임상추론 평가방법: 스코핑 리뷰와 실용적 가이드(Acad Med, 2019)
Clinical Reasoning Assessment Methods: A Scoping Review and Practical Guidance
Michelle Daniel, MD, MHPE, Joseph Rencic, MD, Steven J. Durning, MD, PhD, Eric Holmboe, MD, Sally A. Santen, MD, PhD, Valerie Lang, MD, MHPE, Temple Ratcliffe, MD, David Gordon, MD, Brian Heist, MD, MSc, Stuart Lubarsky, MD, MHPE, Carlos A. Estrada, MD, MS, Tiffany Ballard, MD, Anthony R. Artino Jr, PhD, Ana Sergio Da Silva, PhD, Timothy Cleary, PhD, Jennifer Stojan, MD, MHPE, and Larry D. Gruppen, PhD

임상적 추론의 정의는 매우 다양하다.1 이 논문의 목적상 [임상 추론]은 '임상 의사가 환자를 진단하고 치료하기 위해 데이터를 관찰, 수집 및 해석하는 기술, 프로세스 또는 결과로 정의]된다. 임상 추론은 맥락적 요소와 상호작용하는 [의식적 및 무의식적 인지 작업]을 모두 수반한다. 맥락적 요인에는 [환자의 고유한 상황과 선호도, 그리고 진료 환경의 특성이 포함]되며 이 밖에도 많은 것들이 있다. 임상 추론의 여러 구성 요소를 식별할 수 있다1:
- 정보 수집,
- 가설 생성,
- 문제 표현 형성,
- 감별 진단 생성,
- 우선적 또는 작업 진단 선택,
- 진단 정당성 제공,
- 관리 또는 치료 계획 개발.
Definitions of clinical reasoning vary widely.1 For the purposes of this paper, clinical reasoning is defined as a skill, process, or outcome wherein clinicians observe, collect, and interpret data to diagnose and treat patients.2,3 Clinical reasoning entails both conscious and unconscious cognitive operations interacting with contextual factors.4,5 Contextual factors include, but are not limited to, the patient’s unique circumstances and preferences and the characteristics of the practice environment. Multiple components of clinical reasoning can be identified1:
- information gathering,
- hypothesis generation,
- forming a problem representation,
- generating a differential diagnosis,
- selecting a leading or working diagnosis,
- providing a diagnostic justification, and
- developing a management or treatment plan.6
다양한 분야(예: 인지 심리학, 사회학, 교육)의 많은 이론(예: 스크립트, 이중 과정 및 인지 부하 이론)이 임상 추론에 대한 연구를 제공한다. 이러한 임상 추론의 정의와 이러한 다중 이론은 현재 연구의 기초를 제공한다.
A number of theories (e.g., script, dual process, and cognitive load theories) from diverse fields (e.g., cognitive psychology, sociology, education) inform research on clinical reasoning.7,8 This definition of clinical reasoning and these multiple theories provide the foundation for the current work.
효과적인 임상 추론은 임상 역량의 핵심이다. 대학원 의학 교육 인증 위원회, 9개의 CanMED 프레임워크 및 유럽의 조정 프로젝트(의학)는 모두 임상 추론을 핵심 역량으로 설명한다. 의료 교육 연속체에 걸쳐 임상 역량(임상 추론 포함)의 개발을 보장하려면 평가에 대한 증거 기반 접근법이 필요하다. 현재 임상추론에 대한 광범위한 평가가 있으며, 이러한 도구의 기반이 되는 문헌은 광범위하게 분산되어 있으며, 다양한 분야와 여러 의학 전문 분야를 넘나들고 있어서 [특정한 목표, 요구 및 자원에 맞는 평가를 선택 및 구현]하려는 교수자를 어렵게 만든다. 또한 여러 평가들이 서로 다른 맥락(예: 직장 기반 및 비직장 기반 환경)에서 사용하도록 설계된다. 임상추론 평가방법은 수와 다양성이 많아서 목적에 적합한 평가를 선택하는 데 어려움이 있고, 임상추론 평가가 진보하려면 현재 근거의 통합이 필요하다.
Effective clinical reasoning is central to clinical competence. The Accreditation Council for Graduate Medical Education,9 the CanMEDS framework,10 and the Tuning Project (Medicine) in Europe11 all describe clinical reasoning as a core competency. Ensuring the development of clinical competence (including clinical reasoning) across the medical education continuum requires an evidence-based approach to assessment. There is currently a wide array of clinical reasoning assessments, and the literature on which these tools are based is widely dispersed, crossing different fields and multiple medical specialties, which presents a challenge for medical educators attempting to select and implement assessments aligned with their particular goals, needs, and resources. These assessments are often designed for use in different contexts (e.g., workplace- and non-workplace-based environments).12 The sheer number and diversity of clinical reasoning assessment methods create challenges for selecting assessments fit for the purpose, so a synthesis of the current evidence is needed to advance assessment practices for this core competency.
우리의 목표는 의료 교육자에게 참고가 되는 평가 방법의 실용적인 개요를 만드는 것이었다. 임상 추리 평가 문헌의 풍부함과 복잡성을 고려하여 다음 질문을 탐구하기 위해 범위 검토를 수행하기로 결정했다. 어떤 임상적 추론 평가 방법을 사용할 수 있습니까? 이러한 평가 방법의 정의 기능은 무엇이며, 일반적으로 어떻게 사용됩니까? 각 방법에 대한 타당성 고려사항(내용, 대응 프로세스, 내부 구조, 다른 변수와의 관계, 임상 실무 성과에 대한 결과 또는 결과)은 무엇입니까? 각 방법의 실현 가능성 문제, 장점 및 단점은 무엇입니까? 각 방법의 상대적 강점과 약점을 임상 추론 평가 프로그램을 구축하는 데 어떻게 사용할 수 있는가?
Our aim was to create a practical compendium of assessment methods to serve as a reference for medical educators. Given the richness and complexity of the clinical reasoning assessment literature, we chose to perform a scoping review to explore the following questions: What clinical reasoning assessment methods are available? What are the defining features of these assessment methods, and how are they typically used? What are the validity considerations (content, response process, internal structure, relationships to other variables, and consequences or outcomes on clinical practice performance) for each method? What are the feasibility issues, advantages, and disadvantages of each method? How might the relative strengths and weaknesses of each method be used to construct a clinical reasoning assessment program?
방법
Method
방법론 검토
Review methodology
우리는 이 검토를 수행함에 있어 구성주의적 연구 패러다임을 채택했다. 우리는 우리의 질문이 탐색적이었고 예비 검색에서 복잡하고 이질적인 문학의 본체가 밝혀졌기 때문에 scoping methodology 을 선택했다. 우리는 임상 추리 평가 방법의 광범위한 분야를 설명하기를 원했지만, 의학 교육자에 대한 관련성을 보장하기 위해 실용적인 적용에 초점을 맞추고 싶었다. 우리는 가장 일반적으로 사용되는 방법에 대해 보고하지만, 모든 것을 망라하려고 하지는 않습니다. 이 검토는 STORES(Structured Approach to Reporting in Healthcare Education of Previdence Compositation) 스테이트먼트에 따라 제시된다.
We adopted a constructivist research paradigm in conducting this review. We chose a scoping methodology because our questions were exploratory and because preliminary searches had revealed a complex and heterogeneous body of literature.13 We wanted to describe the broad field of clinical reasoning assessment methods,14 yet remain focused on practical applications to ensure relevance for medical educators. We report on the most commonly used methods, but we do not seek to be exhaustive. This review is presented in accordance with the STORIES (Structured Approach to the Reporting in Healthcare Education of Evidence Synthesis) statement.15
검색 전략
Search strategy
초기 검색 및 기사 선택 프로세스에서 확립된 PRISMA(Preferred Reporting Items for Systematic Reviews and Meta-Analyses) 가이드라인을 따랐습니다. 경험이 풍부한 연구 사서가 검색 전략을 설계하는 데 도움을 주었습니다(보조 디지털 부록 1 참조). 임상 추론을 위한 수많은 동의어는 잘 알려진 임상 추리 평가 방법뿐만 아니라 광범위한 평가 용어와 결합되었다. 검색일로부터 2016년 2월 29일까지 Ovid MEDLINE, CINAHL, ERIC, PsycINFO, Scopus, Google Scholar, New York Academy of Medicine Grey Literature Report에서 검색을 실행했습니다. 검색된 인용문은 체계적인 검토를 수행하기 위한 온라인 데이터 관리 시스템인 DistillerSR(캐나다 온타리오주 오타와)에 업로드되었습니다.
We followed established PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) guidelines16 for our initial search and article selection process. An experienced research librarian helped design the search strategy (see Supplemental Digital Appendix 1 at https://links.lww.com/ACADMED/A631). Numerous synonyms for clinical reasoning were combined with a broad range of assessment terms, as well as well-known clinical reasoning assessment methods. We ran the search in Ovid MEDLINE, CINAHL, ERIC, PsycINFO, Scopus, Google Scholar, and the New York Academy of Medicine Grey Literature Report from each database’s inception through February 29, 2016, the date of our search. Retrieved citations were uploaded in DistillerSR (Evidence Partners, Ottawa, Ontario, Canada), an online data management system for performing systematic reviews.
기사 심사 및 리뷰
Screening and review of articles
임상 추론 평가 문헌의 초기 탐구를 위한 광범위한 포함 기준에서 시작했다.
- (1) 훈련 또는 실습의 모든 단계에서 건강 전문직(예: 의학, 간호, 치과, 물리 또는 직업 치료),
- (2) 모든 연구 설계 유형,
- (3) 임상 추론 평가 방법(또는 도구)을 명시적으로 연구한 모든 기사 (또는 동의어(예: 임상, 진단, 치료, 예후 의사결정 또는 문제 해결). 보충 디지털 부록 1 참조).
We began with broad inclusion criteria for our initial exploration of the clinical reasoning assessment literature:
- (1) any health profession (e.g., medicine, nursing, dentistry, physical or occupational therapy) at any stage of training or practice;
- (2) all study design types; and
- (3) any article that explicitly studied a method (or tool) of clinical reasoning assessment (or synonymous terms—e.g., clinical, diagnostic, therapeutic, or prognostic decision making or problem solving; see Supplemental Digital Appendix 1 at https://links.lww.com/ACADMED/A631).
