의학교육에서 기준선 설정: 고부담 평가(Understanding Medical Education 3rd Ed, Ch 24)
24 Standard Setting Methods in Medical Education: High‐stakes Assessment
Andre F. De Champlain
Research and Development, Medical Council of Canada, Ottawa, Ontario, Canada

의사 결정의 필요성
The Need to Make Decisions
사람, 객체, 사물을 '분류classification'하는 의사결정의 필요성은 일상적인 것에서 가장 중요한 것에 이르기까지 일상생활의 모든 측면에 스며 있다. 예를 들어 운전면허 취득을 위한 시험에 합격하려면 교통법규 및 성과(합격, 평행주차 등)에 관한 일정 수준의 숙련도를 갖추어야 한다. 이러한 분류의 목적은 안전하지 않은 운전자들이 차량의 운전대를 잡지 못하게 하는 것이다. 마찬가지로, 형사 재판에서 판결을 내리는 배심원단은 사건의 증거(즉, 관련 자료 분석)를 신중하게 검토한 후 피고를 '유죄' 또는 '무죄'로 '분류'하는 혐의를 받는다. 배심원단은 여러 측면에서 평가에서 표준 설정과 유사하다.
The need to make decisions that assign people, objects, or things into ‘classifications’ permeates all aspects of daily life, from the mundane to the most significant. For instance, passing an examination to obtain a driver’s licence requires meeting a certain level of proficiency with regard to knowledge of traffic laws and performance (passing, parallel parking, etc.). The aim of such a classification is to keep unsafe drivers from getting behind the wheel of a vehicle. Similarly, a jury that renders a verdict in a criminal trial is charged with ‘classifying’ a defendant as ‘guilty’ or ‘not guilty’, after carefully weighing the evidence of a case, i.e. analysing relevant data. The jury analogy seems particularly relevant to standard setting in assessment on a number of counts:
• 두 활동 모두 모집단에서 충분히 크고 대표적인 참가자 집단이 필요하다(시민권 또는 직업권).
• Both activities require a sufficiently large and representative participant group from the population (whether a citizenry or a profession).
• 두 활동 모두 분류 목적으로 사용할 결정이 필요하다(판결 제출 또는 통과/실패 기준 설정).
• Both activities necessitate a decision that will be used for classification purposes (rendering a verdict or setting a pass/fail standard).
• 정보의 의도된 사용은 각 사례에서 매우 유사하다(형사 재판에서의 수용 및/또는 갱생과 그에 상응하는 공공의 보호 및 표준 설정에서의 교정조치 고려사항).
• The intended use of the information is very similar in each instance (incapacitation and/or rehabilitation in a criminal trial and the corresponding protection of the public and remediation considerations in standard setting).
의사 결정의 필요성 또한 학부 의학 교육에서 재검증까지 의사 생활의 모든 단계에서 중요한 부분입니다. 주요 결정은 의과대학 수준[8–12]뿐만 아니라 의과대학 수준[1]에서 자격증을 부여하거나 보유할 때, 또는 보유할 때, 또는 자격증은 [3–5] 또는 전문기관[6, 7]에 대한 진입을 허용하거나 거부할 때 발생한다. 이러한 결정은 기준선 설정standard setting이라고 하는 프로세스를 통해 이루어집니다. Cizek [13]은 기준선 설정을 '[두 개 이상의 상태 또는 성과 정도를 구별]하기 위하여 [숫자의 할당]을 초래하는 [규정되고 합리적인 규칙 또는 절차의 적절한 추종]'(예: 통과/실패)으로 설명한다. 졸업자뿐 아니라 자격증 및 면허 소지자가 안전한 임상 실습을 허용하는 지식과 기술을 보유하고 있는지 확인해야 한다는 점을 감안할 때, 보건 전문가 내에서 이 활동은 특히 중요합니다 [14, 15]. 그럼에도 불구하고 용어 컷 점수 및 합격 기준에 대한 기본적인 오해는 여전히 지속되고 있습니다(박스 24.1 참조).
The need to make a decision is also part‐and‐parcel of all phases of a physician’s professional life, from undergraduate medical education to revalidation. Key decisions occur when awarding or denying an unrestricted licence to practise medicine [1, 2], granting or withholding a credential [3–5], or granting or denying entry into a professional body [6, 7], as well as at the medical school level [8–12]. These decisions are arrived at through a process that is referred to as standard setting. Cizek [13] describes standard setting as ‘the proper following of a prescribed, rational system of rules or procedures resulting in the assignment of a number to differentiate between two or more states or degrees of performance’ (e.g. pass/fail). This activity is especially critical within the health professions, given the need to ensure the public that graduates as well as holders of certificates and licences possess the knowledge and skill sets that permit safe clinical practice [14, 15]. In spite of this, a basic misconception still persists regarding the terms cutscore and passing standard (see Box 24.1).
| BOX 24.1 정의 BOX 24.1 Definitions • 표준(기준선)은 성과 수준에 대한 질적 설명이며, 역량의 개념적 정의로 볼 수 있다. • 컷점수 또는 합격점수는 이 표준을 반영하는 숫자에 해당하며, 역량의 조작적 정의로 볼 수 있다. • A standard is a qualitative description of a level of performance and can be viewed as a conceptual definition of competence. • A cut‐score or passing score corresponds to a number that reflects this standard and can be viewed as an operational definition of competence |
표준 대 절단→점수
Standard Versus Cut‐score
기준과 참조 설정에서 시험 점수를 주로 사용하는 것은, 응시자가 [시험의 기초가 되는 것으로 추정되는 역량의 집합]을 숙달했는지 여부를 결정하는 것이다. 학교 수준이든, 면허 또는 인증 결정이든, 기준 설정은 합격 기준을 식별하기 위해 정기적으로 수행되며, 이는 중요하다고 간주되고 시험에 의해 측정되는 기술 영역의 숙달 또는 역량의 지표로 취급됩니다.
The primary use of any test score in a criterion‐referenced setting is to determine whether a candidate has mastered a set of competencies presumed to underlie performance on the examination. Whether at the school level or for licensure and/or certification decisions, standard setting exercises are routinely carried out to identify a passing standard, which is treated as an indicator of mastery or competency in the skill areas deemed important and measured by an examination.
케인[16]은 [합격기준passing standard]을 [실무에서 요구되는 허용 가능한 수준의 성과와 지식에 대한 질적 설명]으로 정의한다. 이와 같이 통과기준은 역량의 개념적 정의 또는 질적 정의로 볼 수 있다. 예를 들어, 최종 1년간의 학부 OSCE에서는 경계선 후보가 [감독된 의료에 진입하는 데 필요한 데이터 수집, 신체 검사 및 의사소통 기술을 입증]하도록 규정할 수 있다.
Kane [16] defines a passing standard as a qualitative description of an acceptable level of performance and knowledge required in practice. As such, the passing standard can be viewed as a conceptual or qualitative definition of competence. For example, in a final‐year undergraduate OSCE, a standard might stipulate that the borderline candidate demonstrate the data gathering, physical examination, and communication skills necessary for entry into supervised practice.
반면 [컷(cut) 점수]는 표준을 반영하는 점수 척도를 따르는 [숫자]입니다. 이것은 역량에 대한 조작적 정의입니다. 이전 예에서 전문가 패널리스트는 [65% 이상의 점수]를 받은 응시자가 최종 1년제 학부 OSE의 성과 표준을 충족했다고 판단할 수 있습니다.
The cut‐score, on the other hand, is a number along the score scale that reflects the standard. It is an operational definition of competence. In our previous example, expert panellists might decide that a candidate who scores at or above 65% has met the performance standard for the final‐year undergraduate OSCE.
표준 설정의 주요 고려 사항
Key Considerations in Standard Setting
[표준 설정standard setting]은 [점수 척도를 두 개 이상의 범주로 분할할 수 있도록 합리적이고 방어 가능한 방법으로 인간의 판단을 종합할 수 있는 과정]이다. [전문가의 판단]에 중점을 둔다는 점에서, 모든 [표준은 본질적으로 주관적]이라는 점을 강조하는 것이 중요합니다. 따라서 시험에서 컷-점수를 정할 때는 'gold standard'가 없다. 컷(cut) 점수는 표준과 참여 심판 패널 설정을 위해 선택한 방법을 포함하여 여러 요인의 함수로 달라질 수 있으며 이에 국한되지 않는다[17–21].
Standard setting is a process that allows human judgements to be synthesised in a rational and defensible way to facilitate the partitioning of a score scale into two or more categories. Given the emphasis on expert judgement, it is important to underscore that all standards are intrinsically subjective in nature. Consequently, there is no ‘gold standard’ when it comes to setting a cut‐score on an examination. Cut‐scores can and will vary as a function of several factors, including, but not limited to, the method selected to set the standard and the panel of participating judges [17–21].
Jaeger[18]는 '판단을 제공하는 사람들의 마음을 뺀다면, 아마도, (기준 설정에서의) 정답이 존재하지 않을 것이다'고 언급함으로써 이 점을 가장 잘 요약하였다. 적절한 경험적 증거로 뒷받침되는 체계적인 과정을 따르는 것은 표준 설정 패널이 (정책 기반) 판단을 방어 가능한 방식으로 점수 척도로 해석하는 데 도움이 될 수 있지만, 숙련자를 비숙련자로부터, 또는 통과자를 실패자로부터 완벽하게 구분하는 어떤 '참true' cutscore를 추정하는 데 사용할 수 있는 방법은 없다.
Jaeger [18] best summarised this point by stating that ‘a right answer (in standard setting) does not exist, except, perhaps, in the minds of those providing judgement’. Following a systematic process that is supported with appropriate empirical evidence can help standard setting panels translate (policy‐based) judgement onto a score scale in a defensible manner, but no method can be used to estimate some ‘true’ cut‐score that perfectly separates masters from non‐masters or passers from failers.
모든 표준 설정 프로세스의 [내재적 주관성]을 고려하여, 모범 사례는 배경 및 교육 특성과 관련하여 대상 시험 모집단을 광범위하게 대표하는 심판 패널의 선발을 필요로dictate 한다[22, 23]. 표준 설정 패널 구성은 의료 교육에서 평가가 복잡하다는 점을 감안할 때 훨씬 더 관련이 깊어집니다. 그들의 연공서열과 전문지식 수준에도 불구하고, 평가의 목적을 감안할 때 결과적인 컷(cut) 점수가 합리적인지 확인하기 위해서는 패널리스트에 대한 광범위한 교육이 필수적입니다 [24]. 적어도, 평가의 목표, 표준 설정의 목적, 완료를 요구하는 과제, 최소한의 숙련도 또는 경계선 성과를 구성하는 일반적인 정의 등과 관련하여 [모든 패널리스트가 서로 조화를 이루도록 보장하기 위한 교육]이 필요하다[25].
In view of the inherent subjectivity of any standard setting process, best practice dictates selection of a panel of judges that broadly represents the target examination population, with respect to background and educational characteristics [22, 23]. The composition of the standard setting panel becomes even more relevant given the complexity of assessments in medical education. Despite their seniority and level of expertise, extensive training of panellists is essential to ensure that the resulting cut‐score is reasonable given the objectives of the assessment [24]. If nothing else, training is necessary to ensure that all panellists are in harmony with one another in regard to the goal of the assessment, the purpose of the standard setting exercise, the task that they are asked to complete, and a general definition of what constitutes minimal proficiency or a borderline performance [25].
일반적인 표준 설정 교육 세션에는 다음과 같은 여러 단계가 필요합니다.
- (i) 패널리스트에 대한 검체 검사 자료의 제공
- (ii) 참가자에게 완료를 요구하는 과제의 명확한 표시
- (iii) 경계선 후보의 정의에 할당된 토론 기간
- (iv) 예시 세트에 대한 판단
- (v) 참가자 간의 오해를 명확히 하기 위한 토론 기간
- (vi) 훈련의 모든 측면에 대한 사후 조사[22].
A typical standard setting training session requires a number of steps including:
- (i) the provision of sample examination materials to panellists;
- (ii) a clear presentation of the task that participants are being asked to complete;
- (iii) a period of discussion allocated to the definition of the borderline candidate;
- (iv) judgements on a set of exemplars;
- (v) a discussion period to clarify any misconceptions amongst participants; and
- (vi) a post‐exercise survey on all aspects of training [22].
이러한 주의사항에도 불구하고, 이 장에 설명된 방법들은 결과적인 cut-score가 변덕스러운 판단보다는 정보에 입각한 판단에 근거하도록 보장하기 위해 따를 수 있는 체계적인 단계를 제공한다. 우선 검사의 절단 점수 결정을 위한 일반적인 방법의 개요(박스 24.2 참조)를 살펴보고, [표준 참조 표준]과 [기준 참조 표준]의 차이를 알아볼 것이다.
