친절한 학습환경과 고약한 학습환경의 두 가지 세팅(Current Directions in Psychological Science, 2015)
The Two Settings of Kind and Wicked Learning Environments
Robin M. Hogarth1, Tomás Lejarraga2, and Emre Soyer3

의학 작가 루이스 토마스는 장티푸스를 초기에 정확하게 진단한 것으로 명성을 얻은 뉴욕의 한 병원 의사의 이야기를 20세기 초로 거슬러 올라간다. 의사는 혀의 생김새가 매우 진단적이라고 믿었다. 따라서 그의 임상 기술은 비관적인 예측을 하기 전에 환자의 혀를 촉진하는 것을 포함했다. 불행하게도, 그는 변함없이 옳았다. 하지만, 토마스가 말했듯이, "그는 티푸스 메리보다 손만 사용하여 더 효과적인 보균자였다." (토마스, 1983, 페이지 22)
Medical author Lewis Thomas recounted a story, dating from the early 20th century, of a physician in a New York hospital who acquired a reputation for accurately diagnosing typhoid fever in its early stages. The physician believed that the appearance of the tongue was highly diagnostic. Hence, his clinical technique included palpating patients’ tongues before making his pessimistic forecasts. Unfortunately, he was invariably correct. But, as Thomas stated, “He was a more effective carrier, using only his hands, than Typhoid Mary” (Thomas, 1983, p. 22).
Hogarth(2001)는 [고약한 학습 환경]의 개념을 도입하는 데 이 예를 사용했다. 그는 이러한 상황을 [행동이나 관찰의 결과 형태의 피드백이 빈약poor하거나, 오해의 소지가 있거나, 심지어 누락되는 상황]이라고 설명했다. 이와는 대조적으로 [친절한 학습 환경]에서 [피드백은 결과를 적절한 행동이나 판단과 직접 연결하며 정확하고 풍부]합니다. 사람들의 직관이 언제 정확할지를 결정할 때, 이 프레임워크는 학습이 이루어진 조건의 중요성을 강조한다. [친절한 학습 환경]은 정확한 직관적 판단을 위한 필수 조건이지만, [고약한 학습 환경]에서 획득한 직관은 잘못될 수 있습니다.
Hogarth (2001) used this example in introducing the concept of wicked learning environments. He described these as situations in which feedback in the form of outcomes of actions or observations is poor, misleading, or even missing. In contrast, in kind learning environments, feedback links outcomes directly to the appropriate actions or judgments and is both accurate and plentiful. In determining when people’s intuitions are likely to be accurate, this framework emphasizes the importance of the conditions under which learning has taken place. Kind learning environments are a necessary condition for accurate intuitive judgments, whereas intuitions acquired in wicked environments are likely to be mistaken.
이 기사의 목표는 이 차이를 자세히 설명하고 학습 환경의 유형을 보다 완벽하게 분류하는 것입니다. 그렇게 함으로써, 우리는 인간을 주로 이용 가능한 정보를 반영하는 순진한 직관적인 통계학자로 모델화할 수 있다는 견해를 채택한다(Fiedler & Juslin, 2006). (또한 Kaneman의 "당신이 보는 것이 거기 있는 전부이다" 은유도 참조). 따라서, 학습 환경의 특성에 대한 세심한 관심은 교정 절차를 제안할 뿐만 아니라 판단 편견의 원천을 식별하는 데 중요하다.
Our goal in this article is to elaborate on this distinction and to provide a more complete classification of types of learning environments. In doing so, we adopt the view that humans can be modeled as naive intuitive statisticians (Fiedler & Juslin, 2006) whose judgments mainly reflect the information available to them (see also the “what you see is all there is” metaphor of Kahneman, 2011). Thus, careful attention to the characteristics of learning environments is important for identifying sources of judgmental biases as well as suggesting corrective procedures.
