일반외과에서 NLP와 EPA에 대한 텍스트 피드백: 머신러닝 모델과 전공의 자율성(Am J Surg. 2021)
Natural language processing and entrustable professional activity text feedback in surgery: A machine learning model of resident autonomy
Christopher C. Stahl a, Sarah A. Jung a, Alexandra A. Rosser a, Aaron S. Kraut b, Benjamin H. Schnapp b, Mary Westergaard b, Azita G. Hamedani b, Rebecca M. Minter a, Jacob A. Greenberg a, *
소개
Introduction
외과 교육은 현장과 환자의 요구를 충족하기 위해 끊임없이 진화하고 있습니다. 외과 졸업생이 수련을 마친 후 독립적으로 수술할 수 있는 능력에 대한 우려로 인해 외과에서 역량 기반 교육이 추진되고 있습니다.1 역량 기반 교육과 관련된 근본적인 과제 중 하나는 역량 측정입니다. 레지던트가 언제 독립적으로 안전하게 수술할 준비가 되었는지 어떻게 알 수 있을까요?
Surgical education is constantly evolving to meet the needs of the field and its patients. There has been a push towards competency-based education in Surgery due to concerns about the ability of surgical graduates to operate independently upon completion of their training.1 One of the fundamental challenges involved in competency-based education is the measurement of competency: how do we know when a resident is ready to safely practice independently?
위임 가능한 전문 활동(EPA)은 의학전문대학원 교육에서 위임 결정을 정의하고 표준화하는 데 도움을 주기 위해 개발된 새로운 역량 기반 평가 프레임워크입니다. EPA는 특정 전문과목에 종사하는 의사의 필수 활동을 나타냅니다. 현재 일반외과에 대해 5개의 EPA가 존재하며, 레지던트가 EPA 평가를 완료할 때마다 교수진이 미세평가를 완료합니다. 미세 평가는 숫자 점수('관찰만'에서 '다른 사람 감독'에 이르는 0~4점)와 전문 활동에 대한 피드백을 제공하는 자유 텍스트 의견 옵션으로 구성됩니다.2 각 EPA는 해당 '위임 로드맵'과 함께 게시되며, 각기 다른 0~4 위임 수준에 해당하는 레지던트가 보여준 행동에 대한 서술형 텍스트 설명이 포함되어 있습니다. 이러한 위임 로드맵은 내러티브 코멘트 내에서 특정 행동에 대한 점수 할당 및 토론을 안내하기 위한 것입니다.
Entrustable Professional Activities (EPAs) are a novel competency-based assessment framework developed to help define and standardize entrustment decisions in graduate medical education. EPAs represent the essential activities of a practicing physician in a given specialty. Five EPAs currently exist for general surgery, and each time a resident completes an EPA evaluation, faculty complete a microassessment. The microassessment consists of a numeric score (0–4, ranging from “observation only” to “supervising others”) and an option for free text comments giving feedback on the professional activity.2 Each EPA is published with a corresponding ‘entrustment roadmap’, a narrative text description of the behaviors demonstrated by the resident that correspond to the different 0–4 entrustment levels. These entrustment roadmaps are meant to guide score assignment and discussion of specific behaviors within the narrative comments.
이러한 위임 로드맵은 ABS, APDS, RRC 및 RAS의 대표로 구성된 전문가 위원회에서 신중하게 작성되었습니다.2 그러나 당시에는 실제로 외과의사 교육자들이 각 EPA 위임 수준에 대해 대표적인 행동으로 간주하는 것이 무엇인지에 대한 데이터가 거의 없었습니다. 각 위임 수준과 관련된 실제 EPA 의견에 대한 심층 분석은 "현장에 있는" 외과 교수진이 레지던트 위임에 대해 중요하게 생각하는 것이 무엇인지에 대한 중요한 통찰력을 제공할 수 있습니다. 또한 이 데이터는 일상적인 관행을 더 잘 반영하기 위해 EPA 위임 로드맵을 반복적으로 수정하는 데 사용될 수 있습니다.
These entrustment maps were carefully written by an expert committee with representation from the ABS, APDS, RRC, and RAS.2 However, at that time there was very little data on what surgeon educators out in practice considered representative behaviors for each EPA entrustment level. An in-depth analysis of real-world EPA comments associated with each given entrustment level can offer important insight into what “boots on the ground” surgical faculty consider important for resident entrustment. Additionally, this data could be used to iteratively revise the EPA entrustment roadmaps to better reflect daily practice.
이 연구는 자연어 처리(NLP)의 힘을 활용하여 이러한 분석을 수행합니다. 잠재 디리클레 할당(LDA) 주제 모델링을 사용하여 EPA 내러티브 피드백 내에서 잠재 주제를 식별했습니다. 이러한 코멘트 내에서 위임 가능한 전문 활동(EPA) 프레임워크에 정의된 다양한 위임 수준에 일관되게 매핑되는 주제를 식별하는 LDA 알고리즘의 능력을 평가했습니다. 그런 다음 식별된 주제를 검토하여 컴퓨터로 생성된 이러한 주제를 위임 수준에 매핑하는 것이 인간 평가자가 이해할 수 있는지 여부를 결정했습니다.
This study harnesses the power of natural language processing (NLP) to perform such an analysis. Latent Dirichlet allocation (LDA) topic modeling was used to identify latent topics within EPA narrative feedback. We assessed the ability of the LDA algorithm to identify topics within these comments that consistently mapped to different entrustment levels as defined within the Entrustable Professional Activities (EPA) framework. We then reviewed the identified topics to determine if the mapping of these computer-generated topics to entrustment levels was comprehensible to human raters.
자료 및 방법
Material and methods
EPA 데이터
EPA data
우리 기관은 외과 교육에서 위임 가능한 전문 활동(EPA)에 대한 미국 외과학회(ABS)의 전국적 파일럿 시험에 참여하고 있습니다. 앞서 설명한 바와 같이, EPA 평가에 대한 우리의 실행 전략에는 레지던트와 교수진이 위임 점수("관찰만"에서 "다른 사람 감독"에 이르는 0~4점)와 레지던트의 성과에 대한 자유 텍스트 의견을 모두 포함하는 EPA 평가를 제출할 수 있는 휴대폰 애플리케이션이 포함됩니다.3 평가는 2018년 7월부터 2020년 1월까지 현재 시범 시험 중인 5개 일반외과 EPA(일반 외과 상담, 외상, 담낭 질환, 우하단부 통증, 사타구니 탈장)에 대해 수집했습니다. 레지던트에 대한 교수진의 평가만 분석에 포함되었습니다. 이 실행 전략의 독특한 특징은 외과 및 응급의학과 교수진이 레지던트에 대한 교수 평가를 수행하는 등 여러 부서의 협업을 통해 이루어졌다는 점입니다. 이 두 교수진 그룹이 수행한 평가는 모두 분석에 포함되었습니다.
Our institution is participating in the national American Board of Surgery (ABS) pilot trial of Entrustable Professional Activities (EPAs) in surgical education. As previously described, our implementation strategy for EPA assessment involves a mobile phone application to which residents and faculty can submit EPA assessments containing both an entrustment score (0–4, ranging from “observation only” to “supervising others”) and free text comments on the resident’s performance.3 Assessments were collected for the five general surgery EPAs currently in the pilot trial (General Surgical Consultation, Trauma, Gallbladder Disease, Right Lower Quadrant Pain, Inguinal Hernia) from July 2018 to January 2020. Only faculty assessments of residents were included in the analysis. A unique feature of our implementation strategy is multi-departmental collaboration, with faculty evaluations of residents performed by both Surgery and Emergency Medicine faculty. Assessments performed by both of these faculty groups were included in the analysis.