Despite these caveats, the methods outlined in this chapter will provide systematic steps that can be followed to ensure that the resulting cut‐score is defensible and based on informed, rather than capricious, judgements on the part of the expert panel. The difference between a normreferenced standard and a criterion‐referenced standard will first be reviewed prior to an overview of common methods for determining a cut‐score on an examination (see Box 24.2).
| BOX 24.2 주요 고려 사항 BOX 24.2 Key considerations • 표준 설정에는 'gold standard'가 없습니다. • 표준 및 그에 수반되는 감점 점수는 [역량을 구성하는 것에 대한 전문가의 판단]을 반영해야 하며, 몇 가지 근거 출처에 의해 뒷받침되어야 한다. • 표준 설정 패널은 성별, 연령, 전문 분야, 지리적 영역 등과 관련하여 모든 핵심 검사 이해 당사자를 폭넓게 대표하는 전문가로 구성되어야 한다. • 표준설정행위의 모든 측면에 대해 패널리스트를 철저히 교육하는 것은 채택된 방법에 관계없이 모든 표준 설정 연습의 성공에 필수적인 작업이다. • There is no ‘gold standard’ in standard setting. • A standard and accompanying cut‐score should reflect expert judgement as to what constitutes competence, supported by several sources of evidence. • A standard setting panel should be composed of experts who broadly represent all key examination stakeholders with respect to gender, age, specialty, geographical area, etc. • Thoroughly training panellists on all aspects of the exercise is a task critical to the success of any standard setting exercise, regardless of the method adopted. |
Norm → 참조 대 기준 → 참조
Norm‐ referenced Versus Criterion‐referenced Standards
아주 넓게 본다면, 표준은 성격상 [규범-참조] 또는 [준거-참조]로 분류될 수 있다[26].
At a very high level, standards can be classified as either norm‐referenced or criterion‐referenced in nature [26].
[규범 참조 표준]은 비교 후보 그룹의 성과에서 절단 점수가 도출된다는 점에서 [상대적인 표준]이다. 절단 점수를 클래스 평균보다 높은 표준 편차로 설정하거나 절단 점수를 분포의 90번째 백분위수 순위에서 고정하는 등, 표준 참조 표준의 예는 많습니다. 기본적인 개념은 컷아웃 점수가 비교 집단의 상대적 성과의 함수로만 설정된다는 것이다. 우리는 순전히 다른 응시자들이 얼마나 잘(또는 못) 시험을 잘 보느냐에 따라 응시자를 합격시키거나 불합격시킵니다.
A norm‐referenced standard is a relativestandard in that the cut‐score is derived from the performances of a comparative group of candidates. There are many examples of norm‐referenced standards, such as setting the cut‐score at one standard deviation above the mean of the class or fixing the cut‐score at the 90th percentile rank of a distribution. The fundamental notion is that the cut‐score is set solely as a function of the relative performances of a comparative group. We pass or fail a candidate on an examination purely based on how well (or badly) other test takers performed.
반면에, [준거 참조 프레임워크] 내에서, 표준은 일반적으로 그룹 성과에 관계없이 후보자가 입증해야 하는 영역의 지식의 함수로 설정된다. 따라서 이것은 절대적인 기준입니다. 예를 들어, 의료 전문가 패널은 전문적 판단과 검사의 목적에 따라 지원자가 최소의 역량을 갖춘 것으로 간주되려면 해당 영역의 70%를 마스터해야 한다고 결정할 수 있다.
On the other hand, within a criterion‐referenced framework, the standard is typically set as a function of the amount of knowledge of the domain that the candidate needs to demonstrate, irrespective of group performance. As such, it is an absolute standard. For example, a panel of medical experts might determine that a candidate needs to master 70% of the domain to be deemed minimally competent, based on their professional judgement and the objectives of an examination.
전문적 검사의 경우, 일반적으로 여러 가지 이유로 [준거 참조 표준criterion‐referenced standards]이 선호된다.
- 첫째, 규범 참조 표준은 그룹의 상대적 성과에 전적으로 기초하기 때문에 주어진 후보가 알고 있거나 모르는 것에 대해 거의 또는 전혀 언급하지 않는다.
- 둘째, 더 중요한 것은, 규범 참조 표쥰에서의 컷(cut) 점수는 [그룹의 능력 수준]에 따라 다양하다는 것이다.
For professional examinations, criterion‐referenced standards are generally preferred for a number of reasons.
- First, a norm‐referenced standard tells little to nothing about what a given candidate knows or does not know, since it is entirely based on the relative performance of the group.
- Second, and more importantly, the cut‐score selected in a norm‐referenced standard setting exercise will vary as a function of the ability level of the group.
응시자의 수준이 낮으면 낮은 cut-score를 낳을 것이며, 더 능력이 뛰어난 응시자들의 cut score는 더 높아질 것이다. 이는 결국 능력 수준에 따라 다양한 후보군을 배출합니다. 예를 들어, 평균보다 1-표준 편차(1SD)로 컷(cut) 점수를 설정하면 [응시자(집단)의 지식수준에 관계없이 코호트의 약 16%가 실패]합니다. 그러나, 이 그룹들은 도메인에 대한 지식에 있어 큰 차이가 있을 수 있습니다. 만약 그 수업이 능력 있는 학생 대 능력 없는 학생으로 구성되어 있다면 분포의 '평균에 가까운' 점수는 상당히 다른 의미를 가질 수 있다. 즉, [합격 수행능력(즉, '최소한의 역량')]의 의미는 후보자가 언제, 누구와 합격했는지에 따라서 달라질 수 있다.
Lower cut‐scores will result from the performances of less proficient candidates, whereas higher cut‐scores will be set with more able cohorts. This, in turn, produces cohorts of candidates who vary in regard to their level of competence. For example, setting a cut‐score at one standard deviation below the mean will result in failing about 16% of any cohort, irrespective of what candidates may or may not know. However, it is conceivable that these groups could differ drastically in their knowledge of the domains. Scoring ‘near the average’ of a distribution can have quite a different meaning if the class is composed of high ability candidates versus less able students. That is, the meaning of a passing performance (and consequently ‘minimal competence’) can vary as a function of when and with whom the candidate passed.
따라서, 통과 기준을 설정하는 norm‐referenced 접근법은 정치적 및 직업적 관점 모두에서 방어할 수 없다untenable. 표준 참고 표준을 사용할 수 있는 유일한 상황은 [소수의 지원자를 선발해야 할 때]입니다(예: 제한된 수의 대학원 연수 시간).
Consequently, a norm‐referenced approach to setting a passing standard is untenable from both political and professional perspectives. The only instance in which it may be acceptable to use a norm‐referenced standard is when the selection of a small number of candidates is necessary (e.g. for a restricted number of postgraduate training slots).
기준을 설정하는 Criterion‐referenced 방법은 이러한 많은 한계를 극복하기 때문에 매력적이다. Criterion‐referenced 방법을 사용하여 설정한 컷(cut) 점수는 특정 직업의 광범위한 분야를 대표하는 전문가들이 안전 실천에 필요한 기술과 지식을 보유한 후보자를 나타내는 숙련도 수준을 반영한다. 이러한 이유로, 의료 면허 분야뿐만 아니라 다른 보건 전문가 검사 프로그램에서도 몇 년 동안 Criterion‐referenced 설정 방법이 성공적으로 채택되고 옹호되어 왔다[1, 2, 27–29]. 다음 두 절에서는 가장 일반적으로 사용되는 기준 기준 설정 방법을 간략하게 설명합니다(박스 24.3 참조).
Criterion‐referenced methods for setting a standard are appealing because they overcome many of these limitations. A cut‐score that is set using a criterion‐referenced method reflects a level of proficiency that experts representing wide sectors of a given profession agree is indicative of a candidate who possesses the skills and knowledge required for safe practice. For this reason, criterion‐referenced methods for setting cut‐scores have been successfully employed and defended for several years in the medical licensing arena as well as with other health profession examination programmes [1, 2, 27–29]. The following two sections briefly describe the criterion‐referenced standard setting methods in most common use (see Box 24.3).
| BOX 24.3 표준 대 기준 → 기준 BOX 24.3 Norm‐referencing versus criterion‐referencing • 표준 참조 표준norm‐referenced standard 은 상대적 표준이며 임의의 후보 그룹 성과 함수로 설정됩니다. • 준거 참조 표준criterion‐referenced standard 은 절대적인 표준이며, 후보 그룹의 전체 성과에 관계없이 전문가가 역량을 반영한다고 생각하는 함수로 설정됩니다. • 의학 교육에서의 시험의 경우, 표준 참조 표준은 선발 목적으로만 적합하다. 대다수의 결정(졸업, 사무직 합격 등)에 대해서는 criterion‐referenced standard 이 적절합니다. • A norm‐referenced standard is a relative standard and set as a function of the performance of an arbitrary group of candidates. • A criterion‐referenced standard is an absolute standard and set as a function of what experts believe reflects competence, regardless of the overall performance of any group of candidates. • With medical education examinations, norm‐referenced standards are only appropriate for selection purposes. For the vast majority of decisions (e.g. graduation, passing a clerkship, etc.), criterion‐referenced standards are appropriate. |
테스트 중심 방법
Test‐ centred Methods
[준거-참조 테스트-중심 방법Criterion‐referenced test‐centred methods]은 객관식 검사와 같은 지식 평가에 대한 합격 점수를 설정하는 데 호소하고 있다. 이러한 표준 설정 형식에서, 전문가들은 시험 또는 과제의 각 항목에 요구되는 성능 수준을 판단하도록 요청받는다(예: 최소한의 숙련도). 자주 사용되는 일반적인 테스트 중심 방법에는 Angoff, Ebel, Nedelsky 및 Bookmark 절차[30]가 포함됩니다(상자 24.4 참조).
Criterion‐referenced test‐centred methods are appealing for setting a pass mark on knowledge assessments, such as multiple‐choice examinations. In this form of standard setting, experts are asked to judge the level of performance required on each item of the test or task to meet the standard (e.g. minimal proficiency). Common and frequently used test‐centred methods include the Angoff, Ebel, Nedelsky, and Bookmark procedures [30] (see Box 24.4).
| BOX 24.4 FOCUS ON: 시험 중심 방법 BOX 24.4 FOCUS ON: Test‐centred methods • MCQ의 경우, 표준은 일반적으로 테스트 중심test‐centred 방법을 사용하여 설정됩니다. 널리 사용되는 테스트 중심 방법에는 Angoff, Ebel, Nedelsky 및 Bookmark 방법이 포함됩니다. • 패널리스트가 시험 중심의 표준 설정 연습에서 최소한의 숙련도 있는 후보자에 대해 각 항목의 특성을 추정해야 하는 경우, 즉 Angoff 및 Bookmark 방법의 어려움, Ebel 방법과의 관련성, 그리고 추가로 Nedelsky 접근법으로 '추측'을 해야 하는 경우, 논의 훈련 단계에서 경계선 후보를 구성하는 것에 대한 폭넓은 합의가 매우 중요합니다. • Angoff 및 Bookmark 방법은 고유의 단순성으로 인해 MCQ 검사에 대한 표준을 설정하는 데 가장 일반적으로 사용됩니다. • Ebel과 Nedelsky 방법은 패널에게 더 강력한 인지 요건을 부과하는데, 이 요건들이 많은 시험에서 충족이 어려울 수 있다. 각각 관련성을 결정하고 경계선 후보가 주의 산만 요소를 제거할 가능성을 결정한다. • For MCQs, standards are typically set using a test‐centred method. Popular test‐centred methods include the Angoff, Ebel, Nedelsky, and Bookmark methods. • Given that panellists are essentially asked to estimate characteristics of each individual item for the minimally proficient candidate in a test‐centred standard setting exercise, i.e. difficulty with the Angoff and Bookmark methods, difficulty and relevance with the Ebel method, and additionally ‘guessing’ with the Nedelsky approach, discussion and broad agreement as to what constitutes a borderline candidate in the training phase is of critical importance. • The Angoff and Bookmark methods are most commonly used to set a standard on MCQ examinations due to their inherent simplicity. • The Ebel and Nedelsky methods impose stronger cognitive requirements on the part of panellists that may be difficult to meet with many examinations; respectively determining relevance as well as the likelihood that a borderline candidate will eliminate distractors. |
앙고프 방법
Angoff Method
Angoff 절차에서 패널리스트는 항목별로 각 항목에 정확하게 답변할 수 있는 [최소 숙련도 후보자의 비율]을 추정해야 한다[31]. 사실상 이것은 전문가의 판단에 근거하여 테스트의 각 구성 요소 부분의 [난이도를 평가]하는 것이다. 그런 다음 이러한 비율은 각 전문가 심판에게 합산됩니다. 일반적으로 심판의 항목 비율의 평균 또는 중위합은 검사에서 컷-점수로 처리됩니다. 상자 24.5는 세 개의 패널 목록을 사용한 5가지 항목 검사에 기초한 Anoff 절차에 대한 간단한 그림을 제공합니다. 이 예제에서 패널 목록 절단 점수는 1.35(또는 1/5)에서 2.65(또는 3/5) 사이였습니다. 따라서 전체 컷 점수가 1.97/5(또는 2/5)와 같으므로 최종 컷 점수를 선택할 수 있습니다.