2개의 설정 프레임워크
The Two-Settings Framework
확률론적 예측의 렌즈를 통해 추론을 개념화한다. 표본을 관측하고 통계량을 계산한 다음 모집단 또는 다른 표본에서 해당 통계량을 추정합니다(예: 평균을 추정하는 경우). 이론적 정당성은 단순한 가정에 의존합니다. 즉, 표본은 동일한 기본 모집단에서 무작위로 추출됩니다.
We conceptualize inference through the lens of probabilistic prediction. One observes a sample, calculates a statistic, and then estimates that statistic in the population or a different sample (as when, e.g., one estimates a mean). The theoretical justification relies on a simple assumption: Samples are randomly drawn from the same underlying population.
이 공식은 판단 및 의사결정 연구에서 매우 중요했습니다. 규범적인 벤치마크를 제공하고(Tversky & Kaneman, 1974), 기술 모델을 제안한다(Gigerenzer, 1991). 그러나 우리는 의사결정의 기초가 되는 심리적 문제를 고려하기에는 적합하지 않다고 주장한다. 왜냐하면 사람들은 하나의 기초가 되는 모집단 대신에 두 개의 모집단, 즉 우리가 말하는 것처럼 두 개의 상황settings을 다루어야 하기 때문이다.
This formulation has been critical in judgment and decision-making research. It provides normative benchmarks (Tversky & Kahneman, 1974) and suggests descriptive models (Gigerenzer, 1991). However, we contend that it is ill-suited for considering the psychological issues underlying decision making because, instead of one underlying population, people have to deal with two populations, or as we shall say, two settings.
첫 번째 설정에서는 상황(예: 두 변수가 어떻게 공변covary하는지)에 대해 학습한다. 두 번째는 첫 번째에서 습득한 지식을 사용하여 행동을 취하거나 예측을 합니다. 하나는 [학습]으로, 다른 하나는 [선택 또는 예측]으로 특징지어집니다. 예를 들어, 당신이 테스트를 사용하여 입사 지원자를 선택하는 인사 관리자라고 가정해 보십시오. 이 시험은 과거에도 정확했다. 따라서 현재 결정(예측)의 경우 두 설정(과거 및 현재)의 특징이 일치할 때 검정이 정확할 것으로 기대할 수 있습니다. 예를 들어, 현재 후보들은 과거와 비슷한가요? 우리는 이 과정에서 관리자가 (암시적 또는 명시적으로) 관련 인스턴스의 참조 클래스reference class , 즉 추론이 참조하는 특정 그룹을 염두에 두어야 한다고 강조한다. 참조 클래스가 다르면 추론이 다를 수 있습니다.
In the first setting, people learn about a situation (e.g., how two variables covary). In the second, they take an action or make a prediction using the knowledge acquired in the first. One setting is characterized by learning and the other by choice or prediction. To illustrate, imagine you are a personnel manager who uses a test to select job candidates. This test has been accurate in the past (learning). Thus, for current decisions (predictions), the test can be expected to be accurate when the features of the two settings (past and present) match. For example, are the present candidates similar to those in the past? We emphasize that in this process, the manager must also have in mind (implicitly or explicitly) a reference class of relevant instances—that is, the specific group to which the inference refers. Different reference classes can imply different inferences.
두 상황(예: 과거와 현재)이 동일한 기본 모집단에서 무작위로 추출된 샘플이라고 가정하기보다는 두 가지 다른 설정을 가정한다. 첫 번째를 L(학습용)이라고 하고 두 번째를 T(타깃용)라고 하고 이 두 가지가 어떻게 일치하는지 묻습니다. 그림 1의 왼쪽에서는 L과 T의 정보 요소가 일치하거나 일치하지 않는 6가지 방법을 고려하며, 이를 통해 [친절한 학습 환경]과 [고약한 학습 환경]에 대해 서로 다른 태스크 구조를 정의할 수 있습니다. 친절함이나 사악함 정도는 분명 다를 수 있습니다. 다만, 여기서의 의도는 분류에 한정되어 있습니다.