영어로 된 기사가 아닌 경우, 의사결정을 임상 추론의 더 큰 인지 과정 대신 특정 임상 문제(예: 심방 세동의 경우)에만 적용한 경우 또는 기사가 연구를 구성하지 않는 논문 또는 해설인 경우 기사는 제외되었다. 리뷰 기사는 데이터 추출에서 제외되었지만 눈덩이 확대를 통해 추가 기사를 식별하는 데 사용되었다. 최종 합성에 앞서, 우리는 의대생, 레지던트 또는 의사에 관한 연구에 초점을 맞추기로 결정했고, 검토를 위한 총 기사 수를 줄이고, 임상 추론에 초점을 맞추도록 다른 보건 직업에 대한 강조를 제거하기로 했다. (또한 비판적 사고와 같은 다른 건강 직업의 관련성이 있는 것이 아니라 별개의 구조에 대해서도 마찬가지입니다.)
Articles were excluded if they were not in English, if decision making was applied only to a specific clinical problem (e.g., a case of atrial fibrillation) instead of the larger cognitive processes of clinical reasoning, or if the article was an essay or commentary that did not constitute research. Review articles were excluded from data extraction but were used to identify additional articles via snowballing. Prior to the final synthesis, we decided to focus on medical student, resident, or physician studies and de-emphasized the other health professions to both reduce the total number of articles for review and ensure that the focus was on clinical reasoning (and not on related but distinct constructs in the other health professions, such as critical thinking).17
다양한 작가 조합이 여러 단계로 기사를 검토했다. 잠재적으로 관련된 제목과 요약은 작가 쌍에 의해 선별되었다. 전문 기사는 포함 및 제외 기준에 따라 다양한 작가 쌍에 의해 적격성을 평가받았다. 적격성 평가를 위한 전문 기사의 평가에 앞서, 우리는 우리 팀의 요약과 집합적 전문지식에 대한 예비 분석을 바탕으로 평가 방법별로 그것들을 분류했습니다. 우리는 염두에 두고 있었다.
- 오래된 방법이 출판된 기사(예: 객관식 질문[MCQ])에 더 자주 표시될 수 있다.
- 일반적인 교육 관행은 자주 작성되지 않을 수 있다(예: 구술 사례 프레젠테이션(OCP)).
- 실현 가능성이 구현 및 사용에 영향을 미칠 수 있다(예: fMRI).
Different combinations of authors (M.D., J.R., S.J.D., E.H., S.A.S., V.L., T.R., D.G., B.H., S.L., C.A.E., T.B., A.R.A., A.S.D.S., T.C., J.S., L.D.G.) reviewed the articles in multiple stages. Potentially relevant titles and abstracts were screened by pairs of authors. Full-text articles were then assessed by different pairs of authors for eligibility based on the inclusion and exclusion criteria. Prior to the assessment of full-text articles for eligibility, we sorted them by assessment methods based on our preliminary analyses of the abstracts and the collective expertise of our team. We were mindful
- that older methods may be more frequently represented in published articles (e.g., multiple-choice questions [MCQs]),
- that common educational practices may not necessarily be written about often (e.g., oral case presentations [OCPs]), and
- that feasibility may affect implementation and use (e.g., functional magnetic resonance imaging).
각 평가 방법은 해당 기사를 추가로 검토하고 합성한 두 명의 저자에게 할당되었다. 어느 단계에서든 의견 불일치는 논의를 통해 해결되었으며, 필요한 경우 제3의 저자가 참여하였다. 데이터 추출 수준에서 코헨 카파 통계량을 사용하여 기준 간 합의를 평가했다.
Each assessment method was assigned to a pair of authors who further reviewed and synthesized those articles. Disagreements at any stage were resolved through discussion to reach consensus, with involvement of a third author if needed. Interrater agreement was assessed using Cohen kappa statistic at the data extraction level.
데이터 추출 양식을 사용하여 다음을 포함한 평가 방법의 특성에 대한 정보를 수집했다.
- 자극(예: 서면 Vignette, 표준화된 환자(SP), 실제 환자)
- 응답 형식(예: 선택된 응답, 작성된 자유 텍스트, 성능)
- 채점(예: 고정 답안, 체크리스트, 글로벌 등급 척도)
- 일반적인 용도(예: 낮은, 중간, 높은 수준의 의사결정)
A data extraction form (see Supplemental Digital Appendix 2 at https://links.lww.com/ACADMED/A632) was used to capture information on the characteristics of assessment methods, including
- the stimulus (e.g., written vignette, standardized patients [SPs], real patients);
- response format (e.g., selected response, constructed free text, performance);
- scoring (e.g., fixed answer, checklist, global rating scale); and
- common uses (e.g., low-, medium-, or high-stakes decisions).
이 양식은 도구의 타당성 및 타당성뿐만 아니라 방법과 관련된 주제(예: 맥락의 영향)에 관한 정보도 포착했다. 이 검토의 목적상, 우리는 타당성을 복수의 근거 소스(예: 내용, 대응 프로세스)가 있는 통합된 구성으로 보았다.18 이것은 scoping review였기 때문에 article의 품질은 공식적으로 평가되지 않았다. 추출은 평가 방법에 대한 모든 기사를 완전히 검토하거나 새로운 평가 통찰력을 제공하지 않을 때까지 진행되었습니다.
The form also captured information regarding a tool’s feasibility and validity, as well as any themes (e.g., the influence of context) related to the method. For the purposes of this review, we viewed validity as a unified construct with multiple sources of evidence (e.g., content, response process).18 Because this was a scoping review, the quality of articles was not formally assessed. Extraction proceeded until all articles for an assessment method had been fully reviewed or no new assessment insights were forthcoming.
Data 합성
Data synthesis
추출된 데이터를 사용하여 각 평가 방법을 요약하고 일반적인 자극, 대응 형식, 점수, 일반적인 용도, 타당성 고려 사항, 타당성 문제, 장점 및 단점을 설명하는 설명적 부록을 구성했다. 타당성 고려사항은 교육 및 심리 테스트 표준에 설명된 메시의 5개 영역에 따라 제시된다. 이 부록에는 텍스트를 뒷받침하는 참고문헌이 몇 가지 나열되어 있지만, 일부 방법에서는 60개가 넘는 기사가 있었기 때문에 검토한 기사 전체 목록은 포함되어 있지 않습니다. 일부 경우, 우리는 이러한 부록과 결과의 핵심 사항을 뒷받침하기 위해 (검토에 포함된 목록 외의) 추가적인 seminal references 자료를 사용했다. 이러한 참고 자료는 포함 기준을 충족하지 못했기 때문에 검토에 포함되지 않았다.
We used the extracted data to construct descriptive appendixes that summarize each assessment method, describing common stimuli, response formats, scoring, typical uses, validity considerations, feasibility issues, advantages, and disadvantages. Validity considerations are presented according to Messick’s five domains as described in Standards for Educational and Psychological Testing.19 These appendixes list some references to support the text, but they do not include the full list of the articles reviewed because, for some methods, there were over 60 articles. In some cases, we used additional seminal references (outside of those included in the review) to support key points in these appendixes and in the Results below; these references were not included in the review because they did not meet the inclusion criteria.
검토 과정에서 특정 평가 방법이 임상 추론의 다른 구성 요소를 측정하는 데 다른 방법보다 더 적합하다는 것이 명백해졌다(위 참조). [임상추론 평가 방법 선택을 위한 실용적 가이드 제작]을 목표로 했기 때문에, 우리는 집단적 판단을 사용하여, 임상추론의 다양한 구성 요소를 측정할 수 있는 평가 방법을 식별했다.
Over the course of the review, it became apparent that certain assessment methods were better suited than others to measure different components of clinical reasoning (see above). Because we aimed to produce a practical guide for medical educators to select clinical reasoning assessment methods, we used our collective judgments to identify assessment methods more or less capable of measuring the different components of clinical reasoning.
우선, 각 컴포넌트의 작업 정의에 합의했습니다(표 1). 다음으로 Qualtrics(2018년 버전, Qualtrics, Provo, Utah, Provo)를 통해 전체 작성자 그룹에 설문조사를 보내 각 평가 방법을 다양한 구성 요소를 평가할 수 있는 능력 측면에서 평가하도록 요청했습니다. (0 = 주소 미지정, 1 = 2차 또는 주변기기, 2 = 1차 초점, NA = 응답 불가). 결과의 평균을 산출하여 다음과 같은 척도로 보고했습니다. 0.0~0.5 = 불량, 0.6~1.0 = 평균, 1.1~1.5 = 양호, 1.6~2.0 = 매우 양호.
First, we agreed on working definitions for each of the different components (Table 1). Next, we sent a survey via Qualtrics (version from 2018, Qualtrics, Provo, Utah) to the full author group, asking them to rate each assessment method in terms of its ability to assess the different components (0 = not addressed, 1 = secondary or peripheral, 2 = primary focus, NA = cannot answer). We averaged the results and reported them on the following scale: 0.0–0.5 = poor, 0.6–1.0 = average, 1.1–1.5 = good, and 1.6–2.0 = very good.
표 1 임상 추론의 다양한 구성 요소에 대한 작업 정의
Table 1 Working Definitions for the Different Components of Clinical Reasoning
정보 수집 Information gathering72,73
- 가설을 생성하거나 구체화하는 데 필요한 데이터를 얻는 과정입니다. 이 과정은 일반적으로 기록 작성, 물리적 수행, 실험실 또는 방사선 데이터 획득, 의료 기록 검토 등을 포함하는 능동적active 프로세스이지만, (관찰을 통한 것처럼) 암묵적일 수도 있습니다. 수집할 정보의 선택은 질병의 지식 표현(예: 스크립트, 스키마)에 의해 결정됩니다.
- The process of acquiring the data needed to generate or refine hypotheses. This is usually an active process that includes taking a history, performing a physical, acquiring lab or radiographic data, reviewing the medical record, etc., but may be implicit (through observation) as well. The selection of information to gather is driven by knowledge representations of disease (i.e., scripts, schema).
가설 생성 Hypothesis generation74,75
- 의사가 환자의 임상 소견을 설명할 수 있는 질병을 찾는 초기 비분석적 또는 분석적 과정입니다. 가설 생성은 정보 수집을 피드백하는 반복 프로세스에서 질병의 지식 표현을 활성화하는 것을 포함한다(예: 가설 생성은 더 많은 정보 수집으로 이어지고, 더 많은 가설 생성 및/또는 개선으로 이어진다).