In the Angoff procedure, panellists are asked to estimate, on an item‐by‐item level, the proportion of minimally proficient candidates that would answer each item correctly [31]. Effectively this constitutes an assessment of the degree of difficulty of each component part of the test based on expert judgement. These proportions are then summed for each expert judge. Typically, the mean or median sum of item proportions across judges is treated as the cut‐score on the examination. Box 24.5 provides a simple illustration of the Angoff procedure based on a five‐item examination with three panellists. In this example, panellist cut‐scores ranged from 1.35 (or 1/5) to 2.65 (or 3/5). An overall cutscore equal to 1.97/5 (or 2/5) could therefore be selected as the final cut‐score.

[수정된 Angoff 방법] 또한 표준의 결정을 위해 제안되었습니다 [9, 32–35]. 한 가지 수정방식으로는 패널리스트에게 일반적인 논의 후에 판단을 수정할 수 있도록 하는 것이다 [36]. 다른 수정방식으로는 패널리스트에게 [최종 라운드]에서 '현실 성과 점검reality performance check'을 제공함으로써, 최초 판단을 측정하고guage, 원하는 경우 수정할 수 있도록, 최초 등급 라운드 후에 규범적normative 데이터(예: 문항 난이도 및 변별도)를 제공하는 것이다[37].
Modified Angoff methods have also been proposed for determining a standard [9, 32–35]. One adaptation of the Angoff method allows panellists to modify their judgements following a general discussion [36]. Other revisions entail providing normative data (e.g. item difficulty and discrimination indices) following the initial round of ratings in order to provide panellists with a ‘reality performance check’ against which to gauge their initial judgements and modify them, if so desired, in a final round [37].
장점 및 제한 사항
Advantages and Limitations
Angoff 방법군의 주요 장점 중 하나는 MCQ 및 성능 기반 평가를 포함하여 다수의 검사와 함께 광범위하게 사용됐다는 것이다 [34]. 따라서, 그러한 연습을 수행하고자 하는 모든 연구자는 풍부한 증거와 정보를 이용할 수 있다. 또한 앙고프 방식은 패널리스트가 테스트 항목을 검토하고 재료 및 후보자에 대한 전문 지식을 바탕으로 판단을 내려야 한다는 점에서 어느 정도 직관적이라는 매력을 가지고 있다. 마지막으로 Angoff 방법은 '예/아니오' 방법을 통해 능률화할 수 있으며 [38] 방법은 작업을 더욱 단순화할 수 있습니다.
One main advantage of the Angoff family of methods is that they have been used extensively with a host of examinations, including both MCQ and performance‐based assessments [34]. As such, a wealth of evidence and information is available to any researcher interested in carrying out such an exercise. Also, the Angoff method holds a certain amount of intuitive appeal in that panellists are required to review test items and offer judgements based on their expert knowledge of the material and candidates. Finally, the Angoff method is amenable to streamlining such as through the ‘Yes/No’ method [38], which can simplify the task even more.
한편, Angoff 방법은 패널리스트가 완료해야 하는 두 가지 주요 과제의 본질적인 특성, 즉, [무엇이 최소한의 숙련도를 구성하는지]를 명확히 하고, 각 테스트 항목에 정답을 맞출 수 있는 [최소 숙련도 응시자의 비율을 일관되게 추정]하는 것 때문에 많은 비판을 받았다[35].
- Shepard [39]는 패널리스트에게 제시된 과제가 너무 인지적으로 어려우며 아마도 대부분의 참가자가 감당할 수 없을 것이라고 주장했다. 그러나 다른 이들은 이러한 주장을 반박하고 이러한 어려움을 패널리스트의 불충분한 교육이나 판단을 유도할 성능 데이터의 부재 때문이라고 지적했습니다 [40].
- Plake 외 연구진[41]에 의해 수행된 조사에서도 문항 성능 추정치item performance estimate는 패널 내부와 패널 간뿐만 아니라, 당해 및 수년 간에 걸쳐 고부담의 인증 검사를 위한 것으로 나타났다. 이러한 발견은 표준 설정 연습에 적합한 심판 패널 선택의 중요성을 다시 한 번 강조하고, 더 중요한 것은 당면 과제의 성격에 대한 오해를 없애기 위해 모든 전문가에게 광범위한 교육을 제공한다는 것이다.
On the downside, the Angoff methods have come under heavy criticism due to the inherent nature of the two main tasks that panellists are required to complete, namely to articulate what constitutes minimal proficiency and then consistently estimate proportions of minimally proficient candidates who would correctly answer each test item [35].
- Shepard [39] argued that the task presented to panellists was too cognitively challenging and probably beyond the capability of most participants. Others, however, have refuted this claim and ascribed these difficulties to insufficient training of panellists or the absence of performance data to guide judgements [40].
- Research conducted by Plake et al. [41] also showed that item performance estimates were consistent within and across panels, as well as within and across years for a high‐stakes certification examination. These findings once more underscore the importance of selecting appropriate panels of judges for standard setting exercises and, more importantly, offering extensive training to all experts to eliminate any misconceptions regarding the nature of the task at hand.
이러한 한계에도 불구하고, Angoff 방법군은 검사에 대한 컷☆스코어를 설정하기 위한 가장 보편적이고, 오래 지속되며, 잘 연구된 일련의 절차들 중 하나입니다 [30].
Despite these limitations, the Angoff family of methods continues to be one of the most prevalent, longstanding, and well researched set of procedures for setting a cut‐score on an examination [30].
에벨 방법
Ebel Method
에벨이 개괄적으로 설명한 절차는 패널리스트에게 각 항목에 대한 난이도 추정치뿐만 아니라, 검토의 기초가 될 것으로 추정되는 영역을 고려하여 내용 관련성까지 제공하도록 요청함으로써 Angoff의 방법을 확장한다[42]. 컷(cut) 점수는 [난이도]와 [관련성 판단]의 [곱셈값cross-products]을 추가하여 계산한다.
The procedure outlined by Ebel extends Angoff’s method by asking panellists not only to provide difficulty estimates for each item but also content relevance, given the domains that are presumed to underlie the examination [42]. The cut‐score is computed by adding the cross‐products of the difficulty and relevance judgements.
상자 24.6은 2차원 Ebel 그리드의 간단한 예를 제공합니다. 이 예에서 심사위원들은 50개 항목 중 5개가 내용에 필수적이며 난이도가 '쉬운' 수준이라고 느꼈다. 비슷한 맥락에서 패널리스트에게도 최소한으로 숙달된 후보자가 올바르게 답할 수 있는 각 내용 관련성/난이도 셀 항목의 비율을 추정하도록 요청받았다. 그 결과로 나온 절단 점수는 관련성/난이도 셀 교차성 제품의 합계입니다. 이 예에서 응시자는 시험에 합격하려면 25/50 항목(50%)을 올바르게 답해야 합니다.
Box 24.6 provides a simple example of a two‐dimensional Ebel grid. In this example, judges felt that 5 of 50 items were essential to the content and ‘easy’ level of difficulty. In a similar vein, panellists were asked to estimate the proportion of items, in each content relevance/difficulty cell, that the minimally proficient candidate would correctly answer. The resulting cut‐score is the sum of the relevance/ difficulty cell cross‐products. In this example, candidates would need to correctly answer 25/50 items (50%) to pass the examination.

장점 및 제한 사항
Advantages and Limitations
아이러니하게도, 기준 제정을 위한 Ebel 방법의 장점 중 하나인 [난이도] 외에 [항목 관련성]이 패널리스트의 판단에 반영될 수 있다는 것이 Ebel 방법의 약점이기도 하다. 예를 들어, Berk[43]는 패널리스트가 연습 중에 내용(난이도)과 목적적합성 판단을 [분리할 수 있는지]에 의문을 제기한다. 이 두 차원이 많은 경우 상당히 높은 상관관계를 갖는다고 주장한다. 시험 개발의 관점에서, 시험에는 애초에 [관련성이 낮은 항목]을 포함시키는 것이 더 나은 것이 아닌가라는 의문을 제기할 수 있다. 대부분의 맥락에서, 총점은 (상호 관계가 있는) 여러 도메인에서 후보자들의 역량을 전반적으로 반영하는 것으로 해석됩니다. 따라서 (Ebel 방법에서) [관련성이 낮다고 여겨지는 항목]은 전체적인 역량(예: 합격/불합격)이나 순위에 대한 추론에 거의 기여하지 않는다.
Ironically, one advantage of the Ebel method for setting a standard, namely that item relevance, in addition to difficulty, can be factored into panellists’ judgements, is also its chief weakness. Berk [43], for example, questions the ease with which panellists can separate content (difficulty) and relevance judgements during an exercise, largely based on the argument that these two dimensions are often correlated quite highly. From a test development standpoint, one could also question the merits of including test items that are not relevant in an examination. In most contexts, the total score is interpreted as an overall reflection of candidates’ competencies on a composite of (interrelated) domains. Consequently, items that are deemed irrelevant contribute little to nothing in informing inferences about overall competency (e.g. pass/fail) or standing.
네델스키 방법
Nedelsky Method
네델스키[44]는 [(응시자가) MCQ에 답할 때, 최소한 숙련도 있는 후보들이 먼저 재료에 대한 지식을 바탕으로 부정확하다고 식별한 옵션을 제거한 다음 나머지 선택 항목 중에서 무작위로 추측한다는 전제] 하에 이뤄지는 표준 설정 방법이다. 실제 컷(cut) 점수는 나머지 대안 수의 역수 항목 전체의 합에 해당합니다. 예를 들면, 패널리스트 그룹은 5가지 항목, [5개 문항 MCQ 시험]에서 [최소한 숙달된 후보자]가 각 항목에 걸쳐 2, 1, 3, 4개의 옵션을 각각 제거할 것으로 추정한다. 따라서 네델스키 절단 점수는 1/3 + 1/4 + 1/2 + 1/2 + 1/1 = 2.58/5 또는 3/5 60%에 해당합니다.
Nedelsky [44] outlined a standard setting method based on the premise that when answering MCQs, minimally proficient candidates first eliminate options that they identify as incorrect based on their knowledge of the material, and then randomly guess amongst remaining choices. The actual cut‐score corresponds to the sum across items of the reciprocal of the remaining number of alternatives. To illustrate; assume that a group of panellists estimates that the following number of options would be eliminated, respectively, by the minimally proficient candidate on a five‐item, five‐option MCQ examination: 2, 1, 3, 3, 4, across each of the items. The Nedelsky cut‐score would therefore correspond to: 1/3 + 1/ 4 + 1/2 + 1/2 + 1/1 = 2.58/5 or 3/5 60%
장점 및 제한 사항
Advantages and Limitations
네델스키 방법의 주요 장점은 패널리스트가 판단을 내릴 때 [보기distractors 요소의 품질], 즉 MCQ에 대답할 때 최소한의 숙달된 후보자가 가질 수 있는 부분적 지식을 고려할 수 있다는 것이다. 그러나 이 절차의 여러 단점들로 인해 어려움을 겪는다는 것이 잘 문서화되어있다. 첫째, 패널리스트에 부과된 과제는 Angoff 또는 Ebel 연습에서 예상되는 것보다 훨씬 더 부담스럽다. 패널리스트는 최소한의 숙련도 있는 응시자의 정확한 응답 확률을 추정해야 할 뿐만 아니라, 후자의 시험 응시자가 distractor가 부족하거나 부분적인 지식으로 인해 제거할 수 있다고 믿는 옵션에 비추어 그렇게 해야 합니다.
The main advantage of the Nedelsky method is that it allows panellists to factor in the quality of the distractors when making their judgements, that is, any partial knowledge that the minimally proficient candidate may possess when answering an MCQ. However, the procedure also suffers from a number of well‐documented shortcomings. First, the task imposed on panellists is much more onerous that what is expected in either an Angoff or Ebel exercise. Panellists must not only estimate the probability of a correct response on the part of the minimally proficient candidate, but they must do so in light of options they believe the latter test taker can eliminate either due to poor distractors or partial knowledge.
