단계에서 특정 이슈의 관련성이 의심된다면, 포괄성 측면에서 오류를 범하고 코드를 작성하는 것이 최선이다. 해석에 추가되지 않는 경우 나중에 항상 따로 둘 수 있습니다.
Before beginning preliminary coding, it is essential to read through the transcripts for familiarization and to check for any possible errors in transcription. The first transcript should be taken and every section of text that seems to offer something of relevance to answering the research question marked, noting in the margin a preliminary code title that sums up what is of interest here. If using a priori themes, it is best to have a sheet beside the transcript listing and defining these; should a section of text emerge that can be encompassed by one of the a priori themes, make a note of this in the margin. At this stage if there is doubt as to whether a particular issue is relevant, it is best to err on the side of inclusivity and code it. It can always be set aside later if it transpires that it does not add to the interpretation.
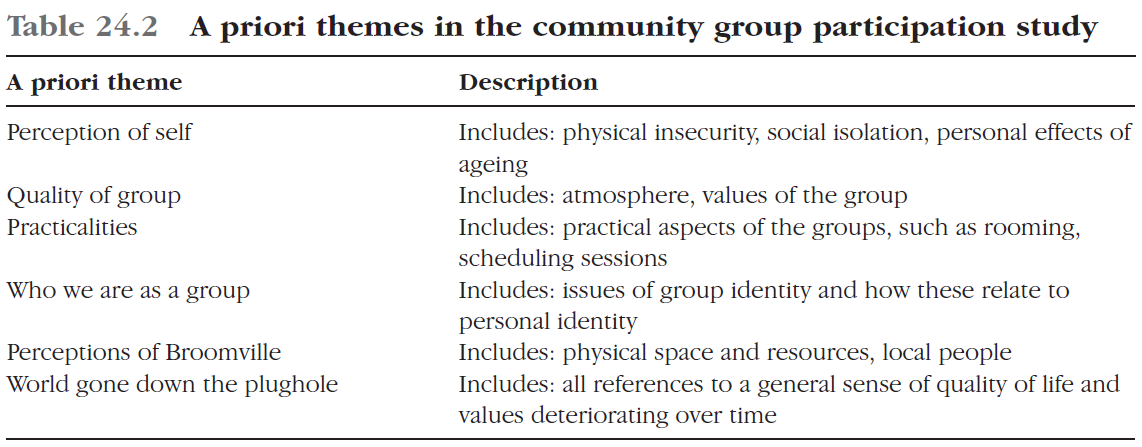
BHP 커뮤니티 그룹 참여 연구에서는 포커스 그룹과 함께 분석을 시작하여 녹음을 들은 다음 특히 커피 모닝 그룹 성적표에 집중했습니다. 예비 코딩을 시작하기 전에 BHP의 평가 우선 순위와 대본에 대한 초기 읽기 및 토론을 바탕으로 6개의 선험적 테마를 식별했다. 이것들은 표 24.2에 설명되어 있다.
In the BHP community group participation study we began our analysis with the focus groups, listening to the recordings and then focusing particularly on the Coffee Morning group transcript. Before commencing preliminary coding we identified six a priori themes, based on the BHP’s evaluation priorities and on our initial reading and discussion of the transcripts. These are described in Table 24.2.
다음으로 우리는 각각 선택된 대본을 독립적으로 읽고 연구의 목표와 관련된 문제와 관련된 것으로 보이는 모든 부분의 여백 및 텍스트 위에 예비 코드를 추가했다. 만약 그러한 섹션이 선험적 주제 중 하나에 의해 캡슐화될 수 있다면, 우리는 이것을 대본에도 언급했다.
Next we each independently read through the selected transcript and added preliminary codes in the margins and/or above the text wherever any section of the discussion appeared to relate to matters relevant to the study aims. If such sections could be encapsulated by one of the a priori themes we noted this on the transcript too.
초기 템플릿
Initial template
템플릿 분석에서 중요한 결정은 [언제 초기 템플릿 개발을 시작해야 하는가]이다. 위에서 언급한 바와 같이, 이것은 일반적으로 데이터의 하위 집합을 기반으로 하지만, 얼마나 빨리 시도해야 하는지에 대한 고정된 규칙은 있을 수 없다. 일반적으로, 연구 참여자의 account가 다양할수록, 실행 가능한 초기 템플릿을 만들기 위해 더 많은 스크립트를 분석해야 한다.
A key decision in template analysis is when to begin to develop an initial template. As noted above, this is normally based on a sub-set of the data, but there can be no fixed rule as to how soon it should be attempted. In general, the more diverse the accounts provided by participants within a study, the more transcripts will need to be analysed to produce a workable initial template.