토픽 모델링
Topic modeling
자연어 처리(NLP)는 자연어 데이터와 상호 작용하기 위해 컴퓨터를 활용하는 것을 포함합니다. 토픽 모델링은 텍스트 데이터의 말뭉치(본문) 내에 존재하는 토픽을 발견하기 위해 고안된 NLP의 하위 집합입니다. 좀 더 기술적인 수준에서는 텍스트에서 용어(단어) 발생 빈도에 대한 확률적 프레임워크를 제공하는 생성 통계 모델입니다.4 NLP 및 기계 학습 분야의 상당한 발전에도 불구하고, 대부분의 텍스트 컴퓨터 분석은 여전히 단어장 모델을 사용하여 데이터와 상호 작용하고 있다는 점에 유의하세요. 향후에는 컴퓨터가 '개념 가방' 또는 '서술 가방'과 같이 인간에게 더 친숙한 방식으로 텍스트와 상호 작용할 수 있게 되겠지만, 현재는 '단어 가방' 모델이 우세합니다.5 즉, 이러한 방법을 사용하여 생성된 주제는 주어진 주제에 속할 가능성(단어 분포)에 따라 정렬된 단어 목록이며 여전히 사람의 해석이 필요합니다.6
Natural language processing (NLP) involves the utilization of computers to interact with natural language data. Topic modeling is a subset of NLP designed to uncover topics present within a corpus (body) of text data. On a more technical level, these are generative statistical models that provide a probabilistic framework for the frequency of term (word) occurrence in text.4 Of note, despite significant advances in the fields of NLP and machine learning, most computational analyses of text still interact with data using a bag-of-words model. Future developments may allow computers to interact with text in a more humanly familiar way, such as a ‘bag-of-concepts’ or ‘bag-of-narratives’, but currently bag-of-words models predominate.5 This means that the topics generated using these methods are lists of words ordered by likelihood of belonging to a given topic (a distribution over words) and still require human interpretation.6
잠재 디리클레 할당
Latent Dirichlet Allocation
잠재 디리클레 할당(LDA)은 토픽 모델링에 사용되는 일반적인 접근 방식입니다. LDA는 문서에 존재하는 단어를 토픽으로 할당하기 위해 디리클레 분포를 사용하여 텍스트 말뭉치에서 숨겨진(잠재) 토픽을 식별하는 데 사용되는 생성적, 확률적, 베이지안, 비지도 머신 러닝 알고리즘입니다.4,7 할당 과정을 간단히 살펴보면 다음과 같습니다.
- 알고리즘은 데이터 코퍼스의 모든 단어를 k개의 토픽 중 하나에 무작위로 할당합니다(토픽 수[k]는 사용자가 미리 지정함).
- 그런 다음 알고리즘은 단일 단어에 대한 토픽을 "버린"다음 다른 모든 단어의 분포를 기반으로 해당 단어가 할당될 가능성이 가장 높은 토픽을 다시 계산합니다.
- 그런 다음 해당 단어를 가장 가능성이 높은 토픽에 다시 할당하고 말뭉치의 모든 단어를 다시 할당할 때까지 다음 단어에 대해 이 과정을 반복합니다.
- 이 프로세스는 단어가 새로운 주제에 지속적으로 할당되는 것을 멈출 때까지(즉, 추정치가 안정 상태에 도달할 때까지) 수천 번 반복됩니다.
Latent Dirichlet Allocation (LDA) is a common approach used for topic modeling. LDA is a generative, probabilistic, Bayesian, unsupervised machine learning algorithm used to identify hidden (latent) topics in text corpora using a Dirichlet distribution to allocate the words present in documents into topics.4,7 A simplified view of the allocation process is as follows:
- the algorithm randomly assigns every word in the corpus of data to one of k topics (the number of topics [k] is pre-specified by the user).
- The algorithm then “throws out” the topic for a single word and re-calculates the topic to which that word is most likely to be assigned based on the distribution of all other words.
- It then reassigns that word to its most likely topic and repeats the process for the next word until it has reassigned all words in the corpus.
- This process is repeated thousands of times, until the words stop consistently getting reassigned to new topics (i.e., the estimates have reached a steady state).
해석
Interpretation
LDA 프로세스가 완료되면 문서-토픽 확률(감마)과 단어-토픽 확률(베타)을 생성합니다.8
- LDA는 각 문서를 토픽의 혼합으로 모델링하며, 각 문서-토픽 쌍에는 해당 토픽으로 구성된 문서의 비율을 나타내는 감마가 있습니다. 감마는 확률처럼 보고되며, 값이 1이면 해당 문서의 100%가 해당 토픽으로 구성되어 있음을 의미하고 0이면 0%를 나타냅니다.
- 각 토픽은 단어의 분포로 구성되며, 각 단어에는 단어-토픽 확률(베타)이 있으며 베타가 높을수록 해당 단어가 해당 토픽에 포함될 가능성이 높습니다. 각 단어는 다양한 확률로 여러 토픽에 나타날 수 있습니다. LDA를 사용하여 식별된 토픽은 베타 값이 감소하는 순서대로 정렬된 단어 가방입니다.
이러한 용어에 대한 요약은 표 1에서 확인할 수 있습니다.
After the LDA process is complete, it generates document-topic probabilities (gamma), and word-topic probabilities (beta).8
- LDA models each document as a mixture of topics—each document-topic pair has a gamma that represents proportion of the document made up of that topic. Gamma is reported like a probability, with a value of 1 meaning that 100% of that document is made up of the given topic, and a value of zero indicating 0%.
- Each topic consists of a distribution of words—each word has a word-topic probability (beta), with a higher beta representing a higher likelihood of that word being present in the corresponding topic. Each word may appear in multiple topics, albeit with varying probability. The topics identified using LDA are bags-of-words ordered by decreasing beta values.
A summary of these terms can be found in Table 1.

분석
Analysis
LDA 분석을 위해 EPA 코멘트는 축약어와 특수 문자를 제거하여 정리한 다음 R의 tm 패키지를 사용하여 개별 단어로 토큰화했습니다.9 정지어("the", "and" 등과 같이 일반적으로 의미가 거의 없는 영어에서 일반적으로 사용되는 단어)는 세 글자 미만의 모든 단어와 함께 제거되었습니다. 중복된 단어는 제거되지 않았습니다. 위임 수준이 0인 평가는 빈도가 낮아 제거되었습니다(1015개 중 n = 8개). 토픽모델 패키지는 데이터의 EPA 위임 수준("1", "2", "3", "4")과 일치하도록 k 토픽을 4로 설정한 표준 변형 기대 최대화(VEM) 알고리즘을 사용하여 LDA 분석을 수행하는 데 사용되었습니다.4 문서별 토픽 분포에 대한 디리클레 선행의 매개변수인 알파는 토픽모델 패키지 기본값인 50/k에 따라 시작값이 할당되었습니다. 이 분석은 '유니그램'(단일 단어) 항목을 사용하여 수행되었습니다. '준비되지 않음' 또는 '유능하지 않음'과 같은 부정적 수식어의 영향을 포착하기 위해 유니그램 + 빅그램(두 단어 항목) 결합 분석을 사용하여 분석을 반복했습니다. 빅그램의 추가는 결과에 큰 영향을 미치지 않았으며 단순화를 위해 이 원고에서는 생략했습니다. 문서-토픽 확률(감마)을 사용하여 LDA에서 생성된 토픽과 EPA 위임 수준의 매핑을 분석했습니다. 이 분석은 각 개별 EPA(외상, 일반 외과 상담 등)에 대해 반복되었습니다.