- An early nonanalytic or analytic process by which a physician tries to find diseases that can explain a patient’s clinical findings. Hypothesis generation involves activation of knowledge representations of disease in an iterative process that feeds back on information gathering and vice versa (e.g., hypothesis generation leads to more information gathering, which leads to more hypothesis generation and/or refinement).
문제 표현 Problem representation74,76
- [의미적 한정자]와 [주요 발견]을 포함하는 요약으로 전달될 수 있는, 사례의 모든 관련 측면(환자의 임상 소견, 생체 심리학적 차원 등)의 역동적 정신적 표현.
- A dynamic mental representation of all the relevant aspects of the case (including the patient’s clinical findings, biopsychosocial dimensions, etc.) that can be communicated in a summary that includes semantic qualifiers and key findings.
감별 진단 Differential diagnosis77,78
- 문제 표현의 최선의 요약 범주를 나타내는 진단 가설의 목록(참고: 전공이 달라지면 감별진단의 우선 순위가 달라질 수 있다. 예를 들어, EM에서는 생명을 위협하는 질병이 먼저 나열되는 경우가 많은 반면 IM에서는 일반적으로 가장 가능성이 높은 질병이 먼저 나열된다.) [자신감의 강도]와 [표현에 대한 증거가 변화함]에 따라 우선적 진단leading diagnosis이 나타난다.
- A list of diagnostic hypotheses that represent the best summary categorizations of the problem representation (Note: Different specialties may have different priorities when it comes to ordering the differential; e.g., in EM, life-threatening diseases are often listed first, whereas in IM, the most likely diseases are usually listed first). As the strength of confidence and evidence for these representations change, a leading diagnosis emerges.
선행 진단 또는 실제 진단 Leading or working diagnosis79
- 비록 확정적이지 않더라도, 추가 검사를 진행하거나 치료를 시작하기 위해, 특정 질병일 확률이 의사 자신의 임계값을 초과한 진단입니다
- A diagnosis for which a physician’s probability of a given disease has crossed his or her threshold to pursue additional testing or to initiate treatment, even if the diagnosis is not definitive.
진단의 정당성 Diagnostic justification77,80
- 정보 수집의 증거(핵심 임상 소견)를 사용하여, 가능한 한 하나 이상의 진단을 선택하고, 다른 가능한 진단을 비교 및 대조하면서 그 선택을 옹호하려는 시도. 정당화는 사회적으로 필요할 때 의사소통(구술 또는 서면)을 수반하는 경우가 많으며, 선행 임상 추론 과정의 일부가 아닐 수도 있습니다.
- The attempt to use the evidence (key clinical findings) from information gathering to choose one or more diagnoses as most likely and to defend that choice, comparing and contrasting other possible diagnoses. Justification often involves communication (orally or in writing) when socially required and may not be part of the a priori clinical reasoning process.
관리 및 치료
Management and treatment79,81
- 임상추론 뒤에 따라오는 행동으로서, 예측, 관리, 치료, 예방 전략, 증상완화(삶의 질 향상 포함) 및 그러한 행동의 정당화를 포함한다.
- The actions that follow the clinical reasoning process, including prognostication, management, treatment, prevention strategies, and palliation of symptoms (including improvement of quality of life) and justification for such actions.
결과.
Results
초기 데이터베이스 검색과 눈덩이 확장으로 14,709개의 레코드가 생성되었습니다. 중복으로 1,849장을 삭제하고, 12,860장의 레코드는 제목과 추상별로 심사했습니다. 이 심사 후, 11,421개의 기사는 임상 추론의 평가와 관련이 없다는 이유로 제외되었다. 나머지 1,439개 기사는 포함 및 제외 기준에 따라 전문 평가를 받았다. 이 단계에서 901개 기사는 분석에서 제외되었으며, 주된 이유는 임상 추론 평가 방법을 명시적으로 연구하지 않았기 때문이다. 결국, 검토 대상에는 538개 조항(1966년부터 2016년까지)이 포함되었다(그림 1 및 보충 디지털 부록 3 참조). 이 기사들 중 161개는 다른 건강 직업에 초점을 맞췄다. 최종 종합에서는 의대생, 레지던트, 의사 관련 기사 377건만을 중점적으로 다루었다. 이 방법에 대해 계산된 측정기 간 합치도 0.83에서 0.86 사이의 범위에서 높았다.
The initial database search and snowballing yielded 14,709 records. We removed 1,849 as duplicates, leaving 12,860 records to be screened by title and abstract. After this screening, 11,421 articles were excluded because they did not pertain to the assessment of clinical reasoning. The 1,439 remaining articles underwent full-text evaluation based on inclusion and exclusion criteria. At this stage, 901 articles were excluded from the analysis, with the main reason being that they did not explicitly study a clinical reasoning assessment method. In the end, 538 articles (from 1966 to 2016) were included in the review (see Figure 1 and Supplemental Digital Appendix 3 at https://links.lww.com/ACADMED/A633). Of these articles, 161 focused on other health professions. In the final synthesis, we focused exclusively on the 377 articles related to medical students, residents, and physicians. The interrater agreement calculated for the methods was high, ranging from 0.83 to 0.86.
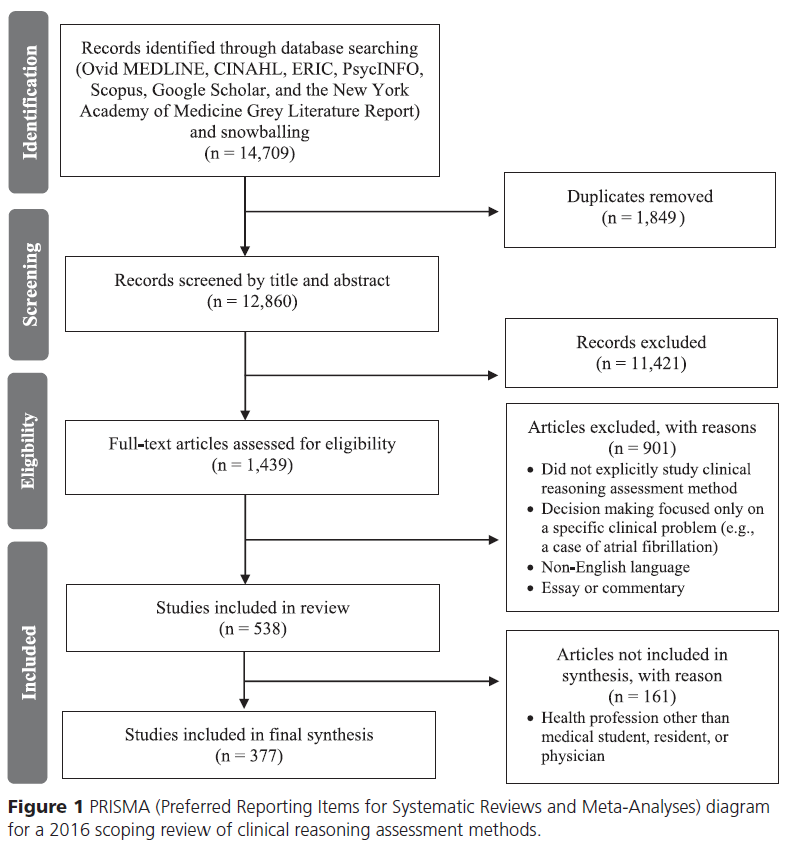
포함된 기사에는 임상 전 의대생부터 임상 의대생, 레지던트 및 개업의에 이르기까지 광범위한 학습자가 포함되었습니다. 기사에 실린 작품들은 많은 다른 나라들에서 나왔지만, 대부분은 미국, 유럽, 캐나다에서 왔다. 우리는 기사를 20개의 다른 평가 방법(실험적 또는 참신한 범주 및 19가지 방법)으로 묶었다.
- 일부 방법에는 다수의 기사가 있었다(예: 스크립트 일치 테스트 및 기술 강화 시뮬레이션 각각 60개 이상).
- 일부 방법들은 매우 적은 수의 논문만이 검색되었다(예: 임상 또는 종합 통합 퍼즐(CIPs)과 차트 자극 리콜(CSR)은 각각 3개였다.)
보충 디지털 부록 4는 공통 자극, 대응 형식, 점수 매기기, 일반적인 사용, 타당성 고려사항, 타당성 문제, 장점 및 단점을 포함하여 각 평가 방법을 요약하는 설명 부록을 제공하고 있으며, 이를 뒷받침하는 참고 자료를 제공한다.
The included articles encompassed a broad array of learners from preclinical medical students to clinical medical students, residents, and practicing physicians. The work in the articles came from many different countries; however, the majority came from the United States, Europe, and Canada. We clustered the articles into 20 different assessment methods (an experimental or novel category and 19 methods; see below).
- Some methods had a large number of articles (e.g., script concordance testing and technology-enhanced simulation each had over 60).
- Others had very small numbers of articles (e.g., clinical or comprehensive integrative puzzles [CIPs] and chart-stimulated recall [CSR] each had 3).
Supplemental Digital Appendix 4 (at https://links.lww.com/ACADMED/A634) shows the descriptive appendixes we constructed that summarize each assessment method, including common stimuli, response formats, scoring, typical uses, validity considerations, feasibility issues, advantages, and disadvantages, as well as supporting references.
방법은 매우 이질적이었지만, 우리는 신뢰성의 연속체를 따라 세 가지 광범위한 범주를 식별했다.
- 비작업장 기반 평가(Non-WBAs),
- 시뮬레이션 임상 환경 평가
- 작업장 기반 평가(WBAs)
Although the methods were quite heterogeneous, we identified three broad categories, along a continuum of authenticity:
- non-workplace-based assessments (non-WBAs),
- assessments in simulated clinical environments, and
- workplace-based assessments (WBAs).
우리는 이러한 범주에 예외가 있으며 일부 방법이 현실적으로 여러 범주에 배치될 수 있다는 것을 인식한다(예: 자체 조절 학습 미세 분석(SRL-M)). 독특하거나 참신하거나 탐색적인 평가는 실험적이거나 참신한 방법 그룹에 배치되었다. 중요한 방법들이 결국 이 작업 본체에서 나올 수 있지만, 이러한 방법들에 대해 상세히 보고하는 것은 가능하지 않았으며, 이러한 방법들은 보충 디지털 부록 4에서만 다루어진다.