또한 절차의 특성으로 인해 패널리스트가 제공할 수 있는 확률 값이 사실상 제한된다. 예를 들어, MCQ 옵션이 5개인 경우 판사가 제공할 수 있는 타당한 추정치는 0.20, 0.25, 0.33, 0.50 및 1.00 [43]뿐입니다. 즉, 최소 숙련도 응시자는 신뢰할 수 없는 경우 0, 1, 2, 3 또는 4 옵션을 제거할 수 있습니다.
Additionally, probability values that are provided by panellists are de facto restricted due to the nature of the procedure. For example, with a five‐option MCQ, the only plausible estimates that judges can provide are: 0.20, 0.25, 0.33, 0.50, and 1.00 [43]. That is, the minimally proficient candidate can eliminate either 0, 1, 2, 3, or 4 options as non‐plausible.
마지막으로, 가장 중요한 것은 네델스키 방법에서 [최소한의 숙련도 응시자의 시험 응시 행동이 동일하다고 가정한다]는 것이다. 즉, 그러한 대안에서 타당성이 없는 것으로 제거되지 않은 것과 동일한 방식으로 추측한다는 것이다. 위험 행동, 차등 부분 지식 및 기타 요소를 고려할 때 이러한 가정에 대한 의문이 심각하게 제기되었다[45, 46]. 이러한 한계를 다루기 위해 절차의 수정이 제안되었지만[47], 네델스키 방법은 그 내재적 복잡성과 더 많이 사용되는 방법에 비해 실질적인 효익이 거의 없기 때문에 지난 수십 년간 인기가 떨어졌다.
Finally, and most importantly, the Nedelsky method assumes that the test‐taking behaviour of minimally proficient candidates is identical, i.e. they guess in the same fashion from those alternatives not eliminated as implausible. This assumption has been seriously called into question given risk behaviours, differential partial knowledge, and other factors [45, 46]. Though modifications of the procedure have been proposed to address these limitations [47], the Nedelsky method has waned in popularity over the past few decades due to its inherent complexity and few practical benefits over more popular methods.
책갈피 방법
Bookmark Method
또한 책갈피 방법은 [본질적 단순성]으로 인해 절단 점수를 설정하는 데 상당히 정기적으로 사용됩니다[48]. 이 접근방식으로 [시험 문항이 가장 쉬운 것부터 어려워지는 순서로 패널리스트에 제시]됩니다(책자 한 페이지당 한 항목). 이 방법의 원래 의도는 항목 대응 이론(IRT) 기반 난이도 추정의 함수로 항목의 순서를 정하는 것이었지만, 방법을 조정하고 간단한 p-값(정확한 응답의 비율)으로 MCQ를 정렬하는 것도 가능하다. 각 패널 목록은 최소한 숙달된 후보자가 나머지 항목에 올바르게 답변하지 못할 것으로 예상되는 지점에 책갈피(정지 규칙stopping rule)를 배치해야 합니다.
The Bookmark method is also used quite regularly to set a cut‐score due to its intrinsic simplicity [48]. With this approach, test items are presented to panellists by order of difficulty from least to most difficult (one item per page in a booklet). Though the original intent of the method was to sequence the items as a function of item response theory (IRT)‐based difficulty estimates, it is also possible to adapt the method and order the MCQs by simple p‐values (proportion of correct responses). Each panellist is required to place a bookmark (a stopping rule) beyond which a minimally proficient candidate would not be expected to correctly answer remaining items. Note that the
책갈피 방법은 여러 단계로 구분해야 하는 경우(예: 초급, 중급, 고급 수준의 결정)에 자주 사용된다. 가장 간단한 애플리케이션에서 최종 절단 점수는 여러 패널 목록에서 책갈피 항목 중 [중위수]에 해당합니다. 원래의 책갈피 절차에서도 이 절단 점수를 기본 IRT 가능성 측정 기준[48]으로 변환했다는 점을 지적하는 것이 중요합니다. 성능 벤치마크를 추가하는 방법의 확장도 제안되었습니다 [49, 50]. 이러한 개정에 대한 자세한 내용을 얻고자 하는 독자는 이 참고 자료를 참조할 것을 권장합니다.
Bookmark method is also frequently employed for multiple judgements (e.g. determining levels of basic, proficient, and advanced). The final cut‐score, in its simplest application, would correspond to the median number of items at the bookmark across panellists. It is important to point out that the original Bookmark procedure also translated this cut‐score to the underlying IRT ability metric [48]. Extensions of the method that entail adding the use of performance benchmarks have also been proposed [49, 50]. Readers wishing to obtain more details on these revisions are encouraged to consult these references.
장점 및 제한 사항
Advantages and Limitations
Bookmark 방법의 주요 장점은 [단순성]과 패널 목록에 부과되는 비교적 [낮은 인지 부하]입니다. 적어도 다른 테스트 중심 방법과 비교됩니다. 시험 항목은 난이도(참가자에게 알려지지 않음)에 따라 정렬되며, 패널리스트는 둘 이상의 숙련도 범주를 설명하기 위해 하나 또는 여러 개의 북마크를 배치해야 합니다. 책갈피 방법의 또 다른 매력적인 특징은 혼합 형식mixed-format 평가뿐만 아니라 객관식 및 수행능력 검사에 쉽게 적용할 수 있다는 점이다. 마지막으로, IRT 숙련도 메트릭스에 대한 전통적인 연계는 대부분의 대규모 테스트 프로그램이 시험 구축, 채점, 규모 조정 및 등식을 포함한 다수의 활동에 [IRT 기반 방법을 구현]한다는 점에서 큰 매력을 가지고 있다. 따라서 북마크 표준 설정 방법은 unified IRT 프레임워크에 쉽게 통합될 수 있습니다.
The main advantage of the Bookmark method is its simplicity and the relatively light cognitive load that is imposed on panellists, at least in comparison to other testcentred methods. Test items are ordered according to difficulty (again, unbeknownst to participants) and panellists are required to place one or several bookmarks to delineate two or more proficiency categories. Another attractive feature of the Bookmark method is that it can be readily applied to multiple‐choice and performance examinations as well as mixed‐format assessments. Finally, its traditional link to an IRT proficiency metric also holds great appeal given that the majority of large‐scale testing programmes implement IRT‐based methods for a host of activities, including test construction, scoring, scaling, and equating. As such, the Bookmark standard setting method can easily be integrated into a unified IRT framework.
이러한 장점에도 불구하고 책갈피 표준 설정 방법에는 실무자가 알아야 할 여러 가지 제한이 있습니다.
- 첫째, 책갈피 표준 설정 연습의 컷(cut) 점수는 시험 양식의 난이도와 불가분의 관계에 있다. 예를 들면, 응시자의 숙련도 대비 매우 '쉬운' 시험을 떠올려 볼 수 있다. 이는 최초 응시자의 90% 이상이 전형적으로 합격하는 의료 면허 및 인증 시험의 경우에 해당됩니다 [27]. 이 'mis-targeting'으로 인해 패널 목록이 적절한 책갈피를 설정하지 못할 수 있습니다. 경우에 따라서는 응시자군의 능력이 높을 때에는 책자의 마지막(=가장 어려운) 문항조차도 너무 쉬워서 숙련자와 비숙련 구분할 수 없다고 보는 것이 타당하다. 다른 사람들이 [30]을 언급했듯이, 이 문제는 다른 테스트 중심 방법과도 함께 발생할 수 있습니다. 책갈피 접근법은 품목의 난이도 때문에 이러한 문제를 명백하게 만듭니다.
- 또 다른 실질적인 한계는 일부 문항의 퍼포먼스가 낮아서 삭제할 경우 소책자(즉, 페이지당 하나의 항목이 있는 경우 테스트 항목)를 재주문해야 한다는 것이다.
- 마지막으로 문항이 테스트 양식 전체에 걸쳐 난이도가 낮음에서 높음으로 일정하게 배치되지 않을 수 있으며, 실제로도 문항의 난이도가 그렇지 않을 수도 있다는 것입니다. 따라서 패널리스트가 마스터와 비 마스터를 가장 잘 구별하는 척도를 따라 실제 포인트를 식별하기가 어려울 수 있다. 즉, 문항 난이도에 gap이 있을 경우 책갈피를 식별할 수 없을 수 있다.
Despite these advantages, the Bookmark standard setting method does possess a number of limitations that the practitioner should be aware of.
- First and foremost, the cut‐score in a Bookmark standard setting exercise is inextricably linked to the difficulty of the test form. To illustrate, consider a test that is very ‘easy’ in relation to the proficiency level of candidates. This is often the case with medical licensing and certification examinations where over 90% of first‐time test takers typically pass [27]. This ‘mis‐targeting’ can make it impossible for panellists to set an appropriate bookmark. In certain instances, it is plausible that even the last item in a booklet is too easy to distinguish between masters and non‐masters when the candidate sample is highly able. As others have mentioned [30], this problem could also crop up with other test‐centred methods. The Bookmark approach, by virtue of item difficulty ordering, makes any such problems glaringly obvious.
- Another practical limitation of this standard setting method is that booklets (i.e. test items if there is one item per page) need to be re‐ordered if some items are deleted due to poor performance.
- A final limitation is that items may not, and in fact are probably not, evenly spaced in terms of differences in difficulty from low to high throughout a test form. Thus, it might be difficult for panellists to identify an actual point along the scale that best discriminates between masters and non‐masters, i.e. the bookmark might not be identifiable given gaps in item difficulty.
이러한 제약이 책갈피 방법을 무효화하지는 않지만 실무자는 이러한 잠재적 이슈를 인식하고 실제 기준 설정 연습 전에 그에 따라 계획을 수립해야 한다.
While these limitations do not invalidate the Bookmark method, practitioners should be aware of these potential issues and plan accordingly prior to the actual standard setting exercise.
수험생 중심 방법
Examinee‐ centred Methods
반면에 [준거(Criteria)-참조, 응시자-중심 방법examinee‐centred methods]에는 자격을 갖춘 전문가 패널 그룹의 글로벌 성과 판단에 근거한 표준 설정이 포함된다. 의학교육에서 성과 평가의 통합된 다차원적 특성을 고려할 때, 후자의 방법은 OSCE에 대한 컷(cut) 점수를 설정하는 데 특히 적합하다[51]. 두 가지 일반적인 검사자 중심 표준 설정 방법은 대조군 방법과 경계선 그룹 방법이다[52, 53]. (박스 24.7 참조).
Criterion‐referenced examinee‐centred methods, on the other hand, involve setting a standard based on global judgements of performance by a group of qualified expert panellists. Given the integrated, multi‐dimensional nature of performance assessments in medical education, the latter methods are particularly well suited for setting a cut‐score on OSCEs, for example [51]. Two popular examinee‐centred standard setting methods are the contrasting groups method and the borderline group method [52, 53]. (see Box 24.7).
| BOX 24.7 FOCUS ON: 수행능력 평가를 위한 표준 설정 BOX 24.7 FOCUS ON: Standard setting for performance assessments • OSCE 및 작업장 기반 평가와 같은 [수행능력 시험]의 경우 일반적으로 검사자 중심의 방법을 사용하여 표준을 설정합니다. 일반적인 검사자 중심 표준 설정 방법에는 대조 그룹 및 경계선 그룹 방법이 포함됩니다. • 이러한 방법은 패널리스트가 전반적으로overall holistic 수행능력을 판단할 수 있도록 하기 때문에 수행능력 평가에 매우 적합하고 매력적이다. 패널리스트는 두 개 이상의 숙련도 범주(예: 마스터/비매스터, 허용되지 않음, 허용 경계선, 명확하게 허용 가능 등)에 후보를 배정할 것을 요구합니다. • 매력적이지만, 이러한 방법은 본질적으로 패널을 'gold standard'로 취급합니다. 따라서 경계선 성능의 정의뿐만 아니라 작업이 잘 이해되도록 충분한 교육이 필요합니다. • 검사자 중심의 표준 설정 방법을 구현할 때 다음을 포함한 여러 가지 기술적 문제를 고려해야 합니다. (i) 위양성 및 위음성 분류와 관련된 비용을 결정해야 한다. (ii) 경계선 허용 집단borderline acceptable group에 할당된 응시자 수가 충분히 크게 구성되도록 보장해야 한다. (iii) 대조 그룹 방법의 경우, 패널리스트가 두 가지 카테고리 중 하나에 후보를 할당할 능력이 있어야 한다. • For performance examinations, such as OSCEs and workplace‐ based assessments, examinee‐centred methods are generally used to set a standard. Common examinee‐centred standard setting methods include the contrasting groups and borderline group methods. • These methods are appealing and well‐suited to performance assessment as they allow panellists to provide overall holistic judgements of performance. They require panellists to assign candidates to two or more proficiency categories (e.g. master/non‐master, unacceptable, borderline acceptable, clearly acceptable, etc.). • While appealing, these methods inherently treat the panel as the ‘gold standard’. Ample training is therefore necessary to ensure that the task is well understood as well as the definition of borderline performance. • A number of technical issues need to be considered when implementing any examinee‐centred standard setting method, including: (i) determining the costs associated with false‐positive and false‐negative classifications; (ii) ensuring that the borderline acceptable group is composed of a sufficiently large number of candidates; and (iii) for the contrasting groups method, assuring that panellists are able to assign candidates to one of two categories. |
대조 그룹 방법
Contrasting Groups Method
대조 그룹 방법에서 패널리스트는 각 후보자에게 수행능력 프로파일(예: OSCE 스테이션의 검사 목록 및 등급 척도)을 검토하고 테스트 응시자가 시험에 합격할 자격이 있는지 여부를 판단하도록 요청받습니다. 그런 다음 두 후보 그룹(무자격 및 자격)에 대한 OSCE 측점 점수가 그래프에 표시됩니다. 일반적으로 두 그룹의 테스트 응시자를 가장 잘 구별하는 점수는 컷★점수로 선택됩니다[52–54].