[초기 템플릿 개발]은 [예비 코드]의 [클러스터링]에서 시작된다. [테마 간의 종적 및 횡적 관계를 정의]할 수 있는 의미 있는 그룹으로 만드는 것이다. 이것은 주제를 구성하는 많은 다른 방법들이 시도되는 매우 유동적이고 탐구적인 과정이어야 한다. 클러스터링 프로세스에서 선험적 주제가 반드시 클러스터의 최상위 수준에 있다고 가정해서는 안 된다. 선험적 테마는 가장 잘 작동하는 것으로 보이는 장소를 찾을 때까지 어느 방향으로든 새롭게 만들어지는 구조로 이동할 수 있다.
Developing the initial template begins with the clustering of preliminary codes, to bring them into meaningful groups within which hierarchical and lateral relations between themes can be defined. This should be a very fluid and exploratory process, in which many different ways of organizing themes are attempted. In the clustering process, it should not be assumed that a priori themes are necessarily going to be at the top levels of clusters; they can be moved around anywhere in the emerging structure until a place is found where they seem to function best.
본 연구에서는 첫 번째 포커스 그룹의 예비 코딩에 기초하여 템플릿의 초기 버전을 제작했다. 우리는 서로의 코딩을 보고, 공통점과 차이점에 대해 토론하고, 정리할 테마의 잠정적인 집합에 동의하는 것으로 시작했다. 우리는 포스트잇 노트에 각각의 잠재적인 주제를 쓰고 의미 있는 클러스터로 보이는 큰 종이에 노트를 배치했다. 포스트잇을 사용하는 장점은 템플릿을 구성하는 다른 방법을 탐색하기 위해 쉽게 이동할 수 있다는 것이지만, 물론 다른 방법도 사용할 수 있습니다. 서로 다른 버전의 구조를 시험해 보는 긴 과정 후에 우리는 그림 24.1에 나온 초기 템플릿에 합의했습니다.
In our study we produced an initial version of the template on the basis of the preliminary coding of the first focus group. We began by looking at each other’s coding, discussing the similarities and differences and agreeing on a provisional set of themes to organize. We wrote each potential theme on a Post-it note and placed the notes on large sheets of paper in what seemed to be meaningful clusters. The advantage of using Post-its is that they can easily be moved around to explore alternative ways of organizing the template, but of course other methods could be used. After a lengthy process of trying out different versions of the structure we agreed on the initial template shown in Figure 24.1.


선험적 주제 중 두 가지는 초기 템플릿에 포함되지 않았다. 두 경우 모두 템플릿의 다른 곳에도 맞지 않는 선험적 테마 제목 아래 '적합'되는 항목이 거의 없다는 것을 발견했습니다. 나아가 노화와 신체적 불안과 같은 문제가 집단, 공동체, 사회의 관계 맥락에서 거의 항상 제기된다는 것을 데이터가 보여주었을 때 자아에 대한 인식은 지나치게 개인주의적으로 보였다. 템플릿에 편하게 담기지 않은 예비 테마도 다수 있었다. 이 단계에서 우리는 단순히 이것들을 분류되지 않은 것으로 남겨두었다.
Two of the a priori themes were not included in the initial template – Perception of Self and Practicalities. In both cases, we found there was little that would ‘fit’ under the a priori theme title that did not also fit elsewhere on the template. Further, Perception of Self seemed overly individualistic when the data showed that issues such as ageing and physical insecurity were almost always raised in the context of relationships in the group, the community and society more widely. There were also a number of preliminary themes that we could not include comfortably on the template. At this stage we simply left these as Uncategorized.
초기 템플릿에는 하나의 통합적 테마가 포함되어 있습니다. 수축shrinkage. 이것은 많은 참가자들이 개인적으로 노화의 영향과 지역 편의시설과 시설의 손실과 같은 것들을 통해 그들의 세계가 줄어드는 것을 묘사하는 방법을 포착했다.
The initial template included one integrative theme: Shrinkage. This captured the way that many participants seemed to describe a sense of their world shrinking – personally through such things as the effects of ageing and collectively through the loss of local amenities and facilities.
템플릿 수정
Modifying the template
초기 템플릿이 구성되면, 연구원은 전체 스크립트 세트를 체계적으로 작업하여 프로젝트의 목적과 관련된 텍스트 섹션을 식별하고 하나 이상의 적절한 코드로 표시해야 합니다. 이 과정에서 초기 템플릿의 미흡함이 드러나 다양한 종류의 변경이 필요할 것이다. 이것들을 통해 템플릿이 최종 형태로 발전합니다.