We recognize that these categories have exceptions and that some methods could realistically be placed in multiple categories (e.g., self-regulated learning microanalysis [SRL-M]). Assessments that were unique, novel, or exploratory were placed into an experimental or novel methods group. Although important methods may ultimately emerge from this body of work, it was not feasible to report on all of these methods in depth, and they are only addressed in Supplemental Digital Appendix 4 (at https://links.lww.com/ACADMED/A634).
비WBA
Non-WBAs
우리는 주로 "교실" 평가 또는 비 WBA에 초점을 맞춘 10가지 방법을 식별했다.
We identified 10 methods that largely focused on “classroom” assessments or non-WBAs.
MCQ는 최대 5개의 잠재적 답변 또는 대안이 뒤따르는 임상적 답변으로 구성되며, 단일 최선의 답변, 대안 조합, 각 대안에 대한 참 또는 거짓 또는 매칭을 요구하도록 구성될 수 있다.
- MCQs consist of a clinical vignette followed by up to five potential answers or alternatives and may be structured as to require a single best answer, a combination of alternatives, true or false for each alternative, or matching.20
확장 매칭 질문(EMQ)은 대안 목록에서 선택된 단일 최선의 답변과 함께 임상적 질문을 사용하는 MCQ와 유사하지만, 여러 질문에 적용되는 더 긴 잠재적 답변 목록(5개 이상)을 포함하고 있다.
- Extended matching questions (EMQs) resemble MCQs in their use of a clinical vignette with a single best answer selected from a list of alternatives, but they contain longer lists of potential answers (more than five) that are applied to multiple questions.21,22
단답형 또는 장답형(메세지) 질문은 임상적 질문에 이어 몇 단어에서 여러 문장에 이르는 길이의 구성된 자유 텍스트 응답을 사용하여 하나 이상의 질문에 답하는 방법을 설명한다.
- Short- or long-answer (essay) questions describe a method wherein a clinical vignette is followed by one or more questions answered using constructed free-text responses that range in length from a few words to several sentences.23,24
변형에세이문제(MEQ)은 사례의 일련 정보를 시간순으로 제공하는 방법입니다. 한 문항이 제시되면, 학습자는 작성된 자유 텍스트(에세이) 형식으로 결정을 문서화해야, 그 다음 문항을 볼 수 있습니다.
- Modified essay questions (MEQs) are a method wherein serial information is provided about a case chronologically.25,26 After each item, learners must document a decision in a constructed free-text (essay) format before they can view subsequent items.
환자 관리 문제(PMP)는 진단 및 관리에 특정 리소스를 사용할 수 있는 컨텍스트가 풍부한 임상 시나리오로 구성됩니다. 학습자는 조치를 위한 여러 대안 중에서 선택해야 하며, 사례를 계속 진행하면서 그러한 조치의 결과(예: 심전도[ECG] 결과)가 제공됩니다.
- Patient management problems (PMPs) consist of context-rich clinical scenarios, where specific resources are available for diagnosis and management.27,28 The learner must select among multiple alternatives for action, and the results of those actions are then provided (e.g., electrocardiogram [ECG] findings) as they continue working through the case.
주요 기능 검사(KFE)에는 임상 의사 결정의 중요한 단계에 초점을 맞춘 2~3개의 질문이 뒤따른다. 주요 특징은 사례별로 다르다(예: 벼락 두통은 지주막하 출혈 진단의 핵심 특징이다).
- Key feature examinations (KFEs) contain clinical vignettes followed by two to three questions focused on the critical steps in clinical decision making.29,30 Key features are case specific (e.g., a thunderclap headache is a key feature in the diagnosis of subarachnoid hemorrhage).
스크립트 일치 테스트(SCT)는 임상 추론 중에 새로운 정보가 처리되는 방법을 나타내도록 설계된 불확실성과 관련된 짧은 임상 시나리오로 구성된다. 학습자는 일련의 질문에 답해야 합니다(예: X를 고려하고 있었는데, Y를 찾은 경우, 이 답은 가능성이 더 높아지거나 가능성이 낮아지거나 변경되지 않습니다). 응답은 "전문가"의 참조 패널에서 얻은 응답과 비교되며, 이는 임상 상황에 따라 임상의의 응답의 가변성을 설명한다.
- Script concordance tests (SCTs) comprise short clinical scenarios associated with uncertainty that are designed to represent the way new information is processed during clinical reasoning.31,32 Learners must answer a series of questions (e.g., if you were thinking X and then you found Y, this answer would become more likely, less likely, or no change). Responses are compared with those acquired from a reference panel of “experts,” accounting for the variability of clinicians’ responses in different clinical situations.
CIP는 그리드 형태를 취하며, 종종 확장된 매칭 크로스워드 퍼즐과 유사합니다. 많은 발견이 컬럼(예: 이력, 물리, 심전도, 실험실, 병태생리학, 약리학)에 배치되고 관련 진단은 행에 배치된다(예: 심근경색, 폐색전증, 대동맥 박리). 학습자는 열 내 항목과 행 간 항목(소견에 가장 적합한 "일치" 선택)을 비교 및 대조하여 각 진단에 대한 기본적인 질병 스크립트를 작성하도록 요청받습니다.
- CIPs take the form of a grid, often analogized to an extended matching crossword puzzle.33,34 A number of findings are placed in columns (e.g., history, physical, ECG, labs, pathophysiology, pharmacology), and related diagnoses are placed in rows (e.g., myocardial infarction, pulmonary embolism, aortic dissection). The learner is asked to compare and contrast items within a column as well as across the rows (selecting the best “match” for the finding), building basic illness scripts for each diagnosis.
개념 지도는 학습자가 그래픽 일러스트를 작성함으로써 영역에 대한 지식 및 지식의 구성을 나타내는 개략적인 평가 방법입니다. 맵은 자유 형식 또는 위계형일 수 있으며, 개념과 개념 간의 관계를 모두 나타냅니다.
- Concept maps are a schematic assessment method wherein learners represent their knowledge of a domain, as well as the organization of that knowledge, by creating a graphical illustration.35,36 Maps may be free-form or hierarchical, outlining both concepts and the relationships between the concepts.
구술시험은 한 명 이상의 교직원이 임상적 추론 및 의사결정 능력 및 직업적 가치를 평가하기 위해, 대본이 없거나 반대본semiscripted 방식으로 실시하는 구두평가입니다.
- Oral examinations are verbal assessments conducted by one or more faculty member in either an unscripted or semiscripted fashion to assess clinical reasoning and decision-making abilities, as well as professional values.37,38
영상, 비디오 및 기타 형식은 서면 시험 자료를 보완하거나 보완하는 데 사용될 수 있지만, 대부분의 비 WBA는 [서면] 임상 실험 자료, 또는 [시나리오]를 [자극]으로 사용한다. 비 WBA 방법 중 하나만 언어 자극(구강 검사)을 사용합니다.
The majority of non-WBAs use written clinical vignettes or scenarios as the stimuli, though images, videos, and other formats may be used to supplement or complement the written testing materials. Only one non-WBA method uses a verbal stimulus (oral examinations).
[응답 형식]은 주로 '쓰기written'이지만, 유형(예: 선택된 답변, 구성된 자유 텍스트)은 다양합니다.
The response formats are predominately written, though there is variability in type (e.g., selected answers, constructed free text).
[스코어링 프로세스]는 다양합니다. [단일 정답, 합계 방식]이 일반적입니다(MCQ, EMQ, PMP, KFE 등). 채점은 가중치 부여(즉, 특정 항목이 다른 항목보다 많이 반영됨) 또는 가중치 부여되지 않음(즉, 모든 항목이 동등하게 계산됨), 보상적(즉, 일부 백분율을 틀리고도 합격할 수 있음) 또는 비보상적(즉, 합격하려면 100% 점수가 필요함)될 수 있다. 문항별 채점 또는 전반적 등급 척도는 [단문형 또는 장문형 주관식 응답 및 MEQ]에 사용되며, [규범-기준 또는 준거-기준]으로 채점할 수 있다. CIP 그리드 및 컨셉 맵에는 보다 복잡한 스코어링 시스템이 있습니다. SCT 응답은 "골드 스탠다드"(즉, 전문가 패널의 응답)와 적합성을 비교하여, 그 응답을 선택한 전문가 패널의 비율에 따라 각 항목에 대해 부분적 또는 완전한 점수를 받는다.
Scoring processes vary. Aggregated, fixed-answer responses are common (e.g., MCQs, EMQs, PMPs, KFEs). Scoring can be weighted (i.e., certain items count more than others) or unweighted (i.e., all items count equally) and compensatory (i.e., can get some percentage wrong and still pass) or noncompensatory (i.e., a score of 100% is required to pass). Itemized and global rating scales are used for short- or long-answer constructed free-text responses and MEQs, and they can be norm- or criterion-referenced. CIP grids and concept maps have more complex scoring systems. SCT responses are compared for fit to a “gold standard” (i.e., the expert panel’s responses), and the examinee receives partial to full credit for each item depending on the proportion of the expert panel that chose that response.
중부담 및 고부담 시험에서는 여러 가지 비 WBA 방법이 사용된다(예: MCQ와 KFE는 종합 과정 종료 평가 및 의료 면허 검사에 일반적으로 사용된다). 다른 방법(예: CIP, 개념도)은 충분히 조사되지 않았으며 현재 형성적 평가 또는 연구에 가장 적합하다.
Several non-WBA methods are used for medium- to high-stakes examinations (e.g., MCQs and KFEs are commonly used for summative end-of-course assessments and medical licensing examinations). Other methods (e.g., CIPs, concept maps) are less well explored and are currently most suitable for formative assessments or research.
타당성 고려사항, 실현가능성 문제, 장점 및 단점은 각 방법마다 매우 고유하다. 보충 디지털 부록 4에서는 이러한 차이점에 대해 자세히 설명하지만, WBA 이외를 위한 몇 가지 테마는 여기에서 언급됩니다.
- MCQ, EMQ 및 KFE는 가장 자주 사용되는 비WBA이며, 맥락 특이성을 최소화하는 광범위한 샘플링의 이점을 가지고 있습니다.
- 이러한 방법은 높은 내적 일관성을 제공할 수 있는 최고의 기회를 제공하므로, 고부담 평가에 가장 큰 효용성이 있습니다.
- 전문가 합의 및 블루프린트 덕분에 이러한 방법은 내용 타당성 증거가 강력할 수 있습니다. 이러한 방법은 내용의 통제와 일관성이라는 이점도 있으며, 각 문제에 대한 "정답"이 있다. "정답"이 있다는 것은 WBA에서 항상 가능한 것은 아닙니다.