In the contrasting groups method, panellists are asked, for each candidate, to review a performance profile (e.g. checklists and rating scales on an OSCE station) and determine whether the test taker is qualified or unqualified to pass the examination. OSCE station scores for both groups of candidates (unqualified and qualified) are then plotted on a graph. The score that best discriminates between both groups of test takers is typically selected as the cut‐score [52–54].
예시를 위한 대조 그룹 그림은 그림 24.1에 나와 있습니다. 이 예에서, 위양성과 위음성 결정이 동등하게 중요할 경우, 교차 구역의 중간점을 절단 점수 값으로 선택할 수 있다. 단, 검사의 목적이 부정행위로부터 환자를 보호하는 것이라면 교차구역 상부의 값을 선택할 것이다(위양성 결정 최소화, 즉 합격을 위해 필요한 임상 기술을 보유하지 않은 합격자의 수 최소화).
A sample contrasting‐groups plot is shown in Figure 24.1. In this example, the mid‐point of the intersection zone could be selected as the cut‐score value if false-positive and false‐negative decisions were of equal importance. However, if the intent of the exam is to protect patients from malfeasance, a value in the upper part of the intersection zone would be chosen (minimising false‐positive decisions, i.e. minimising the number of passing candidates who do not possess the clinical skills necessary to pass).

경계선 그룹 방법
Borderline Group Method
경계선 그룹 방법에서 패널리스트는 각 후보자에 대한 성능 프로파일을 검토하고 [허용가능한 수행능력]과 [허용불가능한 수행능력]을 식별하라는 요청도 받습니다. 또한 패널리스트는 허용 가능한 성과 수준에 불과하다고 판단되는 후보자를 지정해야 합니다. 그런 다음 합격자의 점수가 그래프에 표시됩니다. 일반적으로 [중위수median 점수 값]이 검사의 cut score로 선택됩니다[1, 53]. 이 접근법의 한 가지 한계는 borderline acceptable group의 크기가 상당히 작기 때문에 [매우 불안정한 절단 점수(예: 중위수) 값]을 낳을 수도 있다는 것이다.
In the borderline group method, panellists are also asked to review a performance profile for each candidate and identify unacceptable as well as acceptable performances. Additionally, panellists must designate those candidates that are deemed to lie just at a borderline acceptable performance level. The scores of these borderline acceptable examinees are then plotted on a graph. Typically, the median score value is chosen as the cut‐score on the examination [1, 53]. One limitation that has been raised with this approach is that the size of the borderline acceptable group might be quite small, thus contributing to a very unstable cut‐score (e.g. median) value.
이러한 단점을 해결하기 위한 수단으로 [경계 회귀법borderline regression method]이 대안적인 관련 표준 설정 방법으로 제안되었다. 이 절차에서는 선형 회귀 모델링을 사용하여 점수 척도의 절단 점수를 등급 범주(예: 허용되지 않음, 허용 가능, 허용 가능)의 함수로 예측합니다. 즉, 특정 OSCE 스테이션의 합격 점수는 후보 점수(예: 체크리스트 점수)를 글로벌 등급으로 회귀시켜 획득합니다. 기존의 경계선 그룹 방법과는 달리, (borderline acceptable candidate의 점수 뿐만 아니라) [모든 데이터 포인트]가 컷 점수를 결정하는 데 사용됩니다 [55].
As a means of addressing this shortcoming, the borderline regression method was proposed as an alternative, related standard setting method. As it implies, this procedure uses linear regression modelling to predict the cut‐score on the score scale as a function of the rating categories (e.g. unacceptable, borderline acceptable, acceptable). That is, the pass mark for a given OSCE station is obtained by regressing candidate scores (e.g. checklist scores) onto the global ratings. Unlike the more traditional borderline group method, all data points are used in determining the cutscore, not only those associated with borderline acceptable candidates [55].
장점 및 제한 사항
Advantages and Limitations
대조집단 및 경계집단 방법은 패널리스트에게 [응시자의 전반적인 성과를 두 가지(또는 그 이상) 범주로 분류]하는 방식으로 전반적 판단holistic judgement하도록 요구한다]는 점에서 매우 유사하다. 실제로 경계집단법을 전문가들이 성과에 대한 허용여부를 판단할 필요가 있을 뿐만 아니라 '가장자리(on the cusp)' 즉, 허용가능한 경계에 대한 접근방식의 일반화로 생각할 수 있다. 두 방법 간의 유사성이 높다는 점을 감안할 때, 이 방법들이 동일한 장점과 한계를 가지고 있다는 것은 별로 놀랄 일이 아니다.
The contrasting groups and borderline group methods are very similar in that they require panellists to make holistic judgements on the overall performance of candidates by classifying them into two (or more) categories. In fact, one could conceive of the borderline group method as a generalisation of the contrasting groups approach where experts not only need to determine whether a performance is acceptable or unacceptable, but also ‘on the cusp’, i.e. borderline acceptable. Given the high degree of similarity between the methods, it should come as little surprise that they carry the same advantages and limitations.
한편, 두 가지 방법 모두 패널리스트가 보다 '직관적'인 작업을 완료하도록 요구하기 때문에, [OSCE 및 작업장 기반 평가와 같은 수행능력 평가]에서 종종 선호됩니다. 즉, 후보자를 unacceptable, acceptable 또는 borderline acceptable로 분류합니다. 또한 분류 판단을 내리는 차원들dimensions이 종종 높은 관련성을 갖는다는 점을 고려할 때, 이러한 복잡한 평가에 매우 적합하다. 따라서 이러한 방법은 [후보자에 대한 분류 결정을 내릴 때] [패널리스트가 모든 고려사항을 통합할 수 있는 관용성]을 제공한다.
On the plus side, both methods are often preferred for performance assessment such as OSCEs and workplacebased assessments as they require panellists to complete a task that is more ‘intuitive’, i.e. classify candidates as either unacceptable, acceptable, or borderline acceptable. They are also well suited to these complex assessments given that dimensions on which to make classification judgements are often highly related. As such, these methods provide panellists with the latitude to incorporate all of their considerations when arriving at a classification decision with a candidate.
(두 가지 접근법 모두) 패널리스트에게 높은 수준의 유연성을 제공한다는 점이 주된 한계가 된다. 두 방법 모두 패널리스트 판단을 [본질적으로 신뢰할 수 있고 타당한 것]으로 간주합니다. 즉, gold standard으로 간주합니다. 패널리스트가 이러한 판단을 내릴 수 있는 능력을 손상시킬 수 있는 요소는 예측하기 어려운 방식으로 최종 컷(cut)-점수 가치를 편향시킴으로써, [일부 후보군에 명백히 불공정한 표준]으로 이어질 수 있습니다. 따라서 주최자는 패널리스트에게 적절히 교육을 제공하여, 이러한 영향을 최소화하고, 궁극적으로 모든 이해관계자에게 방어 가능한 프로세스를 보장할 수 있도록 하는 것이 중요하다. 심사 대상자에게 매우 친숙할 수 있는 패널리스트가 판단을 제공할 때 [construct‐irrelevant factors] 에 의해 영향을 받는 시나리오를 쉽게 예상할 수 있다. 이러한 construct‐irrelevant factors 에는 성별, 민족성, 복장, 성격, 작업 습관 및 광범위하게 정의된 바와 같이 '능력'과 무관한 무수한 기타 외부 특성이 포함될 수 있다.
The greater level of flexibility that is afforded by both approaches also potentially constitutes their chief limitation. Both methods treat panellist judgements as intrinsically reliable and valid, i.e. as thegold standard. Any factor that can detract from the panellists’ ability to provide such judgements will bias the ultimate cut‐score value in a way that is difficult to predict and will lead to a standard that is most certainly unfair to subgroups of candidates. Consequently, the moderator plays a critical role in ensuring that the training offered to panellists can at least minimise this effect to ultimately assure a defensible process for all stakeholders. It is easy to envisage a scenario where panellists, who might very well be familiar with the candidates who they are evaluating, are affected by construct‐irrelevant factors when providing their judgements. Such construct‐irrelevant factors might include gender, ethnicity, dress, personality, work habits, and a myriad of other extraneous features that are unrelated to ‘competency’, as broadly defined by the examination.
대조 그룹과 경계선 그룹 방법 모두 [cut score 설정을 위해, 현장에서 충분히 많은 대표 전문가 그룹을 식별할 수 있으며, 이들이 지시에 따라 과제를 완료하도록 훈련할 수 있다]는 기본적인 전제에 의존한다. [부적절한 훈련]은 (borderline acceptable 에 불균형적으로 많은 수의 후보자를 할당하는 것과 같은) 다수의 바람직하지 않은 결과를 초래할 수 있다[56, 57].
Both the contrasting groups and borderline group methods also rest on the central premise that a sufficiently large group of representative professionals in the field can be identified for an exercise and also trained to complete the task at hand as instructed. Inadequate training can lead to a number of undesirable outcomes, including the propensity to assign disproportionally large number of candidates to the borderline acceptable group [56, 57].
이는 후자 그룹의 실적에서 점수가 나온다는 점에서 매력적으로 들릴 수 있지만, 거의 모든 응시자를 허용 가능한 경계선으로 분류하는 것은 시험, 교육 및 기타 요인에 대한 심각한 문제를 제기한다. 또한 확인하기 어려운 방식으로 다시 편향된 컷 스코어를 산출합니다.
While this may sound appealing, given that the cut‐score is derived from the performances of the latter group, classifying nearly all candidates as borderline acceptable seriously raises questions about the quality of the examination, instruction, and other factors, while yielding a cut‐score that is again biased in ways that are difficult to ascertain.
이 점과 관련하여, 경계선 그룹 방법은 후자 그룹이 충분히 큰 숫자로 구성되어야 합니다. 그렇지 않으면 그 결과로 얻어진 cut-score는, (가장 단순한 경우의 중위수 점수 또는 보다 복잡한 통계 모델링에 기초한 예측 값(예: 로지스틱 회귀 분석, 잠재 클래스 분석 등)이든), 불안정하고 '역량'을 부적절하게 반영할 것이다. 전통적인 대조집단 표준 연습에서 요구되는 과제의 이분법적 성격을 고려할 때, 패널리스트는 borderline acceptable performance라는 선택지가 없을 때, 허용가능과 허용불가능으로 나누기 어려울 수 있다. Plake와 Hambleton[56]은 의사결정 척도의 세밀한 축척을 허용하는 방법의 확장을 제안했다.
Related to this point, the borderline group method does require that the latter group be composed of a sufficiently large number or the resulting cut‐score, whether the median score in the simplest case or a predicted value based on more complex statistical modelling (e.g. logistic regression, latent class analysis, etc.), will be unstable and inappropriately reflect ‘minimal competency’. Given the dichotomous nature of the task that is required in a traditional contrasting groups standard exercise, it might also be difficult for panellists to classify candidates as either unacceptable or unacceptable, with no option for a borderline acceptable performance. Plake and Hambleton [56], amongst others, proposed an extension of the method that does allow for a finer gradation of the decision scale.