Rather than assuming that both situations (e.g., past and present) are random samples from the same underlying population, we posit two distinct settings. We refer to the first as L (for learning) and the second as T (for target) and ask how these match. On the left-hand side of Figure 1, we consider six ways in which the elements of information in L and T do or do not match, and these, in turn, allow us to define different task structures for kind and wicked learning environments. Clearly, kindness or wickedness can vary in degree. However, our intention here is limited to classification.
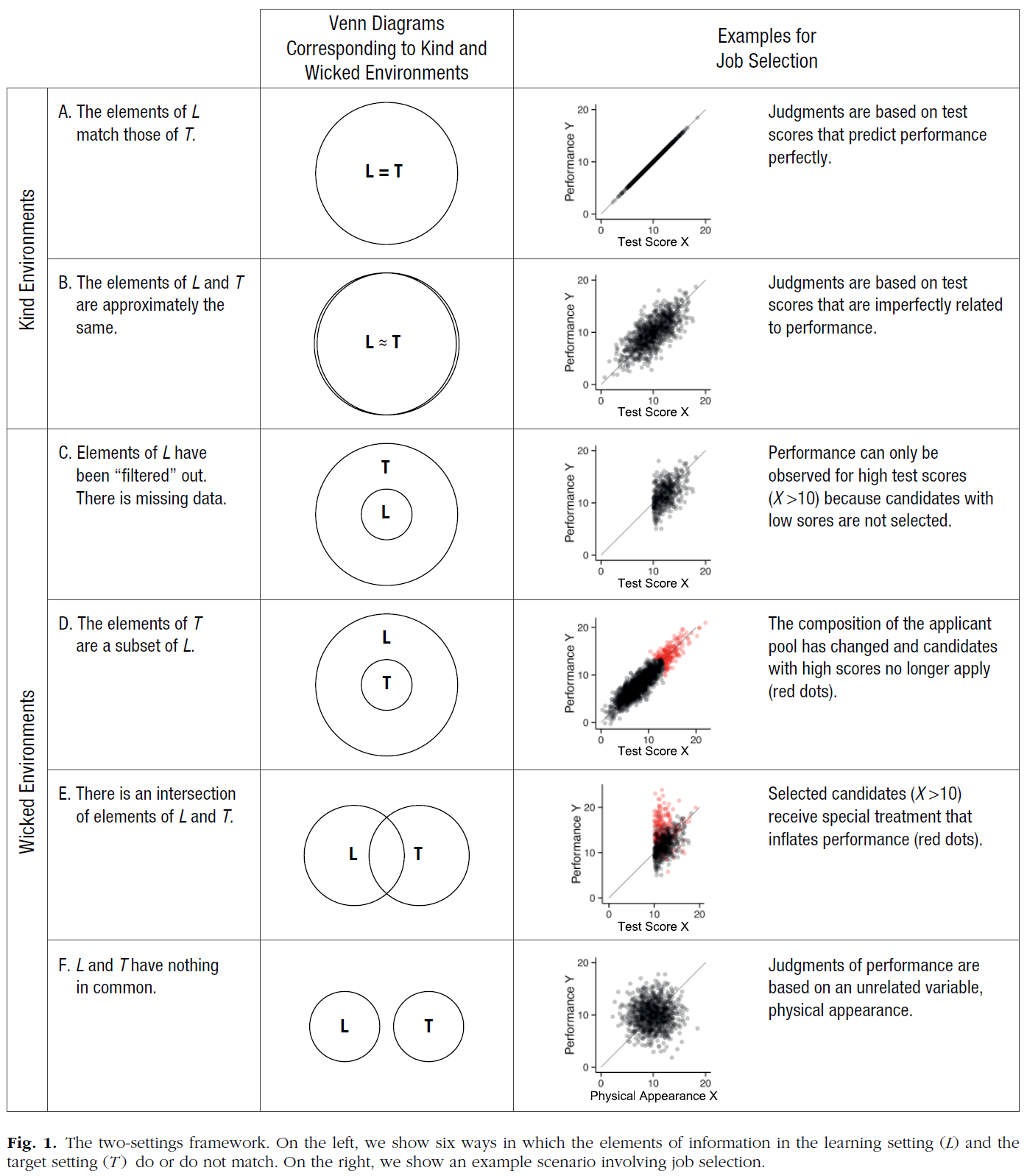
그림 1의 오른쪽은 작업 선택 시나리오를 사용하여 왼쪽의 사례를 보여 줍니다. 각 산점도에는 관리자가 과거 지원자의 시험 점수와 직무 성과 간의 관계에 대해 학습할 때 경험한 데이터가 표시됩니다(L). 그 후, 이 정보를 이용해 새로운 후보의 성과를 예측한다(T).