Once an initial template is constructed, the researcher must work systematically through the full set of transcripts, identifying those sections of text that are relevant to the project’s aims and marking them with one or more appropriate code(s). In the course of this, inadequacies in the initial template will be revealed, requiring changes of various kinds. It is through these that the template develops to its final form.
커뮤니티 그룹 참여 연구에서 초기 템플릿을 개발한 후, 연구 목표와 관련하여 데이터에서 중요하다고 느끼는 모든 것을 포착하는 데 성공했는지 확인하기 위해 다시 첫 번째 포커스 그룹 대본을 검토했다. 그 결과 다음과 같은 몇 가지 사항을 변경했습니다.
Having developed the initial template in the community group participation study, we again went through the first focus group transcript to check that it had succeeded in capturing everything we felt to be important in the data in relation to our research aims. As a result we made several changes:
•• 새로운 최상위 테마를 추가했습니다. BHP에 대한 이해 및 인식
•• We added a new top-level theme: Understanding and Perception of BHP.
•• 새로운 통합적 테마를 추가했습니다. 나이를 먹는 것.
•• We added a new integrative theme: Getting Older.
•• 우리는 브룸빌에 대한 최상위 테마를 두 가지 2단계 테마로 나누었다. 사람과 물리적 공간 및 시설.
•• We divided the top-level theme Perceptions of Broomville into two second-level themes: People and Physical Space and Facilities.
그런 다음 이 수정된 초기 템플릿을 나머지 두 포커스 그룹에 적용하여 이러한 관련 재료가 템플릿의 어떤 테마에서도 쉽게 다뤄질 수 없는 경우와 그에 따라 템플릿을 수정해야 하는 경우에 주목했다. 마지막으로 개별 인터뷰 대본을 모두 읽고 추가 수정 사항이 있는지 확인합니다. 그 결과, 템플릿의 최종 버전이 그림 24.2에 제시되었습니다.
We then applied this revised initial template to the remaining two focus groups, noting where relevant material in these could not be readily covered by any theme on the template and where necessary revising the template accordingly. Finally we read through the individual interview transcripts to identify any further revisions needed. This resulted in the final version of the template shown in Figure 24.2.



이 과정에서 우리는 다양한 방법으로 템플릿을 재구성했습니다. 이에 대한 예는 다음과 같습니다.
Throughout this process we reorganized the template in various ways. Examples of these are given below.
삽입
Insertion
초기 템플릿을 제작한 후 브룸빌/사람에 대한 인식 아래에 인종 간 문제라는 새로운 3단계 주제를 추가했습니다. 초기 템플릿의 첫 번째 버전에 민족성과 관련된 몇 가지 문제가 등장했고, 그 이후에 더 추가되었지만, 우리는 이 시점에서야 이러한 주제를 종합함으로써 일반적으로 이 지역의 중요성이 가장 잘 반영된다는 것을 인식했다. 주제는 커피 모닝 그룹에서 (주로 남아시아 공동체에 관한) '인종'에 대한 명시적인 토론과 다른 두 그룹에서 더 많은 암시를 포함했다.
After producing the initial template we added a new third-level theme of Inter-racial Issues, under Perceptions of Broomville/People. While some issues relating to ethnicity did appear on the first version of the initial template, and more were added subsequently, it was only at this point that we recognized that the importance of the area in general was best reflected by pulling together such a theme. The theme included both an explicit discussion of ‘race’ (mostly regarding the South Asian community) in the Coffee Morning Group and more implicit allusions in the other two groups.
저는 아시아인들과 함께 살았고, 그들은 10년에서 12년 동안 그곳에 있었고, 그들이 당신에게 말하기 시작하는데 그렇게 오래 걸렸습니다. 그들은 당신을 그냥 무시하고 지금도 당신을 비웃고 당신을 지나칠 때 다른 쪽을 바라볼 것이다.I’ve lived with Asians, they’ve been there 10 to 12 years, and they, it’s taken that long for them to start speaking to you. They just ignore you, and even now, they’ll turn their nose up at you and look the other way when they walk past you. (Roger, Coffee Morning Group)
음, 만약 당신이 진실을 말하고 말할 수 있다면, 우리는 아시아 여자들을 위해 늘 쓰던 방에서 쫓겨난 것입니다. 제가 그렇게 말하지 말았어야 했다면, 저는 잘 모르겠지만, 우리는 그랬습니다. (기쁨, 운동 그룹)
Well, if you can speak the truth and speak out, we were pushed out [of our usual room] for the Asian ladies; if I shouldn’t have said that, I don’t know, but we were – so. (Joyce, Exercise Group)
[조이스 옆에 있는 멤버는 그녀의 머리를 두 손으로 받치는 과장된 제스처를 취하고 있다; 다른 사람들은 당황한 표정을 짓고 있다.]