마지막으로, 두 가지 방법 모두 의료 교육자가 응시자를 잘못 분류했을 때의 결과를 요약하는 정책을 명확히 수립하는 것이 중요합니다. [국민의 보호가 최우선 고려 대상]인 경우 위양성(불합격해야 할 응시생의 합격)과 위음성(합격해야 하는 응시생의 불합격) 결정을 동등하게 다루는 것은 바람직하지 않을 수 있다. 이 경우, 위양성 분류를 최소화하는 것이 더 큰 관심사이다. 반대로 부담이 낮은lower stake 설정에서는 거짓 음성 오류를 최소화하는 정책도 완전히 수용가능하다.
Finally, it is critical, for both methods, that the medical educator clearly set a policy that outlines the consequences of misclassifying a candidate. Treating both false‐positive (passing a candidate who should have failed) and false‐negative (failing a candidate who should have passed) decisions equally might be quite undesirable in instances where protection of the public is of prime consideration. Under the latter scenario, minimising false‐positive classifications is of greater concern. Conversely, in lower‐stakes settings, minimising false‐negative errors could be perfectly acceptable as a policy.
패널리스트에 전달된 엄청난 책임을 감안할 때 대조 그룹 및 경계선 회귀 방법과 관련된 모든 잠재적 제한은 그러한 표준 설정 연습에서 사회자moderator가 수행해야 하는 역할이 중요함을 다시 강조한다. 실제로 사회자moderator가 경계선 그룹 또는 대조 그룹 표준 설정을 '좌지우지make or break' 할 수 있다고 해도 과언이 아니다.
All of the potential limitations associated with the contrasting groups and borderline regression methods, given the immense responsibility that is conveyed upon panellists, again underscore the critical role that the moderator needs to play in such standard setting exercises. Indeed, it is not an exaggeration to state that the moderator can ‘make or break’ a borderline group or contrasting groups standard setting exercise.
호프스티 방법
Hofstee Method
기준 설정을 위한 준거 참조 접근법을 사용할 때, [의사결정과 관련된 정치적 고려]를 전혀 하지 않는다면, 수용할 수 없는 결과를 초래할 수 있다. 즉, 표준 설정의 결과로 얻어진 컷(cut) 점수는 지나치게 크거나 작은 비율의 후보를 합격하시키거나 불합격시키지 말아야 한다. 예를 들어, 특정 의료 전문 검사가 지속적으로 15%의 응시자 중 불합격시켜왔다고 가정해 보십시오. 또한 이 모집단은 매년 매우 유사하고 능력 면에서 우수하다고 가정한다. Angoff 연습 후 설정한 컷(cut) 점수가 후보자의 50%를 낙제시키는 결과를 가져온다면, 그 표준은 비현실적이며 정책적 관점에서 매우 받아들일 수 없을 것이다.
The use of criterion‐referenced approaches for setting a standard can lead to unacceptable outcomes in the absence of political considerations associated with the decision. That is, the cut‐score arrived at following a standard setting exercise should not result in failing or passing an unacceptably large or small proportion of candidates. To illustrate, assume that a given medical specialty examination has consistently failed around 15% of candidates. Further assume that this population is very comparable, ability wise, from year to year. If the cut‐score set after an Angoff exercise results in failing 50% of candidates, the standard is unrealistic and might very well be unacceptable from a policy standpoint.
Hofstee [58]는 '현실 확인reality check'을 제공하는 수단으로 패널 목록에 다음 질문을 하고 그에 대한 답을 (Hofstee) 플롯에 표시함으로써 '타협compromise'하는 방법을 제안했다.
As a means of providing a ‘reality check’, Hofstee [58] proposed a ‘compromise’ method that involves asking panellists the following questions, the answers to which are subsequently graphed in a (Hofstee) plot:
• 내용 전체를 고려할 때 최대 및 최소 허용 컷 점수는 얼마입니까? 이러한 값은 일반적으로 Hofstee 그림에서 Cmin 및 Cmax로 표시됩니다.
• Considering the content as a whole, what are the maximum and minimum tolerable cut‐scores? These are typically labelledCminandCmaxon the Hofstee plot.
• 최대 및 최소 허용 불합격률은 얼마입니까? 이러한 값은 일반적으로 Hofstee 플롯에 Fmax 및 Fmin으로 나열됩니다.
• What are maximum and minimum tolerable failure rates? These are usually listed as Fmax and Fmin on the Hofstee plot.
Hofstee 그림의 예는 그림 24.2에 나와 있습니다.
An example of a Hofstee plot is provided in Figure 24.2.
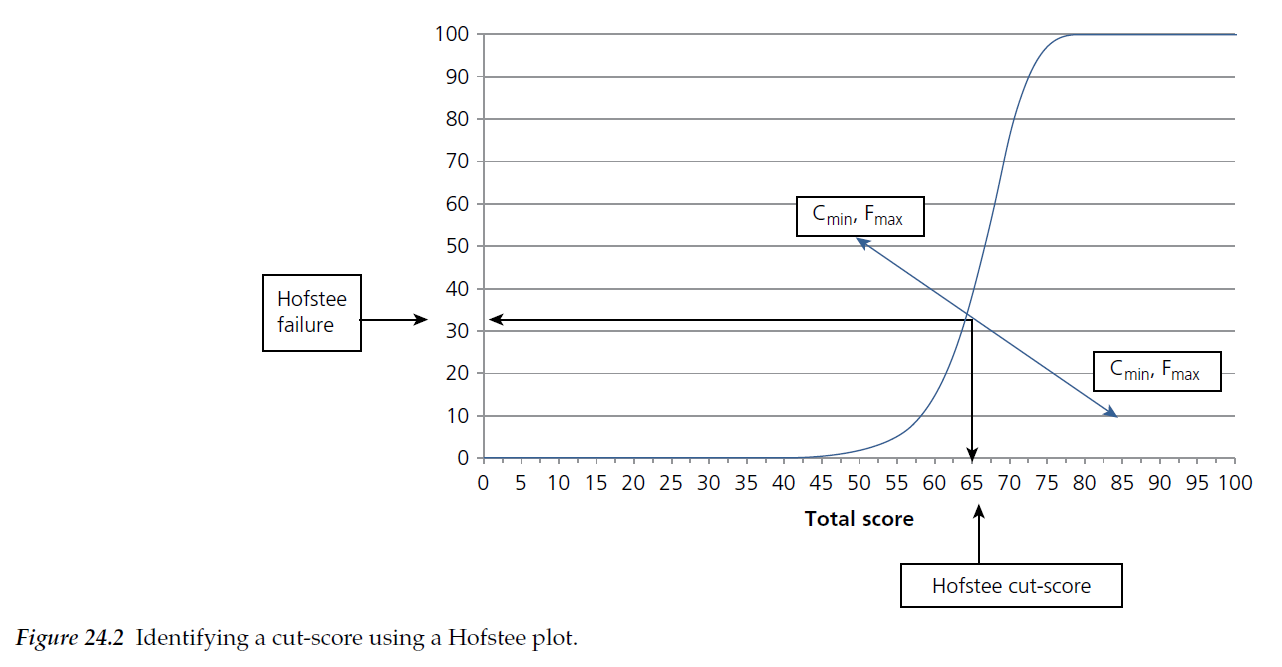
이 그림을 생성하려면 먼저 정확한 누적 백분율 분포를 계산해야 합니다. 이 분포는 점수 척도에 따라 각 지점에서 불합격할 후보자의 누적 비율을 요약합니다. 그런 다음 좌표(Cmin, Fmax)와 (Cmax, Fmin)를 그림 24.2와 같이 직선으로 표시하고 결합합니다. 이 직선과 분포곡선 사이의 교차점이 [Hofstee cut-score]에 해당합니다. 절단 점수는 x축에 표시된 'cut' value로 표시됩니다.
In order to create this plot, a cumulative percentagecorrect score distribution needs to first be computed. This distribution outlines the cumulative percentage of candidates who would fail at each point along the score scale. Then, the coordinates (Cmin, Fmax) and (Cmax, Fmin) are plotted and joined by a straight line, as illustrated in Figure 24.2. The point of intersection between this line and the frequency distribution corresponds to the Hofstee cut‐score. The cut‐score is illustrated by the ‘cut’ value shown on the x‐axis.
그림 24.2에 설명된 예에서 패널리스트는 컷☆스코어가 55(Cmin) 이하, 85(Cmax) 이하가 되어야 한다고 생각했습니다. 마찬가지로, 고장률은 최소 10%(Fmin)여야 하지만 50%(Fmax)보다 높으면 안 된다는 것을 나타내었습니다. 두 좌표 세트를 모두 연결하고 x축에 선을 그리면 Hofstee 컷스코어 값 65가 생성되어 후보 코호트의 약 35%가 불합격합니다. Hofstee 방법의 목적은 일반적으로 기준 기준 표준이 Hofstee 기반 값의 근처에 속하는지 여부, 즉 기준 표준이 절단 점수 값과 고장률의 정치적 고려사항 및 전역적 인상과 일관되는지 여부를 결정하는 것이다[59].
In the example outlined in Figure 24.2, panellists felt that the cut‐score should be no lower than 55 (Cmin) and no higher than 85 (Cmax). Similarly, they indicated that the failure rate should be at least 10% (Fmin) but not higher than 50% (Fmax). Linking both sets of coordinates and drawing a line down to the x‐axis yields a Hofstee cut‐score value of 65, which would result in failing about 35% of the candidate cohort. The aim of the Hofstee method is generally to determine whether criterion‐referenced standards fall within the vicinity of the Hofstee‐based value, i.e. whether they are consistent with political considerations and global impressions of cut‐score values and failure rates [59].
장점 및 제한 사항
Advantages and Limitations
Hofstee 방법의 주요 장점은 패널리스트가 [거의 또는 아무런 제한 없이 컷-점수 값과 불합격률에 대한 전체적인 판단]을 제공할 수 있다는 것입니다. 패널리스트는 경험, 테스트 내용에 대한 지식 및 검사 목표에 따라 성능 매개변수 한계를 정의해야 합니다. Hofstee 방법을 구현할 수 있는 유연성과 용이성 또한 주요 한계입니다. 즉, 이 방법은 일반적으로 [1차 기준 설정 방법이 아니라], 시험자 중심의 다른 접근방식을 보완하기 위한 ['reality check' 또는 대체 방법]으로 간주된다.
The primary advantage of the Hofstee method is that it allows panellists to offer holistic judgements on cut‐score values and failure rates with few to no constraints. Based on their experience, knowledge of the test content, and objective of the examination, panellists must define performance parameter limits. The flexibility and ease with which one can implement the Hofstee method also constitutes its chief limitation. That is, it is not generally viewed as a primary standard setting method but rather as a ‘reality check’ or fall‐back method meant to complement other approaches, whether test‐ or examinee‐centred.
이처럼 Hofstee 방법은 supportive한 역할을 한다고 했을 때, 실무자가 패널 리스트의 일반적인 기대치에 따라 더 전통적인 방법으로 설정된 컷-스코어가 사라지는지를 판단하는 데 도움이 되는 귀중한 정보를 제공할 수 있습니다. 그러나 그러한 특수성을 고려할 때 일반적으로 개별 측정치로 사용해서는 안 된다. 의료 교육 분야에서 점점 더 많이 사용되는 표준 설정의 또 다른 방법은 박스 24.8에서 논의된다.