The right-hand side of Figure 1 illustrates the cases on the left using the job-selection scenario. Each scatter plot shows the data experienced by the manager in learning about the relation between test scores and job performance from past applicants (L). Subsequently, this information is used to predict the performance of new candidates (T).
[사례 A와 B는 친절한 학습 환경]을 나타냅니다. A에서는 L과 T의 요소가 완벽하게 일치합니다. 오른쪽 예제에서 X와 Y의 상관 관계는 1.0입니다. 검정에서 성능을 완벽하게 예측할 수 있습니다.
Cases A and B represent kind learning environments. In A, there is a perfect match between the elements of L and T. In the example on the right, the correlation between X and Y is 1.0. Performance can be predicted perfectly from the test.
[사례 B]에서 랜덤오차의 존재는 매칭이 기껏해야 근사치임을 것을 의미합니다. 오른쪽의 X와 Y의 관계는 직선이 아닌 타원으로 표시됩니다. 기술적으로 이러한 불일치는 L과 T 사이의 교차점을 의미한다(아래 설명되는 E와 동일).
그러나 B는 E와 다르다. 전자의 경우 불일치는 전적으로 무작위 요인에 기인한다.)
Case B reflects that the presence of random error means that matches are at best approximate. The relation between X and Y on the right is represented by an ellipse as opposed to a straight line. Technically, such mismatches imply an intersection between L and T (as does E, explained below; however, B differs from E in that in the former, the mismatch is entirely due to random factors).
[사례 C ~ F는 고약한 학습 환경]을 나타냅니다. C에서 L은 T의 서브셋이다. T에는 L에서 추론할 수 없는 요소가 있다. 예로는 사건이나 작용에 의해 데이터가 체계적으로 제한되는 생존자 편향이 있다(Einhorn & Hogarth, 1978). 오른쪽 예에서는 테스트에서 낮은 점수를 받은 사람(X < 10)은 작업에 선택되지 않았기 때문에 성능 데이터를 사용할 수 없습니다.
Cases C through F represent wicked learning environments. In C, L is a subset of T. There are elements in T that cannot be inferred from L. Examples include the survivorship bias, in which data have been systematically restricted by events or actions (Einhorn & Hogarth, 1978). In the example on the right, performance data are not available for people scoring low on the test (X < 10) because they were not selected for the job.
D에서 T는 L의 서브셋이다. 이는 학습과 예측 사이의 참조 클라스reference class 구성에 변화가 있다는 사실을 모르는 경우에 발생할 수 있다. 예를 들어, 지역 대학이 입학 기준을 낮췄기 때문에 지원자 풀이 바뀌었다고 가정해 봅시다. 그 때문에, 그 자리에 지원하는 졸업생 가운데, 높은 자격을 갖춘 지원자가 없습니다. 그러나 인사담당자는 이를 깨닫지 못하고 있다.