[Member next to Joyce makes exaggerated gesture of holding her head in her hands; others look embarrassed.]
삭제
Deletion
최상위 테마인 Quality of Group은 템플릿 버전 4에서 삭제되었고 두 번째 레벨 테마인 우리의 그룹으로서의 목적(Us as a Group 아래)은 최종 버전에서 제거되었다. 왜냐하면, 분석이 진행됨에 따라, 우리는 우리의 연구 목적 측면에서 사람들이 그들의 집단을 어떻게 보는지에 대한 가장 중요한 측면이 균형이라는 것을 점점 더 많이 관찰했기 때문이다. 이 때의 균형은 [과정과 관계를 '내부적으로' 보는 경향]과 [모임과 더 넓은 공동체에서 관련된 집단이 어떻게 사는지에 대한 '외부적으로' 보는 의지] 사이에 있다.
The top-level theme Quality of Group was deleted at version four of the template and the second-level theme Our Purpose as a Group (under Us as a Group) was removed in the final version. This was because, as the analysis progressed, we increasingly observed that, in terms of our research aims, the most important aspect of how people saw their groups was the balance (and at times tension) between a tendency to ‘look inwards’ at processes and relationships and a willingness to ‘look outwards’ to how the group related to lives beyond the meetings and to the wider community.
병합
Merging
브룸빌에 대한 인식 아래 초기 템플릿에서 우리는 2단계 테마로 월드 곤 다운 더 플러골(World Gone Down the Plughole)을 포함했다. 이것은 일반적으로 세상이 과거에 비해 덜 안전하고 친근하며 살기 편한 곳이라는 관점을 포착했다. 우리는 이러한 견해와 브룸빌이 어떻게 쇠퇴했는지에 대한 구체적인 의견을 구분했으며, 통합 주제인 수축 아래에서 이를 포착했다. 아래의 인용문은 두 가지 주제를 보여줍니다.
On the initial template under Perceptions of Broomville we included as a second- level theme World Gone Down the Plughole. This captured the view that the world in general was a less safe, friendly and comfortable place to live in than it had been in the past. We distinguished such views from specific comments about how Broomville had declined, which we captured under the integrative theme Shrinkage. The quotes below illustrate the two themes:
풀숲으로 사라진 세계
World Gone Down the Plughole
하지만 요즘은 어디가 살기 좋은가요? 여러분 중 안전하다고 느끼시는 분은요? 밤에 밖에 나갈 수 없어요
But where is nice to live these days? Where do, do you feel safe, any, any of you, well I can’t go out at night. (Maureen, Exercise Group) Shrinkage
내 말은 저 위에 있는 가게들은 솔직히 신경 쓸 가치가 없고, 가격도 비싸고, 종류도 다양하지 않다는 거야… 지금 당장 브룸빌을 떠나야만 물건을 살 수 있어. (로저, 커피명언)
I mean the shops up there are frankly not worth bothering, they’re very expensive and they haven’t got the variety … You’ve got to leave Broomville, get out of Broomville to get your stuff, now. (Roger, Coffee Morning Group)
템플릿을 더 개발하면서 위에서 만든 구별이 의미 있는 것인지 여부에 대해 점점 더 불확실해졌다. 결국 우리는 참가자들의 의견의 어조를 더 잘 압축했다고 생각했기 때문에 "풀밭으로 간 세계"라는 제목을 사용하여 두 테마를 함께 병합하기로 결정했다.
As we developed the template further we became increasingly uncertain as to whether the distinction made above was a meaningful one. Eventually we decided to merge the two themes together, using the World Gone Down the Plughole title as we felt it better encapsulated the tone of participants’ comments.
범위 변경
Changing the scope
최상위 테마인 Quality of Group(위의 내용 참조)을 삭제하고, 부속 테마인 Careing Yother와 그 하위 테마로 범위를 변경하였습니다. 우리는 집단 내에서의 '돌봄'의 개념이 그들의 정신의 한 측면으로 가장 잘 보여진다고 결론지었고, 따라서 마지막 템플릿에서 이것의 위계를 뒤집었다. 이를 통해 집단 간 에토스의 차이를 '돌봄'의 개념에 포함되었을 때보다 더 명확하게 이해할 수 있었다.