Validity considerations, feasibility issues, advantages, and disadvantages are highly specific to each method. Supplemental Digital Appendix 4 (at https://links.lww.com/ACADMED/A634) details these differences, but a few themes for non-WBAs warrant mention here.
- MCQs, EMQs, and KFEs are the most frequently used non-WBAs, and they have the advantage of broad sampling that helps minimize context specificity.
- They offer the best chance of high internal consistency and thus have the greatest utility for high-stakes assessments.
- Content validity evidence for these methods can be strong because of expert consensus and blueprinting. These methods also offer the advantage of content control and consistency; there is a “right” answer to each problem, a feature not always possible in WBAs, which allows a measurement of accuracy.
또한, 모든 비 WBA 방법은 표준화된 일련의 문제에 걸쳐 학생을 평가할 수 있습니다. 이는 WBA에서는 불가능한 것입니다. 비 WBA 방법에 대한 가장 큰 타당성 문제는 [응답 프로세스 증거]에 있다. 많은 가능성에서 정답을 선택하거나 지식 조직의 그래픽 표현을 개발하거나 사전 정의된 목록에서 정보를 선택하는 것은 일반적으로 실제 임상 추론 활동을 대표하지 않습니다. 이러한 방법의 대부분은 [전체 태스크 평가]보다 [파트 태스크 평가]에 중점을 두고 있습니다.
(즉, WBA 방법보다 임상 추론의 구성 요소를 더 적게 측정한다. 그림 1 참조).
Further, all non-WBA methods allow students to be assessed across a standardized set of problems, something that is not possible in the workplace. The greatest validity challenge for non-WBA methods is in response process evidence. Selecting a correct answer from a number of possibilities, developing a graphic representation of knowledge organization, or even selecting information from a predefined list are not generally representative of authentic clinical reasoning activities in practice. Many of these methods emphasize part-task, rather than whole-task assessment (i.e., they measure fewer components of clinical reasoning than WBA methods; see Chart 1).
부분 과제 평가는 임상 실습으로 기술을 성공적으로 이전할 수 없기 때문에 임상 추론 역량을 결정하기 위해 비 WBA에 크게 의존하는 [방어가능성]에 의문이 있다. 이러한 방법 중 일부는 [내부 구조 증거]뿐만 아니라 [다른 변수와의 관계에 대한 증거]를 광범위하게 가지고 있지만, 다른 방법은 이러한 형태의 타당성 증거가 부족하다. 비 WBA는 [종종 면허, 인증 및 자격 증명 결정뿐만 아니라 총괄적 합격 또는 불합격 판단]을 내리는 데 사용되기 때문에 임상 실무 성과에 대한 결과 또는 결과는 중요하다. 학습에 대한 형성 평가는 비 WBA가 진행 테스트 및 임상 추론의 개발에 미치는 영향을 위해 사용될 때 발생할 수 있다(예: 인지 네트워크 개발에 도움이 되는 개념도 사용).
The defensibility of relying heavily on non-WBAs to determine clinical reasoning competence is questionable because part-task assessments cannot ensure successful transfer of skills into clinical practice. Several of these methods have extensive evidence of their relationship to other variables, as well as internal structure evidence, but others lack these forms of validity evidence. Consequences or outcomes on clinical practice performance are significant because non-WBAs are often used to make summative pass or fail judgments as well as licensing, certification, and credentialing decisions. Formative assessment for learning can occur when non-WBAs are used as progress tests and for the effect they have on the development of clinical reasoning (e.g., using concept maps to help develop cognitive networks).
시뮬레이션된 임상 환경에서의 평가
Assessments in simulated clinical environments
시뮬레이션된 임상 환경에서 발생하는 두 가지 방법이 확인되었다.
Two methods were identified that occur in simulated clinical environments.
객관적 구조화 임상검사(OSCE)는 임상추론을 포함하여 학생의 임상능력에 대한 성과 기반 평가입니다. OSCE는 종합 평가를 제공하기 위해 SP, 관찰자 등급, 서면 노트 및 기타 방법을 포함하는 다양한 임상 태스크를 수험자가 실행하는 여러 스테이션으로 구성됩니다.
- Objective structured clinical examinations (OSCEs) are performance-based evaluations of students’ clinical skills including, but not exclusively focused on, clinical reasoning.39,40 OSCEs comprise multiple stations where examinees execute different clinical tasks, incorporating SPs, observer ratings, written notes, and other methods, to provide a comprehensive assessment.
기술 강화 시뮬레이션은 학습자가 임상 치료를 모방하는 도구 또는 장치와 물리적으로 상호작용하는 다양한 평가 방법을 설명합니다. 여기에는 학습자 입력에 따라 변경될 수 있는 정적 고충실도 마네킹에서 가상 현실 환자 아바타까지 다양한 계측기가 포함될 수 있습니다.
- Technology-enhanced simulation describes a variety of assessment methods wherein learners physically interact with a tool or device that mimics clinical care.41,42 These can encompass a range of instruments from static high-fidelity mannequins to virtual reality patient avatars that can change in response to learner input.
- 시뮬레이션 임상 환경에서 평가는 일반적으로 SP, 고충실도 마네킹 또는 가상 환자 아바타를 [자극]으로 사용한다.
- OSCE 및 기술 강화 시뮬레이션의 [응답 형식]은 일반적으로 작업 수행 또는 구성된 구두 또는 서면 응답입니다.
- [채점]은 종종 이분법적(즉, 완료 여부) 또는 행동적으로 고정된 항목별 체크리스트를 통해 이루어집니다. 글로벌 평가 척도가 흔하다.
- [용도]를 보면, OSCE는 형성적 평가와 높은 단계의 종합 평가에 모두 사용됩니다. (예: 미국 의료 면허 시험 2단계 임상 기술 및 캐나다 의료 위원회 자격 시험 파트 2) 반면 기술 혁신 시뮬레이션은 주로 조형 평가에 사용된다.
- Assessments in simulated clinical environments typically use SPs, high-fidelity mannequins, or virtual patient avatars as stimuli.
- The response format for OSCEs and technology-enhanced simulations is usually task performance or constructed verbal or written responses.
- Scoring is often via itemized checklists that may be dichotomous (i.e., done or not done) or behaviorally anchored. Global rating scales are also common.
- OSCEs are used for both formative and high-stakes summative assessments (e.g., the United States Medical Licensing Examination Step 2 Clinical Skills and the Medical Council of Canada’s Qualifying Examination Part 2), whereas technology-enhanced simulations are mainly used for formative assessments.
타당성 고려 사항, 실현 가능성 문제, 장점 및 단점은 보충 디지털 부록 4에 자세히 설명되어 있지만, 몇 가지 주제는 강조되어야 합니다. [내용 타당성] 측면에서 이러한 방법을 블루프린트 할 수 있으며, 이럴 경우 임상 실무와의 연계가 합리적이다(이러한 평가의 authenticity는 대부분의 비 WBA보다는 높지만, 실제 WBA보다는 낮다). 고도로 구성되고 표준화된 재현 가능한 스테이션은 SP 및 평가자 교육에 주의를 기울여야 합니다. 이러한 표준화된 환경에서는 실제 임상 실습 중에 발생하는 평가보다 [맥락적 요인을 제어할 수 있는 능력]이 더 크다. 평가의 블루프린트는 내용특이성을 고려하여 합격에 필요한 필수적 기능feature을 식별해야 합니다(글로벌 평가 척도의 명확한 앵커 포함). 다른 평가 척도(즉, 비 WBA 및/또는 WBA)와의 성과 상관관계는 낮은 수준부터 중간 수준까지이며, 이는 형성 평가에는 허용되지만 높은 단계의 최종 결정에는 바람직하지 않다. 시뮬레이션 환경에서 평가는 여러 임상 추론 구성 요소를 측정하는 능력(그림 1)으로 평가되지만, 실제적인 주요 문제는 [개발 및 관리]가 자원 집약적이라는 것이다.
Validity considerations, feasibility issues, advantages, and disadvantages are detailed in Supplemental Digital Appendix 4 (at https://links.lww.com/ACADMED/A634), but a few themes warrant highlighting. In terms of content validity, these methods can be blueprinted, and their alignment with clinical practice is reasonable (higher than most non-WBAs, yet less authentic than true WBAs). Highly organized, standardized, reproducible stations require attention to SP and rater training. There is greater ability to control contextual factors in these standardized environments than in assessments that occur during actual clinical practice. Blueprinting for these assessments must attend to content specificity and distinguish what essential features are required to pass (with clear anchors for global rating scales). Performance correlations with other assessment measures (i.e., non-WBAs and/or WBAs) are only low to moderate, which is acceptable for formative assessments but is less than desirable for high-stakes summative decisions. Assessments in simulated environments are valued for their ability to measure multiple clinical reasoning components (Chart 1), but a major practical problem is that they are resource-intensive to both develop and administer.
WBA
WBAs
인증된 임상 환경 또는 WBA의 평가에 초점을 맞춘 7가지 방법이 확인되었다.
Seven methods were identified that focus on assessments in authentic clinical environments or WBAs.
직접 관찰(direct observation)은 성능 또는 임상 관찰이라고도 하며, 실제 임상 상황에서 학습자에 대한 데이터를 수집하는 관찰자(일반적으로 교수진)의 존재를 나타냅니다. 다양한 평가 도구가 직접 관찰을 위해 사용되었지만(예: 미니 임상 평가 연습[mini-CEX]) 임상 추론을 평가하도록 명시적으로 설계된 것은 아니다.
- Direct observation, also known as performance or clinical observation, describes the presence of an observer (typically a faculty member) who collects data about learners in authentic clinical contexts.43 A variety of assessment tools have been used for direct observation43 (e.g., the mini-clinical evaluation exercise [mini-CEX]),44 though they are not all explicitly designed to assess clinical reasoning.
글로벌 평가는 교직원 평가 양식의 공통 컴포넌트입니다. 직접 또는 간접 관찰에 기초한 임상 추론 성과에 대한 개별 판단 또는 게슈탈트 교사를 포착합니다.
- Global assessments are common components of faculty evaluation forms.45,46 They capture individual judgments or preceptor gestalt about clinical reasoning performance based on direct or indirect observations.