In D, T is a subset of L. This can occur when the person is unaware that there has been a change in the composition of the reference class between learning and prediction. For example, imagine that the applicant pool changes because the local university has lowered its admission standards, such that there are no highly qualified candidates among the graduates applying for the job. However, the personnel manager does not realize this.
E에서는 체계적인 요인 때문에 L과 T의 원소가 교차하고 T에서 예측 능력이 제한됩니다. 이 사례는 자기충족적 예언 또는 소위 치료 효과를 포착합니다. 선발 모델에서는, [선발된 사람(X > 10)]은, 조직적으로 업무 성과를 긍정적으로 평가하는 특별한 「대우」를 받는다(예를 들면, 훌륭한 멘토가 있다). 인사담당자는 편향된 학습표본에 노출되어 있다.
In E, the elements of L and T intersect because of systematic factors, and the ability to predict in T is limited. This case captures self-fulfilling prophecies or so-called treatment effects. In terms of the selection model, those chosen (X > 10) receive special “treatment” that systematically biases job performance positively (e.g., they have excellent mentors). The personnel manager is exposed to a biased learning sample.
사례 E는 또한 C와 D의 조건을 포착한다. 이 예에서 고용주는 시험 점수가 낮은 후보자에 대한 성과 측정치를 준수하지 않으며(X < 10), 학습 표본은 관리자가 알지 못하는 지원자 풀의 변화에 의해 편향된다.
Case E also captures the conditions of both C and D, where, in our example, an employer does not observe performance measures for candidates with low test scores (X < 10) and the learning sample is biased by the change in the applicant pool, of which the manager is unaware.
마지막으로 케이스 F에서는 T와 L은 공통 요소가 없습니다. 이 경우 성능 예측에 사용되는 변수는 이와 관련이 없습니다(예: 물리적 외관).
Finally, we note Case F, in which T and L have no elements in common. In this case, the variable used to predict performance is not related to it (e.g., physical appearance).
사악함의 특징
Features of Wickedness
나쁜 학습 환경은 환경의 특성일 뿐만 아니라 추론(자기충족적 예언, 사례 E 등)을 하는 사람이 취한 행동의 결과로 나타날 수 있다. 예를 들어, 과거에 관측된 데이터 범위를 초과하는 예측을 요청받은 경우 Case C 상황이 발생할 수 있다(Feiler, Tong, Larrick, 2012). 여기서 불일치는 개인의 행동에 의해 유발되지 않는다.
A wicked learning environment can emerge as a result of actions taken by the person making the inferences (as in self-fulfilling prophecies, Case E) as well as the characteristics of the environment. For example, a Case C situation could arise if someone were asked to make predictions beyond the range of data observed in the past (Feiler, Tong, & Larrick, 2012). Here, the mismatch is not triggered by the individual’s actions.
우리의 분류 체계에서는 별개이지만 친절과 사악함은 연속체처럼 정도가 다를 수 있다. 예를 들어, 케이스 A는 B보다 친절하고, 케이스 A는 E나 F보다 친절합니다. 하지만 미스매치가 무작위 요인에 의한 것이라면 어떻게 될까요? 예를 들어 B에서는 노이즈가 예측 능력을 감쇠시킵니다. 실제로 노이즈가 많으면 케이스 B의 예측능력은 케이스 C와 같은 일부 악질적인 환경보다 본질적으로 저하될 수 있습니다. 그러나 우리의 프레임워크는 불일치의 근본적인 원인이 전자의 경우 [무작위random]이지만 후자의 경우 [체계적systematic]이라는 것을 분명히 보여준다.
Although discrete in our classification scheme, kindness and wickedness can vary in degree as on a continuum. For instance, Case A is kinder than B, which is kinder than E or F. But what happens when mismatches are due to random factors? In B, for example, noise attenuates predictive ability. In fact, with much noise, predictive ability could be inherently lower in Case B than in some wicked environments, such as Case C. However, our framework clearly indicates that whereas the underlying cause of mismatch is random in the former, it is systematic in the latter.