Within this supporting context, the Hofstee method can provide valuable information that can help the practitioner gauge whether a cut‐score set with a more traditional method gibes with the general expectations of panellists. However, it should generally not be used as a standalone measure given its ad hoc nature. Another more controversial method of standard setting increasingly used in the medical education arena is discussed in the Box 24.8.
| BOX 24.8 FOCUS ON: Cohen 방법 BOX 24.8 FOCUS ON: The Cohen method Anoff와 같은 표준 설정 방법은 리소스를 많이 소모하고 시간이 많이 소요됩니다. 직원 수가 적고 재원이 제한된 교수진은 신뢰할 수 있고 유효한 방법에 필요한 충분한 수의 전문가를 모으기 위해 애쓸 수 있습니다. Cohen 방법은 '최우수' 학생(95번째 백분위 또는 P95에서의 학생 점수)이 기준점으로 사용되는 의료 교육에서 점점 더 많이 사용되는 표준 설정의 대안 형태입니다[10]. 의료 교육자는 이 높은 성과를 내는 그룹 점수 중 어느 비율이 컷 점수로 허용되는지 결정합니다(예: 60% × P95). 수정된 Cohen은 프로그램 내에서 여러 기준과 참조 시험의 과거 데이터가 전문가 패널이 예상하는 합격 점수를 더 잘 반영하도록 이 Cohen 합계를 개인화할 수 있다고 제안합니다. 따라서 수정된 Cohen은 절단 점수를 생성할 때 criterion-referenced 데이터와 norm-referenced 데이터를 모두 결합한 혼합 방법입니다 [60]. 이 방법의 사용자는 모든 학생이 시험에 합격할 수 있고 시험 난이도에 따라 점수가 변경된다는 점에서 코헨 점수를 깎는 것이 시간 효율적이고 자원 집약적이지 않으며 학생들에게 공정하다고 생각한다. 그러나 Cohen 방법을 비판하는 사람들은 이 절단 점수가 원하는 criterion-참조가 아닌 norm-참조로 인식되는데, 이는 절단 점수를 생성하기 위해 실제 코호트 성능의 사전 결정되고 상대적으로 임의적인 비율에 의존하기 때문이다. Standard setting methods such as Angoff are resource intensive and time‐consuming. Faculty with small staff numbers and limited financial resources can struggle to collect a sufficient number of experts required for reliable and valid methods. The Cohen method is an alternative form of standard setting increasingly used in medical education where the ‘best performing’ students (student score at the 95th percentile or P95) are used as a reference point [10]. Medical educators determine what proportion of this high‐performing group score is acceptable as a cut score, e.g. 60% × P95. The modified Cohen takes this further proposing that historical data from multiple criterion‐referenced exams, within the programme, can personalise this Cohen sum to better reflect the pass mark expected by panels of experts. The modified Cohen is therefore a mixed method, combining both criterion‐referenced and norm‐referenced data in the creation of the cut score [60]. Users of the method think the Cohen cut score is time efficient and less resource intensive and fair to students in that all students can pass the exam and the cut‐score changes with the level of difficulty of the exam. Critics of the Cohen method, however, perceive this cut‐score to be norm‐referenced, rather than the desired criterion‐referenced, as it relies on a pre‐determined and relatively arbitrary proportion of the actual cohort performance to create the cut‐score. |
기준 참조 표준 설정 방법 선택
Selecting a Criterion‐referenced Standard Setting Method
미국교육연구협회 '교육 및 심리검사를 위한 표준'[61, 페이지 53]은 '모든 시험 또는 모든 목적에 대해 cut-score를 결정하는 유일한 방법은 있을 수 없으며, 어떤 단일한 절차도 방어성을 완전히 확립할 수는 없다'고 분명히 명시하고 있다. 이러한 노선을 따라 Angoff[61]는 '컷(cut) 점수 설정 문제와 관련하여, 서로 일치하는 결과를 산출하지 못할 뿐만 아니라 반복 적용 시에도 동일한 결과를 산출하지 못하는 몇 가지 판단 방법을 관찰했다'고 언급했다.
The American Educational Research Association ‘Standards for Educational and Psychological Testing’ [61, p. 53] clearly state that ‘there can be no single method for determining cut‐scores for all tests or for all purposes, nor can there be any single set of procedures for establishing their defensibility’. Along these lines, Angoff [61] also noted that ‘regarding the problem of setting cut‐scores, we have observed that the several judgemental methods not only fail to yield results that agree with one another, they even fail to yield the same results on repeated application’.
어떤 하나의 방법으로도 '최적' 절단 점수 값을 식별할 수 없음에도 불구하고, 후자는 항상 전문적인 판단에 포함되기 때문에, 의학 교육자가 표준 설정 접근방식을 선택할 때 고려하고자 하는 여러 요소가 있다. 다음은 이러한 요인에 대한 개요입니다.
Despite the fact that no single method can lead to the identification of an ‘optimal’ cut‐score value, as the latter is always embedded in professional judgement, there are nonetheless a number of factors that the medical educator might wish to consider when selecting a standard setting approach. An overview of these factors is presented next.
[명확한 표준 설정 프로세스를 준수하는 정도]가 cut-score에 가장 큰 영향을 미칩니다. 무슨 방법을 쓰든지, 표준 설정 과정에는 [표준 설정 연습 및 시험의 목표에 대한 명확한 정의, 잘못된 인식을 최소화하기 위한 패널리스트의 광범위한 교육, 그리고 최소한의 숙련도 또는 허용 가능한 성과를 구성하는 것이 무엇인지에 대한 명확한 개요]가 포함되어야 한다. 그러나 시험 목표와 시험 점수 사용자가 원하는 관련 결정을 고려하여 가장 적합한 표준 설정 방법을 선택하는 것은 여러 요인을 고려할 수 있다.
The extent to which a clear standard setting process is adhered to has the greatest impact on the cut‐score. This process, regardless of the method adopted, should include a clear definition of the objective of the examination as well as the standard setting exercise, extensive training of panellists to minimise any misconceptions, as well as a clear outline of what constitutes minimal proficiency or a borderline acceptable performance. However, a number of factors can be considered to select a standard setting method that might be most suitable given the intended aims of the examination and the associated decision that the test score user wishes to make.
첫 번째 질문 중 하나는 [시험 형식]이 어떻게 되는지이다.
- 지식 기반 검사(예: MCQ)의 경우 패널리스트가 완료해야 하는 과제를 감안할 때, 즉 실제 테스트 항목의 검토에 근거하여 컷(cut) 점수를 추정하는 것이 가장 적절하다.
- 반대로 OSCE 및 작업 공간 기반 작업과 같은 성능 평가의 경우 복잡한 다차원 성능 특성을 고려할 때 검사 중심 방법이 표준을 설정하기에 더 적합합니다. 후자는 일반적으로 성과에 대한 전체론적 판단을 수반한다.
One of the first questions to ask is what is the format of the examination?
- For knowledge‐based examinations (e.g. MCQs), test‐centred methods are most appropriate given the task that panellists are asked to complete, i.e. estimate a cut‐score based on a review of the actual test items.
- Conversely, for performance assessments, such as OSCEs and workplace‐based tasks, examineecentred methods are more suitable for setting a standard given the complex, multi‐dimensional nature of performance. The latter typically entail holistic judgements of performance.
둘째, 사용자는 시험 형식을 고려할 수도 있습니다. 예를 들어, 일부 표준 설정 방법(예: Nedelsky 방법)은 MCQ와 함께 사용하기 위해 개발되었습니다. 일부 방법은 서로 다른 형식(예: Angoff 방법)으로 사용할 수 있지만, 기대치를 충족할 수도 있고 충족하지 못할 수도 있는 특정 가정이 이루어진다. 예를 들어, Angoff 방법과 그 파생물offshoot들은 본질적으로 수행능력이 보상적compensatory이라고 가정한다. 즉, 응시자들은 다른 섹션에서 잘함으로써 시험의 특정 부분에서 잘 하지 못한 것을 보상할 수 있다. 따라서 이러한 방법들은 서로 다른 요소들이 성공적으로 독립적으로 완성되어야 하는 결합적 환경에서는 적절하지 않을 것이다. 다른 방법(Hofstee, 대조군)은 테스트 형식에 무관하도록test-format invariant 개발되었습니다.
Second, the user may also wish to consider the format of the examination. For example, some standard setting methods (e.g. the Nedelsky method) were developed exclusively for use with MCQs. While some methods can be used with different formats (e.g. Angoff methods), certain assumptions are made that may or may not meet expectations. For example, the Angoff method and its offshoots assume that performance is compensatory in nature, i.e. candidates can compensate for doing poorly in certain parts of the examination by doing well in other sections. These methods would therefore be inappropriate in a conjunctive setting, where different components need to be successfully and independently completed. Other methods (Hofstee, contrasting groups) were developed as test‐format invariant.
종종 공표되는 한 가지 잘못된 믿음은 표준을 설정할 때 [다수의 방법을 결합하면 '더 나은 컷 스코어'를 제공한다는 것]이다. 표준 설정과 삭감 점수 선택은 정보에 입각한 판단에서 도출되기는 하지만, 궁극적으로는 [정책 결정]이라는 점을 반복적으로 강조할 수 밖에 없다. 복수의 방법을 결합하면 '더 나은' 표준이 될 것이라는 증거는 거의 없다[57]. '올바른correct' cut-score가 없는데, 어떻게 여러 접근방식의 결과를 종합할 수 있는가? 또한 이 전략에는 훨씬 더 많은 리소스가 필요합니다. 몇 가지(부실하게) 구현된 접근법의 결과를 제공하기보다는 항상 하나의 표준 설정 방법을 체계적으로 구현하는 것이 더 낫다.
One erroneous belief that is often promulgated is the one that suggests that combining a multitude of methods when setting a standard will provide a ‘better cutscore’. It is important to reiterate that standard setting and the selection of a cut‐score are ultimately policy decisions, albeit derived from informed judgement. There is little evidence to suggest that combining multiple methods will lead to a ‘better’ standard [57]. Since there is no ‘correct’ cut‐score, how can policy makers synthesise results from multiple approaches? This strategy also requires significantly more resources. It is always better to systematically implement one standard setting method rather than provide results from several (poorly) implemented approaches.
다시 말하지만, [cut-score에 뒤따르는 프로세스]가 궁극적으로 방어해야 할 사항입니다. 후자는 기준 설정 연습의 [모든 단계를 적절히 문서화]하여, 패널리스트의 [선발과 훈련을 명확히 기술]하고, cut-score의 사용을 [뒷받침하는 경험적 증거]를 제공하는 것을 포함한다. 이러한 데이터에는 일반적으로 컷-점수 값에 대한 변동성 소스(판단, 패널 등)의 영향뿐만 아니라 컷-점수 구현 결과(예: 과거 추세에 비추어 합격/불합격률의 적절성)가 포함된다. 절단 점수 확인의 중요성은 다음 섹션에서 강조합니다(상자 24.9 참조).
Again, the process that is followed when arriving at a cut‐score is ultimately what needs to be defended. The latter includes properly documenting all phases of a standard setting exercise, clearly describing the selection and training of panellists, as well as providing empirical evidence to support the use of a cut‐score. These data typically include the impact of sources of variability (judges, panels, etc.) on the cut‐score value as well as the consequences of implementing a cut‐score (e.g. the appropriateness of pass/fail rates in light of historical trends). The importance of validating any cut‐score is underscored in the next section (see Box 24.9).
| 상자 24.9 방법: 표준 설정 방법 선택 BOX 24.9 HOW TO: Choose a standard setting method • 모든 표준 설정 방식은 '무엇이 역량을 구성하는가'에 대한 전문가의 내적 구조internal construction에 기초하기 때문에, (어떤 방식으로도) '최적optimal' 절단점수 값은 산출할 수 없다. • [프로세스가 체계적으로 구현되고 적절한 근거 출처로 뒷받침되는 것]이 어떤 표준 설정 방법을 선택하느냐보다 훨씬 더 중요하다. • 그러나 표준 설정 방법의 선택에는 (MCQ 대 성능 평가) 몇 가지 요소를 고려할 수 있다. • 몇 가지 방법을 결합해도 결국 여러 가지 고려사항에 기초한 정책 결정이기 때문에 '더 나은' 표준이 만들어지지는 않을 것이다. • No standard setting method can yield an ‘optimal’ cut‐score value as this is based on experts’ internal construction of what constitutes competence. • The extent to which a process is systematically implemented and supported with appropriate sources of evidence is much more important than the selection of any standard setting method. • However, several factors can be considered in the choice of a standard setting method, including the format of the examination (MCQ versus performance assessment). • Combining several methods will not yield a ‘better’ standard as the choice of any cut‐score is ultimately a policy decision based on a number of considerations. |
컷-점수를 지원하기 위한 유효성 증거 수집
Gathering Validity Evidence to Support a Cut‐score
어떤 표준 설정 방법을 채택하였든, [얻어진 표준을 검증하기 위한 증거를 수집하는 것]은 중요한 단계입니다 [62, 63]. 이 장에서 언급한 바와 같이, 모든 표준 설정 연습에서 궁극적으로 중요한 것은 프로세스가 체계적으로 준수되고 여러 증거 소스를 사용하여 방어될 수 있는 범위입니다.
Regardless of the standard setting method adopted, gathering evidence to validate the resulting standard is a critical step [62, 63]. As stated throughout this chapter, what is ultimately of importance with any standard setting exercise is the extent to which a process is systematically adhered to and can be defended using a number of evidential sources.
[절차적 타당성procedural validity을 뒷받침하는 근거]는 표준 설정 보고서에 명확히 기록될 필요가 있다. 이것은 일반적으로 모든 표준 설정 보고서의 첫 부분으로 구성되며, 다음을 포함하여 연습의 각 단계에 대한 철저한 설명을 수반한다.