Having deleted the top-level theme Quality of Group (see above), we made changes in scope to the subsidiary theme Caring for Each Other and its sub-themes. We concluded that the notion of ‘caring’ in the groups was best seen as an aspect of their ethos and therefore reversed the hierarchical order here on the final template. This enabled us to get a clearer understanding of the differences in ethos between the groups than was the case when ethos was subsumed under the notion of ‘caring’.
고차분류변경
Changing the higher order classification
이전의 예에서는 그룹의 Ethos가 Looking Inside로 2단계 테마로 이동했기 때문에 고차 분류의 변경과 테마의 범위 변경을 포함했다. 이것은 그들 너머의 세상과 관련된 집단이 어떻게 방치될 수 있었는지를 우려하는 정신의 측면에서 잠재적인 어려움을 야기했다. 우리는 이것을 Ethos의 확산/공유라는 제목의 Looking Outwards 아래에서 세 번째 수준의 주제를 구성하여 다루었습니다.
The previous example involved a change in the higher order classification as well as a change in the scope for the themes, since Ethos of Group moved into the second-level theme Looking Inward. This created a potential difficulty in that aspects of ethos that concerned how groups related to the world beyond them could have been neglected. We addressed this by constructing a thirdlevel theme under Looking Outwards entitled Spreading/Sharing the Ethos.
'최종' 템플릿
The ‘final’ template
분석 템플릿을 구성할 때 가장 어려운 결정 중 하나는 개발 프로세스를 어디에서 중단해야 하는가이다. 거의 초기 단계까지 코드의 정의를 수정하고 다듬는 것은 가능하지만, 연구과제는 외부 제약에 직면할 수밖에 없어 '이상적' 템플릿을 만들기 위한 시간이 무제한은 아니다. 템플릿이 '충분히 좋은' 경우에 대한 결정은 항상 특정 프로젝트에만 적용됩니다. 그러나 연구 질문과 관련이 있지만 코드화되지 않은 텍스트 섹션이 남아 있는 경우 템플릿은 '최종'으로 간주할 수 없습니다.
One of the most difficult decisions to make when constructing an analytical template is where to stop the process of development. It is possible to go on modifying and refining definitions of codes almost ad infinitum, but research projects inevitably face external constraints which will mean that there is not unlimited time to produce an ‘ideal’ template. The decision about when a template is ‘good enough’ is always going to be unique to a particular project. However, no template can be considered ‘final’ if there remain any sections of text that are clearly relevant to the research question but stay uncoded.
템플릿 분석 해석 및 표시
Interpreting and Presenting Template Analysis
해석
Interpretation
[템플릿을 개발하고, 이를 사용하여 일련의 스크립트를 코딩하는 것]은 [데이터를 분석하고 해석하는 프로세스]의 끝을 나타내지 않는다. 단순히 주제를 나열하고, 각각에 대한 주요 결과만 요약한다면 그것은 데이터에 대한 매우 단순한 설명이 될 것이다. 코드화된 데이터의 해석을 함께 그리는 정확한 방법은 특정 연구의 목적과 내용에 따라 달라집니다. 제가 유용한 출발점이 될 수 있는 몇 가지 지침과 예를 제시하겠습니다.
Developing a template and using it to code a set of transcripts does not represent the end of the process of analysing and interpreting the data. If the themes are simply listed and the main findings summarized under each this will result in a very flat description of the data. Exactly how to go about drawing together an interpretation of the coded data depends on the aims and content of the particular study. I will offer some guidelines and examples that may serve as a useful starting point.
코드 나열
Listing codes
나는 보통 각 전사transcript에서 발생하는 [모든 코드 목록과 빈도를 표시하는 것]이 초기 단계에 유용하다고 생각한다. 사본 내 및 사본 전체에 코드를 배포하면 추가 검사를 필요로 하는 데이터 측면에 주의를 끌 수 있다. 예를 들어, 한 세트를 제외한 모든 인터뷰 내용에서 주제가 두드러지게 나타난다면, 한 가지 예외를 자세히 살펴보는 것이 드러날 수 있다. 또는 특정 주제가 샘플의 한 하위 집합의 사본에서 자주 발생하지만 다른 하위 집합의 사본에서는 거의 발생하지 않는 경우, 이것이 둘 사이의 관점이나 경험에서 의미 있는 차이를 예시할 수 있는지 여부를 고려해야 한다. 그러나 주제의 빈도와 분포 패턴은 면밀한 검토가 필요한 영역을 제안할 수 있지만, 그것 자체로 의미 있는 것을 알려줄 수는 없다.