OCP는 임상 사례에 대한 체계적인 구두 보고입니다. 학습자가 무엇을 포함하거나 제외할 것인지, 데이터 구성, 평가와 계획의 구조와 내용에 대해 신중하게 선택할 때 학습자의 진단 및 치료 추론의 증거가 평가된다. 평가자는 학습자의 이해와 추가 정보를 탐색할 수 있습니다.
- OCPs are structured verbal reports of clinical cases.47,48 Evidence of a learner’s diagnostic and therapeutic reasoning is assessed as the learner makes deliberate choices about what to include or exclude, data organization, and the structure and content of the assessment and plan. Raters can probe learners for understanding and additional information.
서면 메모는 사례에 대한 임상 정보를 체계적인 방식으로 전달하는 또 다른 수단이다. 이 경우 서면 보고서를 통해. 다양한 도구 중 하나(예: 사후 메모, IDEA[해석 요약, 차등 진단, 추론 설명 및 대안] 평가 도구51)를 사용하여 평가할 수 있다. OCP와 마찬가지로 임상 추론은 메모의 여러 특징, 특히 요약문(주요 특징과 의미 한정자를 포함하는 사례의 캡슐화), 문제 목록, 차등 진단의 우선순위 부여, 정당성 및 관리 계획에서 평가할 수 있다.
- Written notes are another means of communicating clinical information about a case in a structured way—in this case, via a written report.49 They may be assessed by using one of a variety of tools (e.g., postencounter notes,50 the IDEA [interpretive summary, differential diagnosis, explanation of reasoning, and alternatives] assessment tool51). Similar to OCPs, clinical reasoning may be assessed from multiple features of a note, particularly the summary statement (an encapsulation of the case containing key features and semantic qualifiers), problem list, prioritization of the differential diagnosis, justification, and management plan.
CSR은 실제 임상 조우로부터의 [임상 문서 검토], 평가자가 근본적인 사고 과정을 조사하는 [구두 검사], 향후 진단 의사 결정을 개선하기 위한 [행동 계획]을 포함한 [피드백]으로 구성된 하이브리드 형식입니다.
- CSR is a hybrid format consisting of clinical documentation review from an actual clinical encounter, an oral examination where an evaluator probes underlying thought processes, and feedback that may include action plans to improve future diagnostic decision making.52,53
Think aloud(TA)는 학습자에게 개별 과제를 부여하고 작업을 수행하는 동안 자신이 가졌거나 가졌던 여과되지 않은 생각을 음성으로 표현하도록 하는 기술입니다. TA는 일반적으로 작업을 완료하는 동안(동시) 관리되지만, 작업 완료 직후(지연) 수행될 수도 있습니다.
- Think aloud (TA) is a technique where learners are given a discrete task and asked to voice the unfiltered thoughts they have or had while performing the work.54,55 TAs are typically administered while completing the task (simultaneous) but may also be performed immediately following task completion (delayed).
SRL-M은 학습자가 [시작, 중간, 끝이 있는 임상 활동]에 [접근, 수행, 성찰]할 때, 학습자의 [생각, 행동, 느낌]에 대한 즉각적인 [태스크 수준 정보를 수집]하도록 설계된, [구조화된 인터뷰 프로토콜]이다. TA의 특징과 조합하여 메타인식을 평가할 수 있습니다.
- SRL-M describes a structured interview protocol designed to gather in-the-moment, task-level information about learners’ thoughts, actions, and feelings as they approach, perform, and reflect on a clinical activity that has a beginning, middle, and end.56,57 Combined with features of the TA, it can assess metacognition.
WBA 방법은 실제 환자를 [자극]으로 의존한다. 이러한 방법의 [응답 형식]에는 환자와의 임상 성과(직접 관찰, 글로벌 평가) 또는 작성된 구두 또는 서면 자유 텍스트(OCP, 서면 노트, CSR, TA, SRL-M)가 포함된다. [채점] 메커니즘은 매우 다양하며 다양한 유형의 항목별 또는 글로벌 등급 척도를 포함한다 (표준 참조, 기준 참조, 위탁 척도, 감독 척도), 체크리스트 등. WBA는 임상 사무직 및 레지던트 기간 동안 형성 평가에 가장 일반적으로 [사용]됩니다. 이러한 정보를 총괄적 의사결정에 사용할 경우, 일반적으로 [다수의 관측값 또는 글로벌 평가]를 합산한다. 일반적으로 사용되는 WBA는 [형성 평가에 사용되는 직접 관찰(예: 미니 CEX)]과 [임상 사무직 및 레지던트 로테이션 종료 총괄 평가에 사용되는 글로벌 평가]이다. 구두 발표와 서면 메모는 교수진의 최종 글로벌 평가에 영향을 미칠 수 있지만 고부담 평가에는 거의 사용되지 않습니다. TA와 SRL-M은 일반적으로 연구 맥락에 더 많이 관여하지만 어려움을 겪고 있는 학습자의 교정조치에 사용되어 왔다.
WBA methods rely on real patients as stimuli. Response formats for these methods include clinical performance with patients (direct observation, global assessment) or constructed verbal or written free text (OCPs, written notes, CSR, TA, SRL-M). Scoring mechanisms vary widely and include itemized or global rating scales of various types (norm referenced, criterion referenced, entrustment scales, supervision scales), as well as checklists, etc. WBAs are most commonly used for formative assessment during clinical clerkships and residency. When they are used to make summative decisions, multiple observations or global assessments are typically aggregated. The workhorses of WBAs are direct observation (e.g., mini-CEX), which is typically used for formative assessments; and global assessments, which are typically used for end-of-rotation summative assessments during clinical clerkships and residency rotations. Oral presentations and written notes may influence a faculty rater’s final global assessment but are infrequently used for high-stakes assessments. TA and SRL-M are typically more involved in research contexts but have been used for the remediation of struggling learners.58,59
WBA 방법의 타당성 고려 사항, 실현 가능성 문제, 장점 및 단점에 대한 자세한 내용은 보충 디지털 부록 4에 요약되어 있지만, 여기서는 몇 가지 주제를 강조합니다. WBA의 큰 강점은 [임상 추론의 여러 구성 요소를 측정하는 능력]이다(그림 1). 이러한 방법은 실제 임상 환경에서 이뤄지므로 [내용 타당도 증거]와 [응답 프로세스 타당성 증거]가 합당하다. 그러나 임상 실무의 비체계적 성격은 [특정 임상 문제의 내용 적용 범위와 과다 또는 과소 표현]과 관련하여 문제를 제기할 수 있다. [내부 구조 증거(예: 항목 분석 데이터, 점수 척도 신뢰성, 표준 측정 오류)]는 이러한 방법 중 많은 수가 복잡한 행동의 관찰을 소수의 평가 결과로 정량화할 관찰자(시설 구성원)를 필요로 한다는 점에서 문제가 있다. 판단 과정에 편견과 불일치가 내재되어 있다. 이러한 타당도 위협을 줄이기 위한 핵심 전략은 [여러 평가자에 의한 다양한 임상 문제 집합에 대한 적절한 수의 관찰을 시간 경과에 따라 보장하는 것]이다. 일반화 이론의 관점에서 판단을 위해 허용 가능한 신뢰성에 도달하기 위해 12 - 14개의 미니 CEX가 필요하기 때문에, 이 정도가 되지 않는다면 WBAs를 사용하는 방어가능성에 의문이 있다. WBA의 도입에는 시간, 교수개발, 책무성, 평가에 참여하는 교수에 대한 인정 등이 과제가 되고 있습니다. 이는 임상환경이 [수련생의 감독이나 평가]보다 [생산성]을 중시하는 경우가 많기 때문입니다.
The details of validity considerations, feasibility issues, advantages, and disadvantages of WBA methods are summarized in Supplemental Digital Appendix 4 (at https://links.lww.com/ACADMED/A634), but we will highlight a few themes here. A great strength of WBAs is their ability to measure multiple components of clinical reasoning (Chart 1). Because these methods are embedded in authentic clinical environments, there is reasonable content and response process validity evidence. The nonsystematic nature of clinical practice, however, can present challenges with regard to content coverage and over- or underrepresentation of certain clinical problems. Internal structure evidence (e.g., item analysis data, score scale reliability, standard errors of measurement) is problematic in that many of these methods require an observer (faculty member) to quantify their observation of a complex behavior into a small number of assessment outcomes. Biases and inconsistencies are inherent in this judgment process.60–62 A key strategy to reduce these threats to validity is to ensure an adequate number of observations across a diverse set of clinical problems by multiple raters over time. The defensibility of using WBAs for summative pass/fail and remediation decisions is questionable without this because, from a generalizability theory perspective, 12 to 14 mini-CEXs are needed to reach acceptable reliability for judgments. Challenges to implementing WBAs include time, faculty development, accountability, and recognition for faculty who engage in these assessments, as clinical environments often value productivity over the supervision and evaluation of trainees.

논의
Discussion
이 검토는 현재 이용 가능한 임상 추론 평가 방법의 메뉴를 요약하고 타당성 고려사항, 타당성 문제, 장점 및 단점을 각각 강조한다. 특히 차트 1과 보충 디지털 부록 4는 평가 프로그램의 구축에 도움이 됩니다. 교육자는 각기 다른 타당성 고려사항을 가진 서로 다르지만 상호 보완적인 여러 임상 추론 평가 방법 중에서 선택할 수 있다. 조사 결과에 근거한 실용적인 가이던스는 리스트 1에 기재되어 있습니다.
This review summarizes the currently available menu of clinical reasoning assessment methods and highlights validity considerations, feasibility issues, advantages, and disadvantages for each. Chart 1 and Supplemental Digital Appendix 4 (at https://links.lww.com/ACADMED/A634) in particular can help inform the construction of programs of assessment.63 Educators can select from a number of different but complementary clinical reasoning assessment methods, each with different validity considerations. Practical guidance based on our findings is given in List 1.
임상 추론 평가 방법의 기존 메뉴의 가치는 역량 기반 교육의 렌즈를 통해 가장 잘 이해할 수 있다. 의학 교육자가 학습자가 임상 추론의 역량을 ensure하려면 임상 추론의 모든 구성요소에 대한 강력한 평가를 제공해야 한다12(표 1 참조). 또한 적절한 샘플링을 준비해야 한다. 이는 여러 평가 방법을 사용해야만 달성할 수 있습니다.