EPA comments were cleaned for LDA analysis by removing contractions and special characters and then tokenized into individual words using the tm package in R.9 Stop words (commonly used words in the English language that typically provide little meaning such as “the”, “and”, etc.) were removed, along with any words less than three letters long. Duplicate words were not removed. Assessments with an entrustment level of 0 were removed due to low frequency (n = 8 out of 1015). The topicmodels package was used to perform the LDA analysis using the standard variational expectation-maximization (VEM) algorithm with k topics set at 4 to match the number of EPA entrustment levels (“1”, “2”, “3”, “4”) in the data.4 Alpha, the parameter of the Dirichlet prior for the per-document topic distribution, was assigned a starting value per the topicmodels package default of 50/k. This analysis was performed using ‘unigram’ (single word) items. The analysis was repeated using a combined unigram + bigram (two word item) analysis to help capture the impact of negative modifiers such as ‘not ready’ or ‘not competent’. The addition of bigrams did not significantly impact the results and were omitted from this manuscript for simplicity. The mapping of LDA-generated topics to EPA entrustment levels was analyzed using document-topic probabilities (gammas). This analysis was repeated for each individual EPA (Trauma, General Surgical Consultation, etc.).
각 주제와 연관된 상위 10개 단어(단어-주제 확률[베타]를 사용하여 계산)를 수동으로 검토하여 주제가 위임 수준과 일관되게 일치하는지 확인했습니다. 한 명의 외과 레지던트가 위임 수준에 따라 다르며 자율성과 연관된 단어를 식별했습니다. 이러한 단어는 위임 수준에 따라 색상이 지정된 상자(낮음=빨간색, 중간=노란색, 높음=초록색)를 사용하여 수동으로 강조 표시한 다음 다른 저자 4명(외과의사 및 교육 과학자)이 이 과제를 검토했습니다. 이 수동 검토는 체계적이지 않고 비구조적이라는 점에 유의하는 것이 중요합니다. 토픽 모델링으로 생성된 토픽을 해석하는 한 가지 방법은 없으며, 토픽 모델링을 시도하는 모든 그룹은 특정 프로젝트의 요구 사항에 적합한 방법을 선택하는 것이 좋습니다. 이 수동 검토는 컴퓨터로 생성된 주제가 사람이 이해할 수 있는지 신속하게 확인하는 방법으로, EPA 평가 수준을 그룹으로 완벽하게 분류했지만 해석 가능한 패턴이나 내러티브를 제공하지 못하는 주제는 실제 유용성이 제한될 수 있습니다.
The top ten words associated with each topic (calculated using word-topic probabilities [betas]) were manually reviewed to determine if the topics coherently corresponded to the entrustment levels. A single surgery resident identified words that differed between entrustment levels and were associated with autonomy. These words were manually highlighted using boxes colored according to the level of entrustment they appeared to represent (low = red, intermediate = yellow, high = green) and then these assignments were reviewed by 4 other authors (surgeons and education scientists). It is important to note that this manual review was unstructured, and not systematic. There is no one way to interpret the topics created by topic modeling, and we recommend that any group attempting to do so select a method well suited to the needs of their specific project. This manual review was a way to quickly check that the computer-generated topics were understandable by humans—topics that perfectly sorted EPA assessment levels into groups but failed to provide any interpretable pattern or narrative would have limited real-world utility.
이 프로젝트는 기관 보건 과학 IRB의 검토를 거쳐 공식적인 검토가 면제된 것으로 인증되었습니다. 사전 동의는 면제되었습니다. 모든 데이터 분석 및 시각화는 R 3.6.1(오스트리아 비엔나, 통계 컴퓨팅을 위한 R 재단)을 사용하여 수행되었습니다.
This project was reviewed by the institutional Health Sciences IRB and certified as exempt from formal review. Informed consent was waived. All data analysis and visualizations were performed using R 3.6.1 (R Foundation for Statistical Computing, Vienna, Austria).
결과
Results
LDA-EPA 상관관계
LDA-EPA correlation
2018년 7월부터 2020년 1월까지 1015개의 교수진 EPA 평가가 수집되었으며, 이 중 97%는 자유 텍스트 코멘트와 연관되어 있었습니다. 이러한 코멘트는 32,215개의 단어로 구성되었습니다. 중지 단어, 길이가 3글자 미만인 단어, 레벨 0 평가를 제거한 후 13,364개의 단어가 남았습니다. 단어는 모든 EPA에 고르게 분포되어 있었으며, 각 EPA에는 최소 1831개의 단어가 포함되어 있었습니다.
1015 faculty EPA assessments were collected between July 2018 and January 2020; 97% of these assessments were associated with free text comments. These comments consisted of 32,215 words. After removal of stop words, words less than three letters in length, and level 0 assessments, 13,364 words remained. Words were well distributed across all EPAs, with each EPA containing at least 1831 words.
5개의 EPA를 모두 단일 그룹으로 분석했을 때, LDA 알고리즘은 1:1로 매핑되는 토픽을 EPA 위임 수준 1-4에 식별할 수 있었습니다(모든 감마 >0.99)(그림 1). 안타깝게도 이러한 주제는 수준 간 위임의 차이보다는, 각 위임 수준에 일반적으로 할당되는 서로 다른 EPA를 정성적으로 반영했습니다. 따라서 더 의미 있는 토픽이 생성되는지 확인하기 위해 개별 EPA에 대해 개별적으로 LDA 분석을 반복했습니다. 그 결과, 위임 수준 간의 매우 효과적인 구분이 개별 EPA 수준에서 재현되었고(모든 감마 >0.99), 더 이해하기 쉬운 토픽이 생성되었습니다(그림 2, 그림 3, 그림 4, 그림 5, 그림 6).
When all 5 EPAs were analyzed together as a single group, the LDA algorithm was able to identify topics that mapped 1:1 onto EPA entrustment levels 1–4 (all gammas >0.99) (Fig. 1). Unfortunately, these topics qualitatively reflected the different EPAs commonly assigned to each entrustment level, rather than differences in entrustment between levels. Therefore, the LDA analysis was repeated for each EPA individually to see if more meaningful topics would be generated. The highly effective discrimination between entrustment levels was replicated at the individual EPAs level (all gammas >0.99), and more comprehensible topics were generated (Fig. 2, Fig. 3, Fig. 4, Fig. 5, Fig. 6).