I usually find it useful at an early stage to compile a list of all codes occurring in each transcript, with some indication of their frequency. The distribution of codes within and across transcripts can help to draw attention to aspects of the data that warrant further examination. For example, if a theme occurs prominently in all but one of a set of interview transcripts, it may be revealing to look closely at the one exception. Or if certain themes occur frequently in the transcripts of one sub-set of the sample but hardly ever in another, whether this may exemplify a meaningful difference in views or experiences between the two should be considered. Note, though, that while frequencies of themes and the patterns of their distribution may suggest areas for closer examination, they cannot in and of themselves tell us anything meaningful.
선별성
Selectivity
어떤 주제를 깊이 있게 검토해야 하는지 선별적으로 파악할 필요가 항상 있다. 어떤 핵심 테마가 초점이 되어야 하는지에 대한 결정을 서두르지 않는 것이 중요하며, 최종 템플릿에 보존된 어떤 선험적 테마가 이들 중 포함되어야 한다고 자동으로 가정해서는 안 된다. 마찬가지로, 집중해야 할 주제들의 우선순위를 위에서 설명한 것처럼 단순한 빈도에 근거해서는 안 된다. 오히려 과제는 각 주제(또는 테마 클러스터)가 관심 주제를 어떻게 조명하는지 신중하게 고려하는 것이다.
There is always the need to be selective in identifying which themes to examine in depth. It is important not to rush to a decision about which key themes should be the focus, and it should not automatically be assumed that any a priori themes retained in the final template should be included among these. Equally, prioritizing themes to focus on should not be based on mere frequency, as explained above. Rather the task is to consider carefully how each theme (or cluster of themes) sheds light on the topic of interest.
개방성
Openness
데이터를 분석하고 해석할 때 [선별성]이 필요하나, 동시에 데이터에 대한 [개방성]과 균형을 이루어야 한다. 연구자는 명백히 직접적인 관련없다면 주제를 모두 무시할 정도까지 초기 연구 질문에 의해 경도되어서는 안 된다. 조금이라도marginal 관련성이 있다고 판단되는 주제는 긴 설명을 요구하지 않고 연구의 배경 세부 사항을 추가하는 데 유용한 역할을 할 수 있다. 더 문제가 되는 것은 참가자들에게 분명히 매우 중요하지만, 연구 범위를 훨씬 벗어난 것처럼 보이는 주제들이다. 이러한 경우, '제외된' 주제에 대한 조사가 연구의 중심 주제에 대한 이해에 유의미한 빛을 던져주는지에 대한 신중한 검토가 이루어져야 한다. 만약 그렇다면, 그것은 해석에 포함되어야 합니다.
The need to be selective in analysing and interpreting data must be balanced against the need to retain openness towards it. The researcher must not be so strongly guided by the initial research questions that all themes that are not obviously of direct relevance are disregarded. Themes that are judged to be of marginal relevance can play a useful role in adding to the background detail of the study, without requiring a lengthy explication. More problematic are those themes that are clearly of great importance to participants, but which seem to lie well outside the scope of the study. In such cases, there should be a careful consideration of whether the investigation of the ‘excluded’ theme casts any significant light on the understanding of central themes in the study. If it does, then it should be included in the interpretation.
테마 간 관계
Relationships between themes
해석을 진행하면서 [강조되어야 하는 주제 간에 관계가 있는지]를 고려하여 [통합적 주제] 및 다른 [측면 연결]를 포함하도록 템플릿이 설계되었는지 검토해야 한다. 예를 들어, 커뮤니티 그룹 참여 연구에서, 우리는 세대 간 및 인종 간 문제 중 일부(최종 템플릿의 주제 2.1.1 및 2.1.2)가 그룹 내 역학(테마 1.1.3)에 나타났다는 것을 인식하고 이를 보고서에 반영했다(King et al., 2009). 때로는 보고서 작성의 발견과 논의에서 그러한 연관성을 끌어내는 것으로 충분할 것이다. 대신, 크랩트리와 밀러(1999)가 제안하듯이 지도, 행렬 및 기타 도표를 사용하여 템플릿 분석 결과를 탐색하고 표시할 수 있다.