The evidence to support procedural validity needs to be clearly documented in the standard setting report. This usually comprises the first part of any standard setting report and entails a thorough account of each step of the exercise including:
- • 대상 시험의 개요 및 목적
- • 근거 근거와 함께 구현된 선택된 표준 설정 방법에 대한 명확한 설명.
- • 전문가 심판단 선정 과정, 심사위원의 자격 설명, 전문직 전체를 대표하는 정도 설명
- • 훈련 과정, 성과 표준의 정의 및 데이터 수집 방법을 포함한 연습의 모든 단계에 대한 개요
• An overview of the targeted examination and its purpose.
• A clear articulation of the selected standard setting method implemented with a supporting rationale.
• The process used to select the panel of expert judges, as well as a description of their qualifications and the extent to which they represent the profession as a whole.
• An outline of all phases of the exercise, including the training process, definition of the performance standard, and how data were collected.
표준 설정 연습의 다양한 측면에 대한 조사 패널 목록은 절차적 타당성 증거를 뒷받침하는 마지막 중요한 부분을 구성합니다. 패널 리스트가 공정에서 얼마나 신뢰하며, 더 중요한 것은 컷-스코어 결과에서 얼마나 신뢰합니까? 훈련 단계에 대한 심판의 인상과 점수를 평가하는 것은 모든 표준 설정 연습에 대한 강력한 확인을 제공할 수 있다.
Surveying panellists on various aspects of the standard setting exercise constitutes a final important piece of supporting procedural validity evidence. How confident are the panellists in the process and, more importantly, in the resulting cut‐score? Evaluating judges’ impressions of the training phase as well as the cut‐score can provide strong confirmation for any standard setting exercise.
대부분의 기준 참조 검사의 높은 위험 특성을 고려할 때 cut-score의 내부 타당도를 뒷받침하는 증거도 매우 중요하다. 즉, 절단 점수의 추정은 얼마나 정확하며 관심 있는 모든 측면에서 얼마나 재현 가능합니까? 정밀도와 관련하여, 항목 응답 능력 지표와 관련된 항목 응답 능력 지표의 경우, 절단 점수와 관련된 숙련도 추정치의 (조건부) 표준 오차는 후자 값의 안정성을 직접적으로 나타낼 수 있다. 관측된 점수 척도(예: 숫자 , 오른쪽, 백분율 correct 정확 등)를 사용하여, 실무자는 복합 이항 모델을 사용하여 절단 점수와 관련된 오차의 양을 추정할 수도 있다[64].
Evidence to support the internal validity of the cut‐score is also of great importance given the high‐stakes nature of most criterion‐referenced examinations. That is, how precise is the estimate of the cut‐score and how reproducible is it across any facet of interest? With regard to precision, if the cut‐score is relatable to an item response theory ability metric, the (conditional) standard error of the proficiency estimate associated with a cut‐score can provide a straightforward indication of the stability of the latter value. With an observed score scale (e.g. number‐right, percentage‐correct, etc.), the practitioner can also estimate the amount of error associated with a cut‐score using a compound binomial model [64].
또한, 표준 설정에 참여하는 심판, 심판 패널(여러 그룹이 참여하는 경우), 선택한 항목/스테이션 등의 기능으로 절단 점수가 영향을 받는 정도는 [일반화가능도 이론]을 사용하여 쉽게 평가할 수 있다[8, 65]. 이 프레임워크를 통해 의료 교육자는 위에 열거된 측정 오류의 측면 또는 잠재적 원천에 기인할 수 있는 점수(컷☆스코어 포함)의 변동성을 추정할 수 있다. 이와 유사하게, IRT 기반 등급 척도 모델[66]은 또한 후보자의 능력 분포, 항목/역의 어려움 및 등급의 엄격성과 관련하여 유용한 정보를 제공할 수 있다. 내부 타당도 의 증거를 수집하기 위해 사용하는 모델의 복잡성에 관계없이, 이 중요한 정보의 출처는 절단 점수가 추정되는 안정성이나 정밀도에 대한 지표를 제공하는 데 있으며, 주로 오용을 최소화하기 위해 실무자에게 일부 경계를 제공하는 데 있다.
Additionally, the extent to which the cut‐score is impacted as a function of the judges participating in an exercise, the panel of judges (if multiple groups are involved), the items/stations selected, etc. can be readily assessed using generalisability theory [8, 65]. This framework allows the medical educator to estimate the amount of variability in scores (including the cut‐score) that can be ascribed to any facet or potential source of measurement error as listed above. Similarly, IRT‐based rating scale models [66] can also provide useful information with respect to the ability distribution of candidates, difficulty of items/stations, as well as stringency of raters. Regardless of the complexity of the models utilised to gather evidence of internal validity, the aim of this critical source of information is to provide an indication of the stability or precision with which a cut‐score is estimated, primarily to provide some boundaries to the practitioner in order to minimise its misuse.
[절단 점수의 외부 타당도external validity을 뒷받침하는 증거]도 표준 설정 노력의 일부가 되어야 한다. 이는 표준 구현의 영향과 직접 관련이 있기 때문이다. (과거의) 불합격률에 미치는 영향에 비추어 절단 점수의 합리성을 평가하는 것은 일반적으로 외부 검증 노력의 핵심이다. 예를 들어, 일반적으로 졸업 OSCE에서 한 학년의 10~12% 사이에서 불합격해왔다고 가정해보자. 표준 설정 연습에 따른 55%의 불합격률이 나왔다면, 코호트가 과거 그룹 및 유사한 난이도의 OSCE와 비교할 수 있는 능력을 가졌다고 가정할 때 컷(cut) 점수 및 그 적정성에 대한 상당한 정밀 조사를 보증할 것이다.
Evidence to support the external validity of a cut‐score should also be part of any standard setting effort as this relates directly to the impact of implementing a standard. Assessing the reasonableness of the cut‐score in light of its impact on failure rates is generally at the core of external validation efforts. For example, assume that a graduation OSCE has typically failed between 10 and 12% of a class. A failure rate of 55%, following a standard setting exercise, would warrant considerable scrutiny of the cut‐score and its appropriateness, assuming that the cohort is of comparable ability to past groups and the OSCE of a similar difficulty level.
(표준 설정의) 결과를 [다른 평가와 비교하는 것]은 제안된 모든 절단 점수에 대한 외부 타당도의 또 다른 중요한 원천을 구성한다. 예를 들어, 유사한 구조(예: 이전 OSCE)를 측정하는 다른 시험에서의 합격/불합격률 또는 학생 현황과 얼마나 비교가 됩니까? 두 번의 검사가 정확히 동일한 도메인 조합을 측정할 것이라고 기대하지는 않지만, 그럼에도 불구하고 대부분의 응시자들에게 동등한 지위를 줄 것입니다.
A comparison of results to other assessments constitutes another important source of external validity for any proposed cut‐score. For example, how comparable are pass/ fail rates to grades or the status of students on other examinations measuring similar constructs (e.g. a prior OSCE)? Though we would not expect two examinations to measure exactly the same combination of domains, they should nonetheless yield a comparable standing for most candidates.
결론
Conclusions
표준 설정은 학부 교육에서 의사 재검증 노력에 이르기까지 의료 교육의 모든 평가 활동에서 필수적인 부분입니다. 응시자가 시험의 기초가 되는 역량을 습득했는지 여부를 결정하는 것은 개별적인 판단뿐만 아니라 프로그램 효과성, 교육 효과성 등을 평가하는 데 사용되는 핵심 결과이다. [67, 68].
Standard setting is an intrinsic part of all assessment activities in medical education, from undergraduate training to physician revalidation efforts. Determining whether a candidate has mastered any number of competencies underlying an examination is a key outcome used not only to render individual judgements but also to evaluate programme effectiveness, teaching efficacy, etc. [67, 68].
무엇보다도, gold standard가 없으며, 모든 cut-score는 궁극적으로 ['역량'을 구성하는 수준]에 대해서 [내용전문가 집단이 내린 정보에 입각한 판단]을 반영한다는 점을 다시 한 번 강조해야 한다. 따라서 표준 설정 프로세스를 체계적으로 따르고 적절한 경험적 증거를 사용하여 이를 사용하는 것이 그러한 연습의 핵심이다.
First and foremost, it is important to reiterate that there is no gold standard and that all cut‐scores ultimately reflect informed judgement from a group of content experts on what level of performance constitutes ‘competency’. Systematically following a standard setting process and supporting its use with appropriate empirical evidence is therefore central to any such exercise.
시험에 대한 cut-score 결정에 어떤 방법을 사용하든, 표준 설정 연습을 수행하기 전에 몇 가지 문제를 해결해야 한다.
Irrespective of the method selected to arrive at a cutscore on an examination, several issues need to be addressed prior to undertaking a standard setting exercise.
첫째, 심사 위원단은 모든 시험 이해관계자의 축소판으로 보아야 하며, 따라서 지리적 영역, 의과대학 위치, 전문성, 성별 또는 민족성이 직업에 의해 중요하다고 간주되는 특성을 반영해야 한다. 그러한 광범위한 패널을 소집하는 것은 대부분의 전문직 종사자들의 견해가 실무에 통합되고 궁극적으로 표준이 되도록 보장할 것이다.
First, the panel of judges should be viewed as a microcosm of all exam stakeholders and as such should mirror any characteristic deemed important by the profession, be that geographical area, medical school location, specialty, gender, or ethnicity. Convening such a broad panel will ensure that views from most members of the profession are incorporated in the exercise, and ultimately, the standard.
모든 표준 설정 패널에 적합한 수의 패널 목록을 결정하는 것도 중요합니다. 너무 적은 수의 패널리스트를 초대하는 것은 바람직하지 않다. 한 명의 반대 심판의 판단이 최종 컷-점수의 가치에 과도한 영향을 미칠 수 있기 때문이다. 반면에 지나치게 대형 패널을 구성하는 것은 비용 효율적이지 않을 수 있습니다. 따라서 위에서 설명한 바와 같이 패널집단에게 원하는 특성을 명확하게 식별하면, 패널의 최적 크기를 결정하는 데 귀중한 정보를 제공할 수 있다.
Determining a suitable number of panellists for any standard setting panel is also critical. Inviting too few panellists is ill‐advised, as the judgements of a single dissenting judge could have an undue impact on the value of the final cut‐score. On the other hand, assembling a large panel may not be cost‐effective. Consequently, clearly identifying the desired characteristics of the group, as outlined above, can provide valuable information for determining the panel’s optimal size.
일단 cut-score가 설정되면, 정치적 또는 내용적 성격에 기반하여 직업에서 발생할 수 있는 모든 변화에 비추어 지속적인 적합성을 보장하기 위해 모든 검사의 컷(cut) 점수를 주기적으로 재검토하는 것도 중요하다. 마지막으로, 표준 설정 방법이 다르면 컷-점수 값이 달라진다는 점을 다시 언급하는 것이 중요합니다.
Once set, it is also important that the cut‐score for any examination be periodically revisited to ensure its continued appropriateness in light of any changes that may have occurred in the profession, whether political or content‐based in nature. Finally, it is important to restate that different standard setting methods will produce different cut‐score values.
모든 표준 설정 연습의 중심 목표는 다음과 같아야 한다.
- (i) 특정 방법의 선택을 방어한다.
- (ii) 연습 내내 따르는 모든 단계를 꼼꼼하게 문서화해야 한다.
- (iii) 기준의 선택은 가능한 한 많은 경험적 증거에 기초하며, 주어진 cut-score 채택의 결과뿐만 아니라, 전체적 인상을 고려한다
The central aim in any standard setting exercise should be to:
- (i) defend the choice of a particular method,
- (ii) meticulously document all steps followed throughout the exercise, and
- (iii) base the selection of the standard on as much empirical evidence as possible, factoring in global impressions as well as the consequences of adopting a given cut‐score.
'Articles (Medical Education) > 평가법 (Portfolio 등)' 카테고리의 다른 글
| 글로벌 평정척도가 체크리스트보다 전문성의 상승단계 측정에 더 나은가? (Med Teach, 2019) (0) | 2021.08.21 |
|---|---|
| 친구 다음에 OSCE를 볼 때의 이득: 후향적 연구(Med Teach, 2018) (0) | 2021.08.21 |
| 형성적 OSCE가 어떻게 학습을 유도하는가? 전공의 인식 분석 (Med Teach, 2017) (0) | 2021.08.19 |
| 원하는 것을 측정하기 위한 OSCE 개발을 위한 12가지 팁(Med Teach, 2017) (0) | 2021.08.19 |
| OSCE의 퀄리티 측정하기: 계량적 방법 검토 (AMEE Guide no. 49) (Med Teach) (0) | 2021.08.19 |