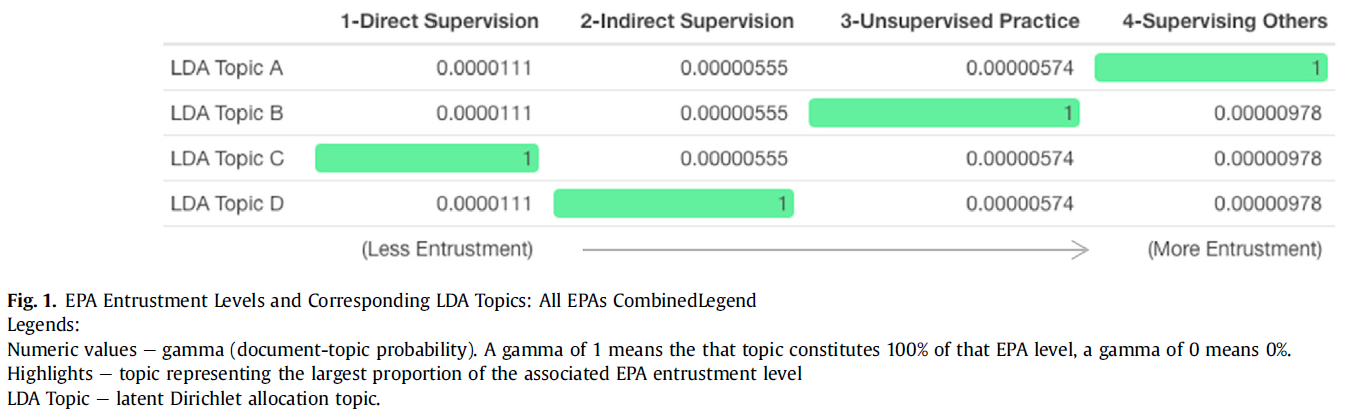
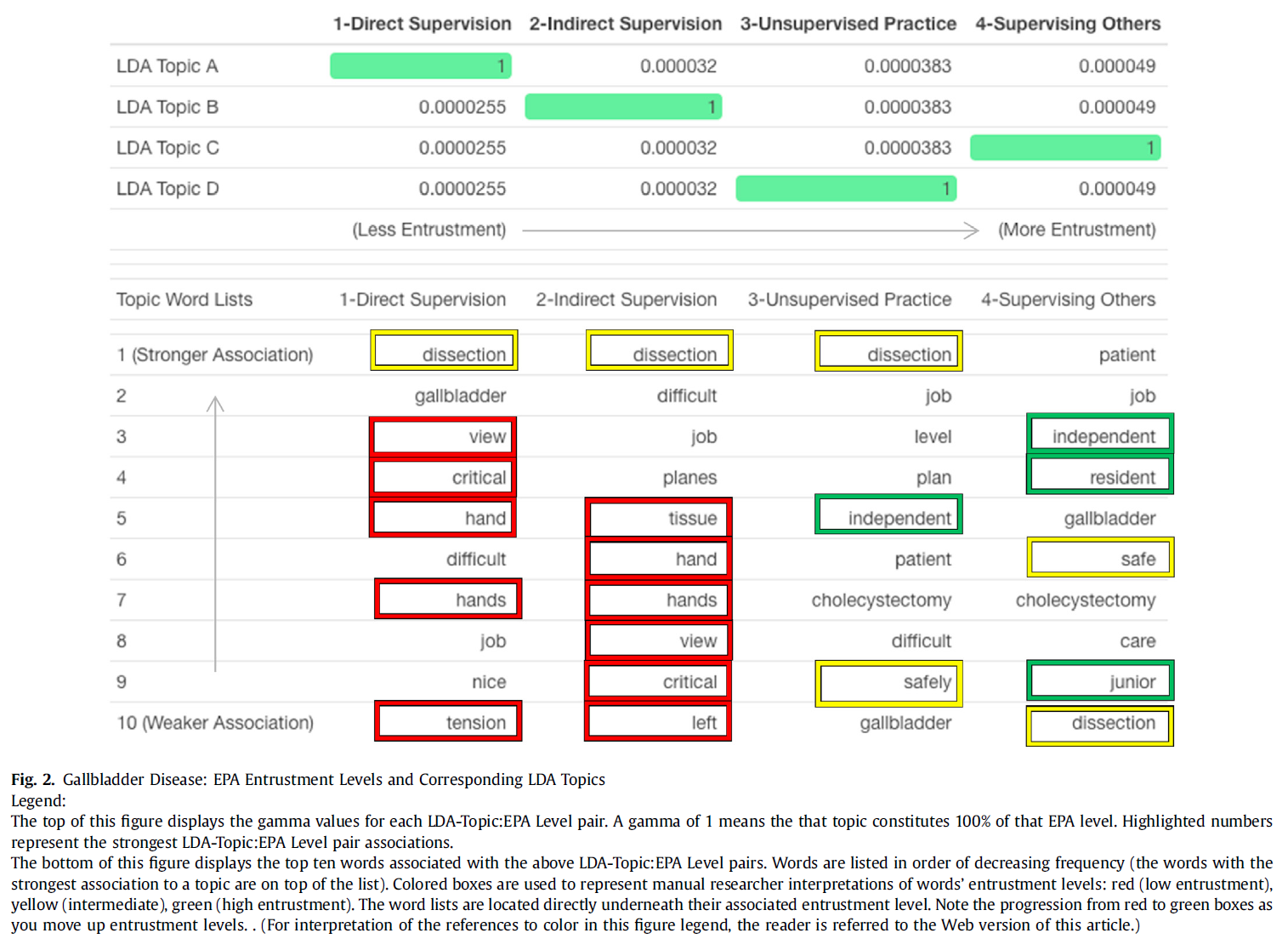
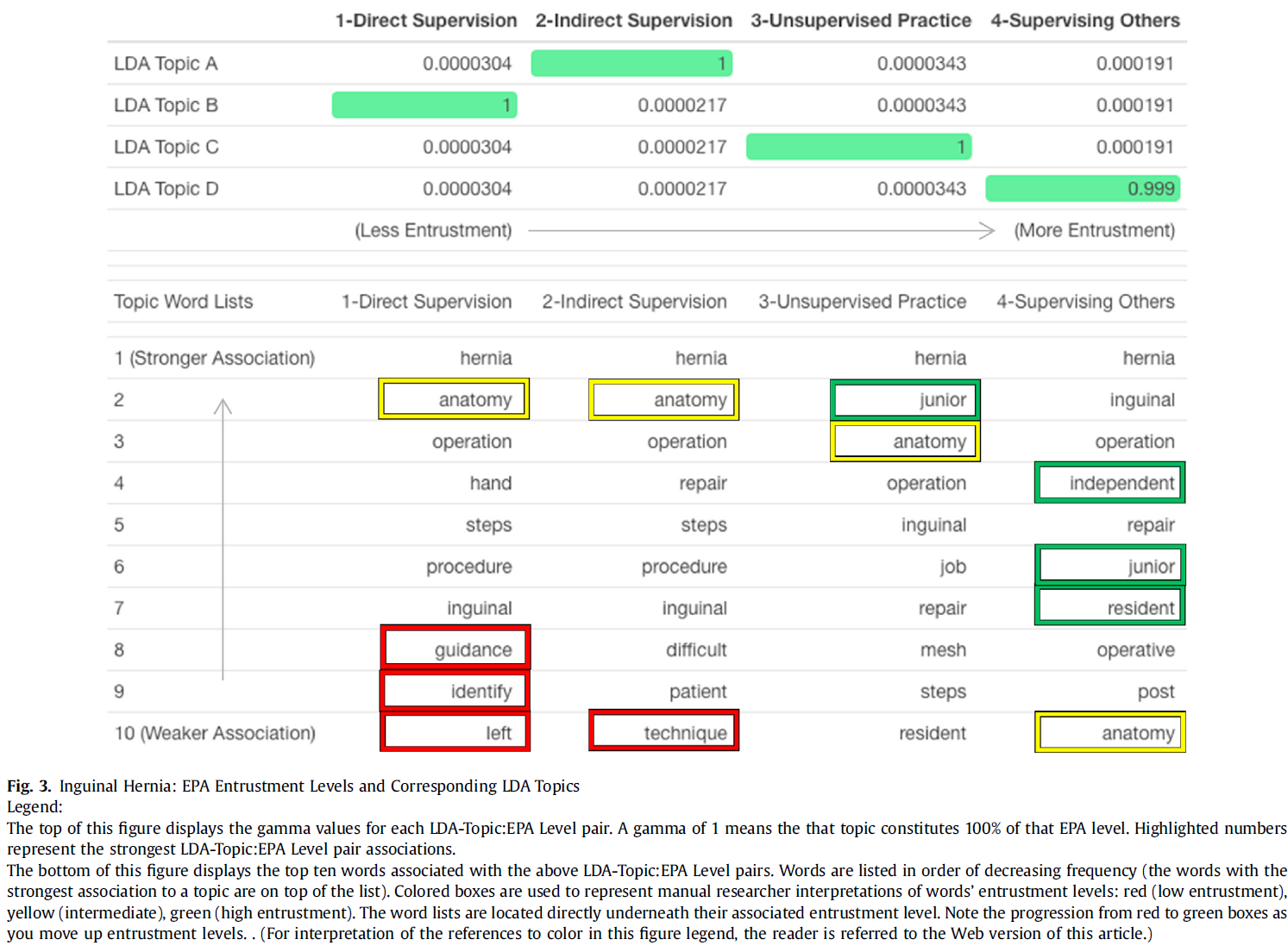
주제 해석
Topic interpretation
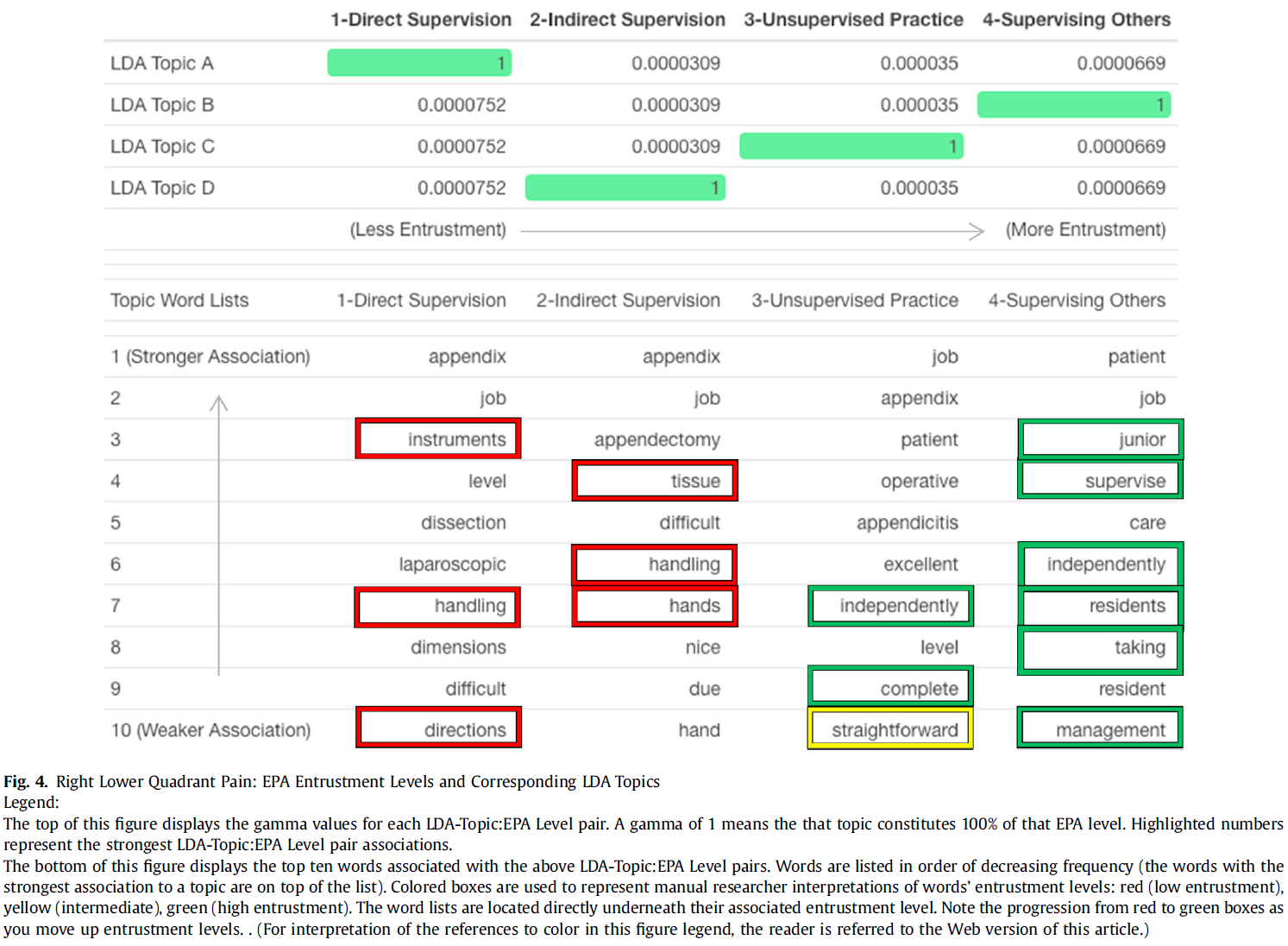
개별 EPA에 대해 발견된 주제는 해당 위임 수준 아래에 표시됩니다(그림 2, 그림 3, 그림 4, 그림 5, 그림 6). 예시 단어는 한 명의 검토자가 위임 수준에 따라 색상이 지정된 상자를 사용하여 수동으로 강조 표시했습니다(낮음 = 빨간색, 중간 = 노란색, 높음 = 녹색). 조사된 모든 개별 EPA에서 낮은 위임 단어에서 높은 위임 단어로 논리적인 추세가 있는 것으로 보입니다(그림 2, 그림 3, 그림 4, 그림 5, 그림 6). 예를 들어, RLQ 통증 EPA(그림 4)의 경우,
- 위임 수준 1과 2는 충수절제술의 기술적 측면("기구", "손/손/취급", [따라] "지시")을 배우는 것을 설명하는 것으로 보이는 반면,
- 위임 수준 3과 4는 독립적으로 사례를 완료하는 것, 종종 후배 전공의를 감독하면서("독립적으로", "완료", "감독", "취하다", "후배", "레지던트", "관리") 설명하는 것처럼 보였습니다.
흥미롭게도 레벨 3은 사례의 기술적 난이도("간단함")를 명확히 하는 것으로 보이며, 이는 레벨 3과 4 수행 간의 중요한 차이를 강조할 수 있습니다.