우리는 특히 샘플이 작을 때 샘플의 크기와 다양성도 중요한 역할을 하도록 학습이 정보의 순차적 축적을 수반하는 것으로 예상한다. 그러나 종종 불일치mismatch에는 체계적 요인과 무작위적 요인이 모두 포함되며 더 큰 표본을 관측하는 것은 도움이 되지 않을 수 있습니다.
We envisage learning as involving the sequential accumulation of information, such that the size and variability of samples also play important roles—particularly when samples are small. Often, however, mismatches involve both systematic and random factors, and observing larger samples might not help.
우리의 프레임워크는 L과 T의 정보 요소만을 다루고 있습니다. 예를 들어 개인이 외부정보(예: 프라이밍)를 고려하는 이유나 추론을 할 때 정보가 어떻게 통합되는지는 설명하지 않는다. 이러한 문제는 많은 오류가 외부 정보(Kahneman, 2011) 및 부적절한 집계 규칙(예: 곱셈multiplicative 집계여야 할 때 덧셈additive 집계를 사용; Larrick & Soll, 2008)에 주의를 기울이는 데 기인할 수 있기 때문에 중요하다. 그러나, L과 T 사이의 정보 일치를 구별함으로써, 우리는 특이한 심리 과정 대신에 업무 특징에 기인하는 판단 오류의 근본적인 원인을 더 잘 분리할 수 있다.
Our framework deals only with the elements of information in L and T. It does not explain, for example, the reasons why individuals consider extraneous information (e.g., as in priming) or how information is aggregated in making inferences. These issues are important because many errors can be attributed to attention paid to extraneous information (Kahneman, 2011) and/or inappropriate aggregation rules (e.g., using additive aggregation when it should be multiplicative; Larrick & Soll, 2008). However, by distinguishing information matches between L and T, we can better isolate the underlying sources of judgmental errors that are due to task features as opposed to idiosyncratic psychological processes.
우리의 프레임워크는 문헌의 특정 레이블에 의해 식별된 일부 편견이 여러 원인을 가질 수 있다는 것을 보여준다. 예를 들어 환상 상관illusory correlation 을 생각해 봅시다. 한편, 이는 필터링된 관찰을 경험함으로써 유도될 수 있다. 즉, 이변량 분포의 일부가 관측치에서 가려지기 때문에 L에 대한 개인의 경험은 치우쳐 있습니다. 반면, 채프먼과 채프먼(1969)에 의해 조사된 현상은 인식된 상관관계에 대한 이전의 믿음의 역할에 관한 것이다. (Denrell & Le Mens, 2011도 참조).
Our framework reveals that some biases identified by specific labels in the literature can have multiple causes. Consider, for example, illusory correlation (Fiedler, 2000b). On the one hand, this can be induced by experiencing filtered observations. That is, the individual’s experience in L is biased because part of a bivariate distribution is obscured from observation. On the other hand, the phenomenon investigated by Chapman and Chapman (1969) is about the role of prior beliefs on perceived correlations. (See also Denrell & Le Mens, 2011.)
또, 우리의 견해는, 일반적으로 정보를 무시해, 단순한 의사결정 룰을 수반하는 휴리스틱 의사결정 프로세스의 예측의 정확성을 나타내고 있습니다(Gigerenzer & Gaissmaier, 2011). 성공적인 휴리스틱스는 환경의 두 가지 주요 기능인 정보의 집약 방법과 redundancy을 활용합니다(Hogarth & Karelaia, 2007). 이와 같이 L과 T의 교차로에서 동작한다. 예를 들어, 사람들이 두 가지 대안 중 하나를 선택하기 위해 인식 휴리스틱을 사용할 때(Goldstein & Gigerenzer, 2002),
그들은 그들이 예측하려고 하는 것과 관련이 있는 기억 속에서 이용 가능한 정보에 근거하여 판단한다.