Whether or not the template has been designed to incorporate integrative themes and/or other lateral links, as the interpretation proceeds consideration should be given to whether there are relationships between themes that need to be highlighted. In the community group participation study, for instance, we recognized that some of the intergenerational and inter-racial issues (themes 2.1.1 and 2.1.2 on the final template, Figure 24.2) were manifest in the intragroup dynamics (theme 1.1.3) and reflected this in our report (King et al., 2009). Sometimes it will be sufficient to draw out such connections in the findings and discussion of the write-up. Alternatively, as Crabtree and Miller (1999) suggest, maps, matrices and other diagrams can be used to explore and display template analysis findings.
발표
Presentation
마지막 작업은 데이터 해석에 대한 설명을 제시하는 것입니다. 템플릿 분석의 다른 단계와 마찬가지로, 이를 위한 하나의 '올바른' 방법을 정의하는 것은 잘못된 것입니다. 데이터의 특성, 생성할 문서의 유형(단어 길이 포함), 그리고 중요한 것은 의도된 독자성을 고려해야 한다는 것이다. 마찬가지로, 발표를 위한 [세 가지 접근법]이 가능하다.
The final task is to present an account of the interpretation of the data. As with other stages of template analysis, it would be wrong to try to define one single ‘correct’ way to do this. The nature of the data, the type of document to be produced (including its word length) and, critically, the intended readership need to be considered. All the same, it is possible to identify three approaches to presentation, any one of which might prove useful.
1 개별 사례 연구, 사례 간의 차이점과 유사성에 대한 토론이 뒤따른다. 이것은 독자들이 개별 참가자들의 관점을 잘 이해할 수 있게 해준다. 그러나 상대적으로 참가자가 많은 경우 이 형식은 독자에게 혼란을 줄 수 있고 반복적일 수 있으며, 각 사례에 대한 적절한 설명을 제공하기에 충분한 공간이 있어야 한다.
1 A set of individual case studies, followed by a discussion of the differences and similarities between cases. This gives the reader a good grasp of the perspectives of individual participants. However, where there are a relatively large number of participants, this format can be confusing for the reader and repetitive, and it does rely on there being sufficient space to provide an adequate description of each case.
2 식별된 주요 테마를 중심으로 구성된 account를 제시하고, 필요에 따라 각 사본(또는 그 밖의 텍스트)에서 예시를 도출. 이것은 가장 쉽게 명확하고 간결한 주제 토론을 만들어 내는 접근법인 경향이 있다. 위험은 지나친 일반화, 그리고 개인의 경험의 시력을 잃는 것이다.
2 An account structured around the main themes identified, drawing illustrative examples from each transcript (or other text) as required. This tends to be the approach that most readily produces a clear and succinct thematic discussion. The danger is one of over-generalization, and losing sight of individual experiences.
3 연구 결과를 주제별로 제시하고, 각각의 주요 주제를 설명하기 위해 다른 개별 사례 연구를 사용. 이는 상기 (1)과 (2)의 유용한 통합이 될 수 있다. 핵심 과제는 데이터 전체의 주제를 공정하게 나타내는 방식으로 사례를 선택하는 것이다.
3 A thematic presentation of the findings, using a different individual case study to illustrate each of the main themes. This can be a useful synthesis of approaches (1) and (2) above; the key challenge is to select the cases in a way that fairly represents the themes in the data as a whole.
어떤 접근법을 취하든 참가자들의 직접 인용은 필수적이다. 여기에는 일반적으로 해석의 특정 지점을 이해하는 데 도움이 되는 짧은 인용구와 더 광범위한 구절이 포함되어 독자들에게 원문의 향미를 제공해야 한다.
Whatever approach is taken, the use of direct quotes from the participants is essential. These should normally include both short quotes to aid the understanding of specific points of interpretation and more extensive passages, giving readers a flavour of the original texts.
기술의 장점과 단점
Advantages and Disadvantages of the Technique
템플릿 분석의 가장 큰 장점은 모든 연구의 필요에 따라 수정할 수 있는 매우 유연한 접근법이라는 것이다. 그것은 처방과 절차라는 무거운 짐과 함께 오지 않으며, 따라서 조직 연구에 현상학적이고 경험적인 접근을 원하는 사람들에게 특히 환영 받는다. 동시에 질적 방법에 대해 상대적으로 익숙하지 않은 이들이 이 기법의 원리를 쉽게 파악할 수 있기 때문에 전체 분야에 대한 귀중한 소개가 될 수 있다. 템플릿 분석은 협업 환경에서 일하는 다양한 직업이나 특정 조직의 변화에 영향을 받는 다른 직원의 등급과 같은 조직 환경 내에서 다양한 그룹의 관점을 검토하고자 하는 연구에서 매우 효과적입니다. 마지막으로, 템플릿 제작 분야는 연구자가 데이터를 처리하기 위해 체계적이고 잘 구조화된 접근법을 취하도록 강제한다.