The topics uncovered for individual EPAs are shown underneath the corresponding entrustment levels (Fig. 2, Fig. 3, Fig. 4, Fig. 5, Fig. 6). Illustrative words were manually highlighted by a single reviewer using boxes colored according to the level of entrustment they appeared to represent (low = red, intermediate = yellow, high = green). There appears to be a logical trend from low entrustment words to higher ones for all of the individual EPAs examined (Fig. 2, Fig. 3, Fig. 4, Fig. 5, Fig. 6). For example, for the RLQ Pain EPA (Fig. 4) entrustment levels 1 and 2 seem to describe learning technical aspects of an appendectomy (“instruments”, “hand/hands/handling”, [following] “directions”), while levels 3 and 4 seem to describe independently completing cases, often while supervising junior residents (“independently”, “complete”, “supervise”, “taking”, “junior”, “residents”, “management”). Interestingly, level 3 appears to clarify the technical difficulty of the case (“straightforward”), which may highlight a critical difference between level 3 and 4 performance.
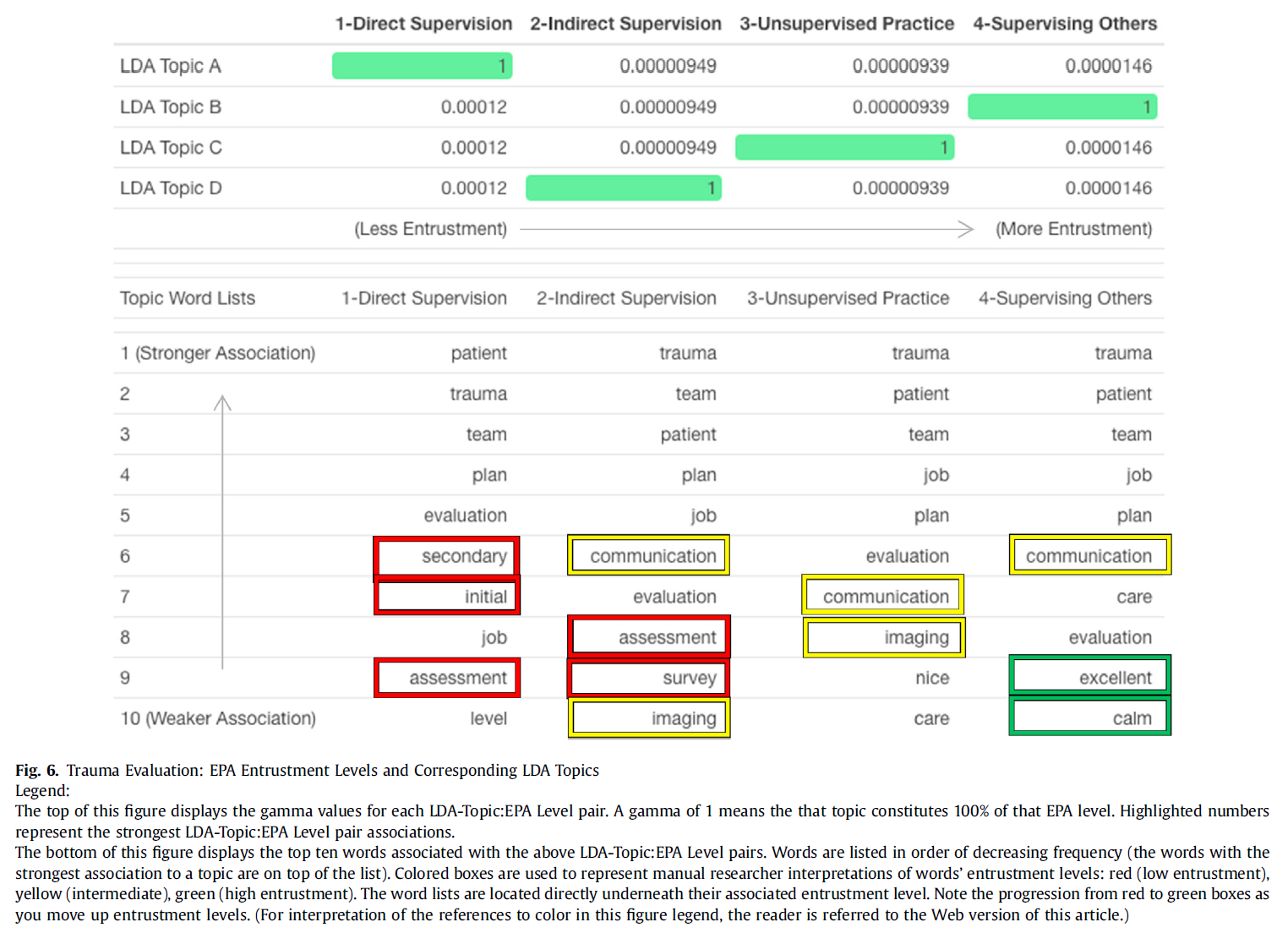
마찬가지로, 외상 EPA 수행에 있어 위임의 경로는
- 기본 평가("초기", "평가", "2차", "조사")를 학습하는 것부터
- 효과적으로 의사소통하고 적절한 후속 연구를 지시하는 것("의사소통", "영상"),
- 마지막으로 이전의 모든 기술을 효과적으로 수행하고 외상 베이를 관리하는 것("우수", "침착")으로 추적할 수 있습니다(그림 6).