The value of the existing menu of clinical reasoning assessment methods can perhaps best be understood through the lens of competency-based education. If medical educators want to ensure that learners are competent in clinical reasoning, they must provide robust assessment of all components of clinical reasoning12 (see Table 1). Further, they must also arrange for adequate sampling. This can only be accomplished by employing multiple assessment methods.63
차트 1을 자세히 살펴보면 일반적으로 사용되는 [많은 형태(MCQ, EMQ, KFE, SCT)의 비 WBA]는 [정보 수집, 가설 생성 및 문제 표현 평가]에서 [평균에 불과하다]는 것을 알 수 있습니다. 이들의 강점은 감별 진단 평가, 선도 진단, 관리 및 치료에 있습니다. 시뮬레이션된 임상 환경과 WBA에서의 평가는 정보 수집을 평가하는 데 더 우수하며, 직접 관찰과 OSCE가 이 영역에서 가장 강력하다. SRL-M 및 TA 전략은 학습자가 추론 과정에서 숨겨진 이러한 단계를 명확하게 설명하도록 하기 때문에 가설 생성 및 문제 표현을 측정하기 위한 효과적인 도구입니다. 교육자는 임상 추론의 다양한 구성요소를 평가하는 데 강한 전략을 신중하게 조합함으로써(예를 들어 MCQ + SRL-M + OSCE) 더 큰 역량의 모든 구성요소에 대한 평가를 확실하게 시작할 수 있습니다.
A close look at Chart 1 demonstrates that many forms of non-WBAs in common use (MCQs, EMQs, KFEs, SCTs) are only poor to average at assessing information gathering, hypothesis generation, and problem representation. Their strengths lie more in assessing differential diagnosis, leading diagnosis, and management and treatment. Assessments in simulated clinical environments and WBAs are better at assessing information gathering, with direct observation and OSCEs being the strongest in this domain. SRL-M and TA strategies are effective tools for measuring hypothesis generation and problem representation because they force learners to articulate these otherwise hidden steps in the reasoning process.64 By carefully combining strategies that are strong at assessing the different components of clinical reasoning (e.g., MCQs + SRL-M + OSCEs), educators can begin to ensure assessment of all components of the larger competency.
물론 "전체"로서의 임상적 추론 능력은 "부분"의 합보다 더 크다. 평가 프로그램을 구성할 때 [임상 추론의 모든 구성 요소를 평가하는 것]은 필요하지만 충분하지는 않다. 학습자가 기술을 임상 실습으로 이전할 수 있도록 보장하기 위해 전체 작업 평가(즉, 전체 임상 추론을 다루는 평가)가 필요하며, 광범위한 표본 추출을 위해 부분 작업 평가가 필요하다. 전체 및 파트 태스크 평가(예: 직접 관찰, OSCE 및 MCQ, KFE 및 EMQ와 결합된 글로벌 평가)의 조합은 평가 프로그램의 기초를 형성할 수 있다.
Of course, clinical reasoning competence as a “whole” is more than the sum of its “parts.”65 When constructing an assessment program, it is necessary, but not sufficient, to ensure assessment of all components of clinical reasoning. Whole-task assessments (i.e., those that cover the full range of clinical reasoning) are needed to ensure that learners can transfer skills into clinical practice,66 while part-task assessments are needed to achieve broad sampling. Combinations of whole- and part-task assessments (e.g., direct observations, OSCEs, and global assessments combined with MCQs, KFEs, and EMQs) can form a foundation for a program of assessment.
교육자는 또한 방법 중에서 선택할 때 평가의 [타당성, 사용가능성, 방어가능성]을 고려해야 합니다. 차트 1을 보면, 평가자가 주로 WBA를 사용하는 경우, 실제 임상 환경에서 임상 추론의 모든 구성 요소에 대한 강력한 적용 범위를 확보하고 학습자가 유능하다고 쉽게 간주할 수 있다고 결론지을 수 있다. WBA는 매우 중요하며 현재의 역량 기반 교육 프로그램에서 더욱 강조할 가치가 있지만, 실현 가능성과 비용(교직원의 시간과 비용에 관한)이 종종 [표본으로 삼을 수 있는 사례의 수와 다양성을 제한]하기 때문에, 임상 추론을 평가하기 위하여 배타적으로 WBA만 사용하게 되면 내용특이성과 맥락특이성에 의해 제약을 받을 것이다. 이러한 관점에서 볼 때, 비 WBA(예: MCQ, EMQ, KFE)를 활용하여 맥락특이성의 문제를 줄이고, [블루프린트, 통제, 일관성 및 정확성]을 확보하는 동시에, 광범위한 표본을 확보함으로써, 임상 추론 평가 프로그램에 중요한 가치를 더할 수 있다. 따라서 타당성과 실현가능성을 모두 고려한다면, 모든 평가 프로그램에서는 [비 WBA, 시뮬레이션 환경의 평가, WBA의 균형]을 유지하는 것이 중요하다.
Educators must also consider the validity, feasibility, and defensibility of assessments when choosing among methods. Looking at Chart 1, one might conclude that if assessors predominately used WBAs, they would obtain robust coverage of all components of clinical reasoning in authentic clinical environments and easily be able to deem a learner competent. Although WBAs are critically important and deserve greater emphasis in current competency-based educational programs,67,68 the limitations of an exclusively WBA approach to assessing clinical reasoning rest in the problem of content and context specificity because feasibility and cost (with regard to faculty time and money) often limit the number and variety of cases that can be sampled. Seen in this light, non-WBAs (e.g., MCQs, EMQs, KFEs) add important value to a program of clinical reasoning assessment by ensuring broad sampling, while lessening issues of context specificity and providing opportunities for blueprinting, control, consistency, and accuracy. Thus, for validity and feasibility reasons, it is critical to have a balance of non-WBAs, assessments in simulated clinical environments, and WBAs in any assessment program.
이러한 균형을 잡는 것이 교육적 맥락에 따라 어려울 수 있습니다. 예를 들어,
- [학부 의학교육 프로그램]은 종종 MCQ, OSCE, 글로벌 평가, 구두 발표 및 서면 메모의 조합을 사용하여 추론을 평가합니다. 이러한 프로그램은 [직접 관찰]과 같은 특정 방법의 사용을 개선하는 동시에 현재 충분히 평가되지 않을 수 있는 임상 추론의 구성 요소를 얻기 위해 TA 또는 SRL-M과 같은 새로운 방법을 통합하기를 원할 수 있다.
- [졸업후 의학 교육]에서 학습과 평가의 대부분은 임상 환경에서 이루어지며, 종종 MCQ로 구성된 기술 강화 시뮬레이션과 훈련 중인 검사를 통해 강화된다. 광범위한 평가 방법을 통합하고, 현재 사용 중인 평가 방법을 개선하며, 바쁜 임상 환경에서 도구에 대한 평가자를 교육하는 것은 쉽지 않을 것입니다.
WBA가 개선되면, 이러한 보다 전체적인holistic 평가가 우세할 수 있으며, 비 WBA는 주로 [불확실성과 재교육 상황]에서 주로 사용될 수 있다. 그러나 이러한 전환을 효과적으로 하기 위해서는 여전히 많은 연구가 필요하다.
Creating such a balance can be challenging depending on the educational context.
- For example, undergraduate medical education programs often use a combination of MCQs, OSCEs, global assessments, oral presentations, and written notes to assess reasoning. These programs may wish to improve the use of certain methods, such as direct observation, while also incorporating novel methods, such as TA or SRL-M to get at components of clinical reasoning that may be currently underassessed.
- In graduate medical education, the bulk of learning and assessment happens in the clinical environment, augmented occasionally by technology-enhanced simulation and in-training examinations, which are largely comprised of MCQs. Incorporating a wider range of assessment methods, improving on assessment methods currently in use, and training raters on tools in busy clinical settings will be daunting.
As WBAs improve, it may be possible that these more holistic assessments can predominate, and non-WBAs can be used largely for situations of uncertainty and remediation; however, much research is still needed to make this transition effectively.
궁극적으로, 기관은 평가 프로그램이 임상 추론의 구성요소에 대한 완전한 적용 범위를 제공하는지 확인해야 한다(표 1과 차트 1). 프로그램은 [전체 태스크 방법]과 [부분 태스크 방법]을 모두 사용할 필요가 있을 뿐만 아니라, [타당성]에 대한 다양한 위협과 관련하여 방법에 대한 균형 잡힌 표현을 제공해야 한다(보조 디지털 부록 4 참조). 임상 추론을 위한 프로그램적 평가는 여전히 많은 기관에서 초기 개념이지만, 이 리뷰는 이 분야가 미래에 이동해야 한다는 것을 시사한다. 의료기관은 임상 추론의 빈번한 평가를 수행하여 여러 출처에서 여러 방법을 사용하여 다양한 맥락 또는 환경에 걸쳐 세로 방향으로 정보를 수집해야 한다. 이는 시간과 교직원 육성의 필요성 때문에 현실에서 어려운 일이지만, 높은 수준의 종합적 결정이나 역량 결정을 내릴 때 평가 프로그램의 방어성에 매우 중요합니다. 또한 환자 안전을 보장하는 것도 중요하다.69 현재 평가 관행이 비 WBA, 시뮬레이션 임상 환경의 평가 및 WBA의 적절한 균형을 이루는지 여부는 논란의 여지가 있지만 이 검토의 범위를 완전히 벗어나 있다.
Ultimately, institutions must ensure that their programs of assessment offer complete coverage of the components of clinical reasoning (Table 1 and Chart 1). Programs will need to use both whole- and part-task methods as well as provide a balanced representation of methods with regard to various threats to validity (see Supplemental Digital Appendix 4 at https://links.lww.com/ACADMED/A634). Programmatic assessment for clinical reasoning is still a nascent concept at many institutions, yet this is where this review suggests the field needs to move in the future. Institutions need to conduct frequent assessments of clinical reasoning, gathering information longitudinally from multiple sources, using multiple methods, across various contexts or settings. This is challenging in the real world because of time and the necessity of faculty development, yet it is critical for the defensibility of an assessment program when making high-stakes summative decisions or competency determinations. It is also critical to ensure patient safety.69 Whether our current assessment practices strike the right balance of non-WBAs, assessments in simulated clinical environments, and WBAs is debatable but beyond the scope of this review to fully address.