Arguably, the greatest advantage of template analysis is that it is a highly flexible approach that can be modified for the needs of any study. It does not come with the heavy baggage of prescriptions and procedures and, as such, is especially welcome to those who want to take a phenomenological and experiential approach to organizational research. At the same time, the principles behind the technique are easily grasped by those relatively unfamiliar with qualitative methods and so it can be a valuable introduction to the whole field. Template analysis works very well in studies that seek to examine the perspectives of different groups within an organizational context – for example, different professions working in a collaborative setting or different grades of staff affected by a particular organizational change. Finally, the discipline of producing the template forces the researcher to take a systematic and well-structured approach to handling the data.
템플릿 분석에서 [코딩 구조coding structure]를 강하게 강조하는 것은 일부 연구자들에 의해 다소 대조적인 두 가지 이유로 인해 단점으로 보일 수 있다. 한편으로, 이러한 강조는 텍스트에 대한 매우 개방적이고 구조화되지 않은 참여를 선호하는 사람들을 위해 데이터에 대한 개인적인 참여를 방해할 가능성이 있는 것처럼 보일 수 있다. 반면에, 어떤 사람들은 템플릿을 개발하는 것이 목적(데이터의 의미를 이해하는)을 위한 수단이며 그 자체로 분석의 목적이 아니라는 이전의 중요한 점을 무시한 채 템플릿 구성의 세부사항에 지나치게 집중하는 것에 너무 쉽게 현혹될 수 있다. 이러한 두 가지 입장에 대응하여, 나는 템플릿 분석의 유연성이 연구자들이 자신의 스타일과 질적 데이터 분석에 대한 입장에 맞게 조정할 수 있도록 해야 한다고 주장하지만, 결국 모든 사람에게 적합한 것은 아닐 것이다.
The strong emphasis on the coding structure in template analysis may be seen as a disadvantage by some researchers, for two rather contrasting reasons. On the one hand, this emphasis may seem potentially to stand in the way of a personal engagement with the data for those whose preferred style is a very open, unstructured engagement with texts. On the other hand, some may be too easily seduced into focusing excessively on the details of template construction, neglecting the crucial point made earlier that developing the template is a means to an end (making sense of the data) and not the purpose of the analysis in itself. In response to both these positions I would argue that the flexibility of template analysis should allow researchers to tailor it to suit their own style and stance towards qualitative data analysis, though in the end as with any analytical technique this will not suit everyone.
결론
Conclusion
템플릿 분석은 조직 연구와 그 이상에서 질적 데이터의 주제적 분석에 널리 사용되는 기법이 되었다. 그것의 인기의 주요 이유는 특정 연구의 내용과 사용된 인식론적 위치 모두에서 특정 요구에 적응할 수 있는 유연성과 명확하고 구조적이며 체계적인 접근법이 결합되었기 때문이다. 저는 이 장이 이 기술을 처음 접하는 연구자들이 자신의 연구에 어떻게 활용하는지, 그리고 이 기술에 이미 익숙한 사람들이 어떻게 그들의 분석적 관행을 창의적으로 발전시킬 수 있는지에 대한 새로운 아이디어를 얻었기를 바랍니다.
Template analysis has become a widely used technique for the thematic analysis of qualitative data, in organizational studies and beyond. The main reasons for its popularity, I would suggest, are its combination of a clear, structured and systematic approach with the flexibility to adapt it to specific needs – both in terms of the content of particular studies and the epistemological positions used. I hope this chapter has given a sense of how researchers new to the technique might go about employing it in their own research; and that those already familiar with the technique may have garnered some new ideas for how to creatively develop their analytical practice.
'Articles (Medical Education) > 의학교육연구(Research)' 카테고리의 다른 글
| 질적 내용분석: Trustwothiness에 초점을 두고(SAGE Open, 2014) (0) | 2022.03.14 |
|---|---|
| 보건전문직 교육에서 질적 에고 네트워크: 나를 타인과의 관계 속에서 잡아내기(Med Educ, 2022) (0) | 2022.01.20 |
| 질적연구인터뷰 수행의 열두 가지 팁 (Med Teach, 2018) (0) | 2021.12.23 |
| 포화라는 위장 뒤에 숨은 것: 질적 인터뷰 자료와 견고함 (J Grad Med Educ, 2021) (0) | 2021.12.23 |
| 효과적으로 질적연구 결과 섹션을 쓰는 세 가지 원칙 (Focus on Health Professional Education, 2021) (0) | 2021.12.23 |