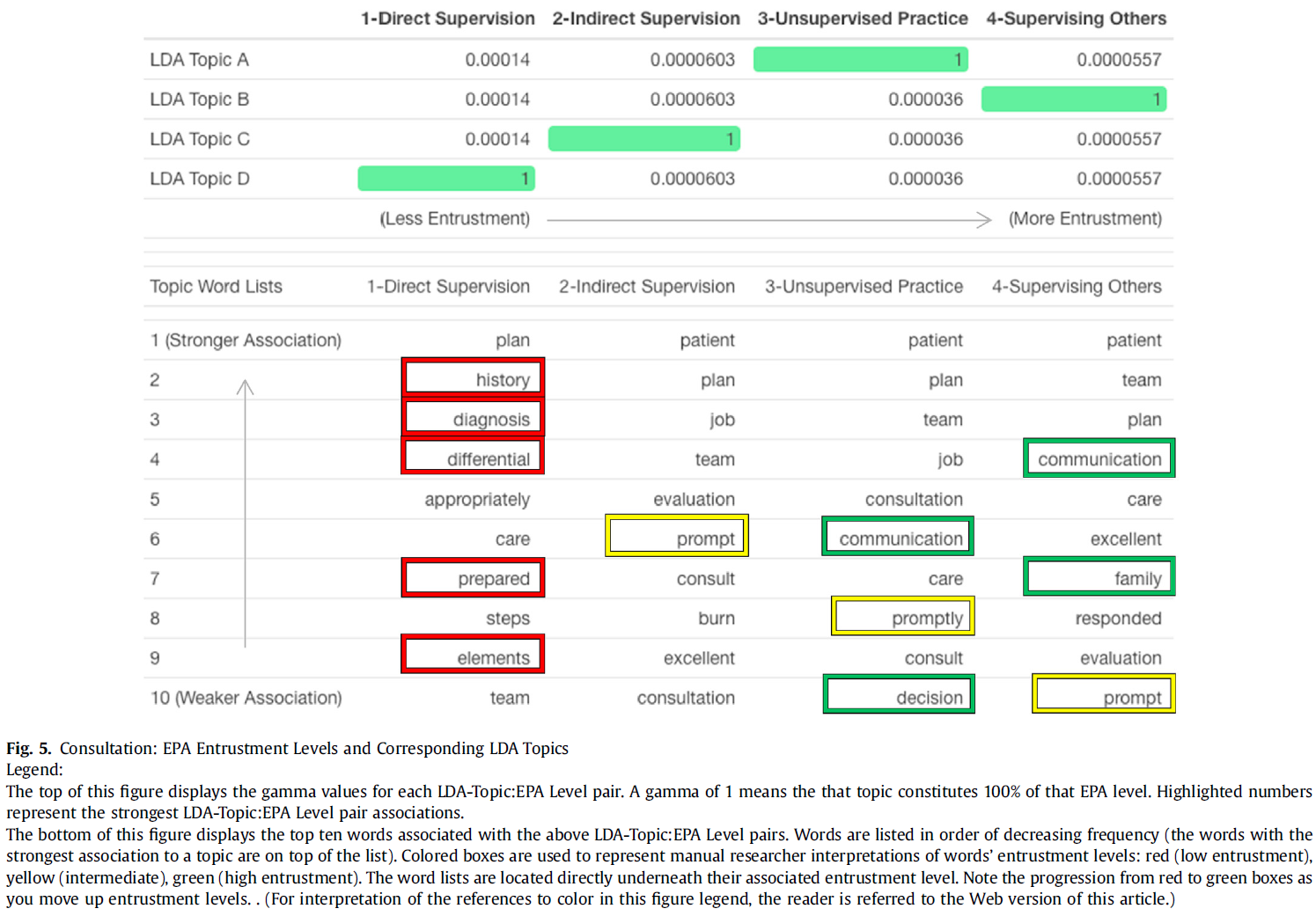
평가된 나머지 세 개의 EPA에서도 유사한 일관된 경향을 발견할 수 있습니다(그림 2, 그림 3, 그림 5).
Similarly, the path to entrustment in the performance of Trauma EPAs may be traced
- from learning the fundamental evaluation (“initial”, “assessment”, “secondary”, survey”)
- to communicating effectively and ordering appropriate follow up studies (“communication”, “imaging”),
- to finally performing all of the previous skills effectively and managing the trauma bay (“excellent”, “calm”) (Fig. 6).
Similar coherent trends can be found in the remaining three EPAs evaluated (Fig. 2, Fig. 3, Fig. 5).
토론
Discussion
LDA는 다양한 EPA 위임 수준과 관련된 텍스트 피드백의 고유한 패턴을 식별할 수 있습니다. LDA를 사용하여 생성된 토픽은 EPA 위임 수준에 합리적으로 매핑됩니다. 이는 실제 적용 가능성도 있는 중요한 개념 증명입니다. 첫째, 수술 교육에 EPA를 구현하는 것은 진화하는 과정입니다. 각 위임 로드맵에 명시된 현재 행동은 외과 교육 전문가들이 전문가 의견을 바탕으로 작성하고 개선한 것입니다.2 전문가 의견은 항상 유용한 출발점이지만, 이 연구에서 확인된 EPA 위임 수준-LDA 주제 쌍은 구현된 EPA 시스템 내에서 일하는 광범위한 교육자 풀로부터 실제로 각 위임 수준을 차별화하는 요소에 대한 데이터를 제공합니다. 이는 교육생의 자율성/위임과 의미 있는 상관관계가 있는 행동에 대한 중요한 통찰력을 제공하며, 데이터에 기반하여 기존 위임 설명을 수정하고 정보에 기반한 향후 위임 로드맵을 작성할 수 있게 해줍니다.
LDA is capable of identifying unique patterns of text feedback associated with different EPA entrustment levels. Topics generated using LDA map sensibly to EPA entrustment levels. This is an important proof-of-concept that also has practical applicability. First, the implementation of EPAs into surgical education is an evolving process. The current behaviors ascribed to each entrustment roadmap were created and refined by experts in surgical education based on their expert opinion.2 While expert opinion is always a useful starting point, the EPA entrustment level—LDA topic pairs identified in this study provide data from a broad pool of educators working within an implemented EPA system on what actually differentiates the distinct entrustment levels. This provides important insight into what behaviors meaningfully correlate with trainee autonomy/entrustment and will allow for a data-driven revision of the existing entrustment descriptions and informed creation of future entrustment roadmaps.
더 넓은 범위에서 이 원고는 외과 교육에서 NLP 전략의 잠재적 유용성을 보여줍니다. 놀랍지 않게도 외과 교육자들은 서로 다른 EPA 위임 수준에서 레지던트 성과에 대해 설명할 때 서로 다른 어휘와 구조를 사용합니다. 중요한 것은 LDA가 이러한 중요한 차이점을 포착하고 평가자가 해석할 수 있는 방식으로 위임 수준의 주요 차별화 측면을 강조할 수 있었다는 점입니다. 이는 자연어 처리 기술을 외과 교육에 광범위하게 통합하는 데 있어 유망한 첫 단계입니다. 레지던트 성과에 대한 대량의 텍스트 기반 데이터를 통합하는 평가 프레임워크가 개발됨에 따라 이러한 데이터를 대규모로 해석할 수 있는 전략이 필요합니다. NLP는 데이터를 통해 외과 교육을 확장하는 데 도움이 될 수 있습니다. 예를 들어, 추출 기반의 자동화된 문서 요약은 레지던트에게 제공되는 내러티브 피드백 코퍼스 내에서 가장 중요한 코멘트를 강조 표시할 수 있어 CCC 위원회를 통해 신속하게 검토할 수 있습니다.10,11 감독형 LDA(sLDA)와 같은 예측 모델링 기법은 평가를 그룹으로 분류하는 데 가장 능숙한 주제 대신 응답(점수)을 예측하는 잠재 주제를 식별하는 것을 목표로 관련 응답이 포함된 텍스트 평가 본문(예: 쌍을 이룬 위임 점수를 가진 EPA 평가)을 사용하여 학습할 수 있습니다. 그런 다음 레이블이 지정되지 않은 평가의 점수를 모델을 사용하여 추정할 수 있습니다. 이러한 시스템은 개별 레지던트에 대한 대량의 텍스트 데이터에 대한 요약적인 해석을 제공할 수 있어 잠재적으로 CCC의 의사 결정을 지원할 수 있습니다. 또는 교육자는 전공의에게 형성적인 무료 텍스트 피드백을 제공하는 데만 집중하고, 각 EPA 의견을 '점수'로 종합적으로 평가하는 작업은 컴퓨터에 맡기는 시스템을 상상해 볼 수 있습니다.