우리의 논의는 주로 임상추론역량과 [학습의 평가AoL]에 초점을 맞췄지만, [학습을 위한 평가AfL]를 고려하는 것도 중요하다. 많은 동일한 원칙이 적용되지만, 학습을 위한 평가는 보다 형성적이며, 임상 추론 과정을 학습하고 가르치는 데 높은 가치가 있기 때문에, [다른 범위의 타당성 증거]를 사용할 수 있다(즉, 방법이 목적에 적합해야 한다). 예를 들어, CIP와 개념 지도는 학생들이 질병 스크립트를 개발하고 연결을 형성하도록 돕는다는 점에서 학습에 큰 효용을 가지고 있으며, 진단 전문지식의 기초라고 생각되는 코딩 및 검색 네트워크의 개발을 촉진한다. 직접 관찰 및 기술 강화 시뮬레이션과 같은 전체 작업 임상추론 평가는 다수의 관찰 없이 총괄적 판단을 하는 데 적합하지 않더라도 형성적 피드백을 얻는 데 필수적인 수단이다.
Although our discussion has largely focused on determining clinical reasoning competency and assessment of learning, it is also important to consider assessment for learning. While many of the same principles apply, assessment for learning is more formative and may employ methods that have a different range of validity evidence because of their high value for learning and teaching the clinical reasoning process (i.e., the method is fit for the purpose). For example, CIPs and concept maps have great utility for learning in that they help students develop illness scripts and form connections, facilitating the development of coding and retrieval networks, which are thought to be the basis of diagnostic expertise.70,71 Whole-task clinical reasoning assessments, such as direct observations and technology-enhanced simulations, are essential means of obtaining formative feedback, even if they are not well suited for making summative judgments without large numbers of observations.
의사의 역량으로서의 임상 추론의 중요성은 평가의 엄격함과 혁신을 요구한다. 이 검토는 임상 추론 평가 방법에 상당한 혁신이 있었음을 보여주지만, 아직 해야 할 일이 많이 남아 있다. 우리는 이 집계된 자료가 교육자들이 임상 추론 평가 방법의 기존 메뉴와 그 중에서 선택하는 방법에 대해 더 잘 알 수 있도록 돕기를 바란다. 우리는 이 방법들의 개선을 이끌기 위해 지속적이고 엄격한 타당성 증거 수집의 필요성을 강조한다. 의대, 레지던트 프로그램 및 면허 위원회가 학습자의 역량을 자신 있게 결정할 수 있도록 다양한 방법을 임상 추리 평가의 유효한 프로그램에 가장 잘 결합하는 방법을 결정하기 위한 미래 연구도 필요하다.
The importance of clinical reasoning as a physician competency mandates rigor and innovation in the assessment of it. This review demonstrates that there has been considerable innovation in clinical reasoning assessment methods, but there remains much work to be done. We hope this collated resource will help educators become more aware of the existing menu of clinical reasoning assessment methods and how to choose among them. We emphasize the need for ongoing and rigorous gathering of validity evidence to guide improvements in each of these methods. Future research is also needed to determine how to best combine various methods into valid programs of clinical reasoning assessment to allow medical schools, residency programs, and licensing boards to confidently determine the competence of their learners.
List 1 2016년 임상추론평가방법 범위 검토의 임상추론평가를 위한 실무지침
List 1 Practical Guidance for Clinical Reasoning Assessment From a 2016 Scoping Review of Clinical Reasoning Assessment Methods
- 임상 추론 평가 프로그램의 일부로 다양한 평가 방법(즉, 비 WBA, 시뮬레이션 임상 환경의 평가 및 WBA)을 사용해야 한다.
- Multiple assessment methods (i.e., non-WBAs, assessments in simulated clinical environments, and WBAs) should be used as part of a clinical reasoning assessment program.
- 많은 개별 평가 방법은 적절한 항목 또는 사례의 수, 광범위한 표본 추출 및 충분한 시험 시간으로 높은 단계 평가( 0 >= 0.8)에 대한 적절한 [신뢰성]을 얻을 수 있다.
- Many individual assessment methods can obtain adequate reliability for high-stakes assessment (≥ 0.8) with an adequate number of items or cases, broad sampling, and sufficient testing time.
- 역량을 확신ensure하려면, 내용 및 상황 특이성을 수용하기 위한 다양한 환경에서 다양한 임상 문제를 다루는 많은 평가가 종적으로 필요하다.
- To ensure competence, a large number of assessments are needed, administered longitudinally, that cover a variety of clinical problems in diverse settings to accommodate content and context specificity.
- 평가방법은 임상 추론, 타당성, 실현가능성, 방어가능성, 목적적합성 등 다양한 구성 요소의 적용범위에 기초하여 선택해야 한다.
- Methods should be chosen based on coverage of the different components of clinical reasoning, validity, feasibility, defensibility, and fit for the purpose of the assessment.
- 전체작업평가 및 부분작업평가 방법을 함께 사용하면(즉, 임상 추론의 모든 구성 요소와 일부 구성 요소를 포괄하는 방법)은 전체 구조의 측정과 적절한 표본 추출을 보장할 수 있다.
- Whole- and part-task assessment methods (i.e., those that cover all versus a few components of clinical reasoning) used together can ensure measurement of the whole construct and adequate sampling.
- 비 WBA(예: MCQ, EMQ, KFE)는 광범위한 샘플링, 블루프린팅, 통제, 일관성이라는 장점이 있다. 정확성도 평가할 수 있습니다.
- Non-WBAs (e.g., MCQs, EMQs, KFEs) have the advantage of broad sampling, blueprinting, control, and consistency. They can also assess accuracy.
- MCQ와 KFE는 [내용, 내부 구조, 임상 수행능력에 대한 성과 또는 후과]에 관한 최선의 타당성 증거를 가지고 있다. 그러나 [응답 프로세스]에 관한 경우, 그들은 중요한 문제를 안고 있다.
- MCQs and KFEs have the best validity evidence regarding content, internal structure, and consequences or outcomes on clinical practice performance; however, they have significant issues with cueing when it comes to response process.
- [비 WBA]는 [전체 과제를 더 많이 측정하는 경향이 있는 시뮬레이션과 WBA]에 비해, 임상 추론의 구성요소의 수가 더 제한적이다.
- Non-WBAs measure a more limited number of components of clinical reasoning compared with simulations and WBAs, which tend to measure more of the whole task.
- WBA는 실제 임상 프랙티스에 포함되기에, [내용 및 응답 프로세스의 타당성]에 대한 신뢰성을 제공합니다.단, 내용 커버리지가 체계적이지 않습니다.
- WBAs are embedded in actual clinical practice, lending authenticity to content and response process validity; however, content coverage is not systematic.
- 일반화 이론의 관점에서 판단의 허용 가능한 신뢰성에 도달하기 위해서는 다수의 측정이 필요하기 때문에 요약 의사결정에 WBA를 사용하는 것의 방어가능성은 의문을 갖게 만들 수 있다. WBA의 경우 [장기간에 걸쳐 복수의 평가자에 의한 평가]가 필수적입니다.
- The defensibility of using WBAs for summative decisions is questionable because, from a generalizability theory perspective, a large number of measurements are needed to reach acceptable reliability for judgments. Ensuring evaluation by multiple raters over time is also essential for WBAs.
- [전체 과제 임상 추론 평가](즉, 정보 수집에서 차등 진단, 관리 및 치료까지 모든 작업을 포괄하는 평가)는 형성적 피드백과 학습을 위한 평가에 필수적이다.
- Whole-task clinical reasoning assessments (i.e., those that cover the full range of tasks from information gathering to differential diagnosis to management and treatment) are essential for formative feedback and assessment for learning.
- [시뮬레이션된 임상 환경과 WBA의 평가]는 학습자가 개발 및 관리에 시간과 자원이 많이 소요되지만 전체 과제에 대해 평가되도록 하기 때문에 모든 포괄적인 평가 전략의 필수적인 부분이다.
- Assessments in simulated clinical environments and WBAs are essential parts of any comprehensive assessment strategy because they ensure that learners are assessed on the whole task, though they are time- and resource-intensive to develop and administer.
Abbreviations: WBAs indicates workplace-based assessments; MCQs, multiple-choice questions; EMQs, extended matching questions; KFEs, key feature examinations.
Acad Med. 2019 Jun;94(6):902-912. doi: 10.1097/ACM.0000000000002618.
Clinical Reasoning Assessment Methods: A Scoping Review and Practical Guidance
PMID: 30720527
Abstract
Purpose: An evidence-based approach to assessment is critical for ensuring the development of clinical reasoning (CR) competence. The wide array of CR assessment methods creates challenges for selecting assessments fit for the purpose; thus, a synthesis of the current evidence is needed to guide practice. A scoping review was performed to explore the existing menu of CR assessments.
Method: Multiple databases were searched from their inception to 2016 following PRISMA guidelines. Articles of all study design types were included if they studied a CR assessment method. The articles were sorted by assessment methods and reviewed by pairs of authors. Extracted data were used to construct descriptive appendixes, summarizing each method, including common stimuli, response formats, scoring, typical uses, validity considerations, feasibility issues, advantages, and disadvantages.
Results: A total of 377 articles were included in the final synthesis. The articles broadly fell into three categories: non-workplace-based assessments (e.g., multiple-choice questions, extended matching questions, key feature examinations, script concordance tests); assessments in simulated clinical environments (objective structured clinical examinations and technology-enhanced simulation); and workplace-based assessments (e.g., direct observations, global assessments, oral case presentations, written notes). Validity considerations, feasibility issues, advantages, and disadvantages differed by method.
Conclusions: There are numerous assessment methods that align with different components of the complex construct of CR. Ensuring competency requires the development of programs of assessment that address all components of CR. Such programs are ideally constructed of complementary assessment methods to account for each method's validity and feasibility issues, advantages, and disadvantages.
'Articles (Medical Education) > 평가법 (Portfolio 등)' 카테고리의 다른 글
| 목적적 표본에서 신호를 추론하기: 역량 평가에서 맥락의 역할(Med Educ, 2022) (0) | 2022.04.23 |
|---|---|
| 의학교육의 고약한 문제: 학습자 평가에서 형평 달성하기(Acad Med, 2020) (0) | 2022.04.06 |
| 수행능력저하를 믿지 않는 것에서 실패를 인식하기까지: 티핑 포인트 모델(Med Educ, 2021) (0) | 2022.03.30 |
| WBA 시스템을 위한 타당도 지도 만들기: Messick과 Kane의 상호교차 (Acad Med, 2021) (0) | 2021.12.10 |
| 의학교육의 프로그램적 평가가 헬스케어에서 배울 수 있는 것(Perspect Med Educ, 2017) (0) | 2021.12.10 |