On a broader scale, this manuscript demonstrates the potential utility of NLP strategies in surgical education. Not surprisingly, surgical educators use different vocabulary and structure in their comments on resident performance at different EPA entrustment levels. Critically, LDA was able to pick up on these important differences, and highlight key differentiating aspects of entrustment levels in ways that are interpretable to human raters. This is a promising first step in a broader integration of NLP into surgical education. As assessment frameworks that consolidate large volumes of text-based data on resident performance are developed, strategies to interpret this data at scale are needed. NLP can help surgical education scale with its data. For example, extraction-based automated document summarization can highlight the most important comments within a corpus of narrative feedback provided to a resident—allowing for rapid review via CCC committee.10,11 Predictive modeling techniques, such as supervised LDA (sLDA) can be trained using a body of text assessments with an associated response (e.g. EPA assessments with a paired entrustment score) with the goal of identifying latent topics predictive of the response (score) instead of the topics most adept at classifying the assessments into groups. Then an unlabeled assessment’s score can be estimated using the model. Such a system would be able to provide a summative interpretation of a large body of text data for any individual resident, potentially assisting CCC decision making. Or one could imagine a system in which educators can focus only on providing formative free text feedback to their residents, while the job of summatively assessing this each EPA comment for a ‘score’ could be left to the computer.
외과 교육에서 NLP의 잠재적 가능성에도 불구하고 이 연구에는 몇 가지 한계가 있습니다. 무엇보다도, 이 연구는 단일 센터에서 단일 EPA 평가를 시행한 연구이므로 일반화 가능성에 한계가 있습니다. 향후 무료 텍스트 데이터를 EPA 평가에 통합하는 다른 센터와 협력하여 위치 또는 구현 전략에 따라 피드백 패턴이 어떻게 달라질 수 있는지 살펴보고자 합니다. 이 연구는 또한 일반외과를 위해 만들어진 처음 5개의 EPA만 평가하는데, 이는 레지던트가 졸업할 때까지 축적해야 하는 전체 수술 지식의 일부만을 다루고 있습니다. NLP 기술은 낮은 품질의 텍스트 데이터를 보완할 수 없습니다. 평가자는 여전히 알고리즘이 분석할 수 있도록 레지던트에게 고품질 텍스트 피드백을 제공해야 합니다. 마지막으로, 현재의 토픽 모델링 기법은 여전히 '단어 가방' 모델에 국한되어 있어 결과 토픽에 대한 사람의 해석이 필요합니다. 이 원고의 다른 연구자나 독자는 우리의 해석에 동의하지 않을 수 있습니다. 저희의 데이터와 해석은 EPA의 위임과 자율성에 대한 논의를 시작하기 위한 것이지 최종적인 권위 있는 중재자 역할을 하는 것이 아닙니다. 궁극적으로 컴퓨터가 자연어 데이터에서 의미론(개념 가방) 또는 실용론(내러티브 가방)을 구분하여 더 유용한 정보를 제공할 수 있게 되겠지만, 그렇게 될 때까지 이러한 중요한 논의를 미룰 이유가 없다고 생각합니다.
Despite the potential promise for NLP in surgical education, this study has several limitations. Foremost, this was a single center study with a single implementation of EPA assessments, limiting generalizability. We hope to collaborate with other centers that incorporate free text data into their EPA assessments in the future to see how patterns in feedback might vary based on location or implementation strategy. This study also only assesses the first 5 EPAs created for general surgery, which cover only a fraction of the total knowledge of surgery which residents must accumulate by graduation. NLP techniques cannot make up for low quality text data. Evaluators will still need to provide high-quality text feedback to residents for the algorithms to analyze. Finally, current topic modeling techniques are still limited to the ‘bag of words’ model, requiring human interpretation of resulting topics. Different researchers or readers of this manuscript may disagree with our interpretations. We encourage this—our data and interpretations are meant to start discussions about entrustment and autonomy in EPAs, not function as a final authoritative arbiter. Eventually, computers may be able to distinguish semantics (bag of concepts) or pragmatics (bag of narratives) from natural language data to provide more useful input, but we see no reason to delay these important discussions until that is possible.
결론
Conclusions
잠재 디리클레 할당을 사용한 토픽 모델링은 EPA 위임 수준을 구분할 수 있습니다. LDA로 생성된 주제는 위임 수준에 일관되게 매핑되어 외과의 교육자가 수련의의 자율성을 설명하고 위임을 부여하는 방식에 대한 통찰력을 제공합니다. 이 데이터는 향후 EPA 위임 로드맵을 작성하고 기존 로드맵을 데이터 기반으로 개정하는 데 사용할 수 있습니다. 외과 교육에서 NLP 방법론이 더욱 발전하면 외과의사 교육자는 대량의 텍스트 평가 데이터를 확장 가능한 방식으로 분석할 수 있습니다.
Topic modeling using latent Dirichlet allocation is capable of discriminating between EPA entrustment levels. Topics generated by LDA map coherently to entrustment levels, providing insight on how surgeon educators describe trainee autonomy and grant entrustment. This data can be used to inform the creation of future EPA entrustment roadmaps, and data-driven revision of existing ones. Further development of NLP methodologies in surgical education may allow surgeon educators to analyze large amounts of text assessment data in a scalable fashion.
Natural language processing and entrustable professional activity text feedback in surgery: A machine learning model of resident autonomy
PMID: 33256944
PMCID: PMC7969407
DOI: 10.1016/j.amjsurg.2020.11.044
Free PMC article
Background: Entrustable Professional Activities (EPAs) contain narrative 'entrustment roadmaps' designed to describe specific behaviors associated with different entrustment levels. However, these roadmaps were created using expert committee consensus, with little data available for guidance. Analysis of actual EPA assessment narrative comments using natural language processing may enhance our understanding of resident entrustment in actual practice.
Methods: All text comments associated with EPA microassessments at a single institution were combined. EPA-entrustment level pairs (e.g. Gallbladder Disease-Level 1) were identified as documents. Latent Dirichlet Allocation (LDA), a common machine learning algorithm, was used to identify latent topics in the documents associated with a single EPA. These topics were then reviewed for interpretability by human raters.
Results: Over 18 months, 1015 faculty EPA microassessments were collected from 64 faculty for 80 residents. LDA analysis identified topics that mapped 1:1 to EPA entrustment levels (Gammas >0.99). These LDA topics appeared to trend coherently with entrustment levels (words demonstrating high entrustment were consistently found in high entrustment topics, word demonstrating low entrustment were found in low entrustment topics).
Conclusions: LDA is capable of identifying topics relevant to progressive surgical entrustment and autonomy in EPA comments. These topics provide insight into key behaviors that drive different level of resident autonomy and may allow for data-driven revision of EPA entrustment maps.
Keywords: Assessment; Entrustable professional activities; Feedback; Natural language processing; Surgery education.
Copyright © 2020 Elsevier Inc. All rights reserved.
'Articles (Medical Education) > 평가법 (Portfolio 등)' 카테고리의 다른 글
| 전공의의 임상추론 문서의 평가 자동화를 위한 머신러닝 모델 개발 및 타당화(J Gen Intern Med. 2022) (0) | 2023.07.19 |
|---|---|
| 인공지능을 활용하여 어떻게 피드백이 위임을 나타나는지 탐색하기 (Med Educ, 2022) (0) | 2023.07.18 |
| 구두평가 맥락에서 질문하기: 분류체계와 기본원칙 (J Med Educ Curric Dev. 2020) (0) | 2023.05.23 |
| 생성형 인공지능의 시대에 평가를 다시 생각하기 (Med Educ, 2023) (0) | 2023.05.23 |
| 전공의 수련과정에서 직접관찰의 현상학: 밀러의 'does'레벨은 관찰가능한가? (Med Educ, 2022) (0) | 2023.04.23 |