Our perspective also speaks to the predictive accuracy of some heuristic decision processes that typically ignore information and involve simple decision rules (Gigerenzer & Gaissmaier, 2011). Successful heuristics exploit two key features of the environment: how information is aggregated and redundancy (Hogarth & Karelaia, 2007). As such, they operate in the intersection of L and T. For example, when people employ the recognition heuristic to select one of two alternatives (Goldstein & Gigerenzer, 2002), they base their judgments on information available in memory that happens to be correlated with what they are trying to predict.
디폴트로서의 매칭
Matching as a Default
사람들은 종종 L에서의 match를 T로 투영하는 것을 디폴트 전략으로 사용한다(Kahneman & Tversky, 1973). 여기에는 여러 가지 이유가 있을 수 있습니다. 첫째, 추론은 종종 정확한 답을 제공하는 것이 아니라 방향을 제시하기만 하면 된다(Hogarth, 1981).
People often use a default strategy that projects a match from L to T (Kahneman & Tversky, 1973). There could be several reasons for this. First, inferences often need only to suggest a direction as opposed to providing precise answers (Hogarth, 1981).
둘째, L에서 요소가 누락된 것을 알고 있다고 가정합니다. 어떻게 해야 할까요? 많은 것이 누락된 것으로 알려진 것에 달려 있다(Elwin, 2013). 그러나 규범적 관점에서, 누락된 관측치(사례 C)와 비대표적인 학습 세트(사례 D)에 대해 수정하는 방법은 불분명하다.
Second, assume that a person knows that elements are missing from L. What should be done? Much depends on what is known to be missing (Elwin, 2013). However, from a normative perspective, it is unclear how to correct for missing observations (Case C) and unrepresentative learning sets (Case D).
셋째, 디폴트 매칭 전략은 인지적으로 단순합니다. 디폴트를 조정하려면 메타인지 능력이 필요합니다(Fiedler & Kutzner, 프레스).1
Third, default matching strategies are cognitively simple. Adjusting defaults requires meta-cognitive ability that people may not possess (Fiedler & Kutzner, in press).1
다른 프레임워크와의 관계
Relationships to Other Frameworks
다른 학자들은 편견을 설명하기 위해 두 가지 설정 사이의 차이를 이용했다. Gilbert와 Wilson(2007)은 정서적 예측에 대한 연구에서 미래의 결과에 대한 사람들의 이미지와 실제로 일어나는 일을 비교했다. 예를 들어, 컨버터블을 살 때, 사람들은 아름다운 날씨에서 운전하는 즐거움을 상상할 수 있지만, 악천후와 관련된 다른 시나리오는 고려하지 못한다.
Other scholars have used differences between two settings to explain bias. In their work on affective forecasting, Gilbert and Wilson (2007) contrasted people’s images of future outcomes with what actually happens. For example, when buying a convertible, a person may imagine the joys of driving in beautiful weather but fail to consider other scenarios involving bad weather.
두 설정 간 일치의 중요성은 [학습 전이transfer]에 관한 문헌에서 받아들여지고 있다. 흥미롭게도, 손다이크(1903)의 영향력 있는 이론은 "동일한 요소"와 배움이 획득되고 적용되는 환경에서 이들 요소 간의 일치라는 관점에서 틀을 짰다. 하지만 그의 관심사는 사실이나 기술을 배우는 것이었다. (예: 테니스를 배우는 것이 다른 라켓 스포츠로 옮겨지는가?)
The importance of matches between two settings is acknowledged in the literature on transfer of learning (Barnett & Ceci, 2002). Interestingly, Thorndike’s (1903) influential theory was framed in terms of “identical elements” and the match between these elements in the settings where learning is acquired and applied. However, his concern was with learning facts or skills (e.g., does learning to play tennis transfer to other racquet sports?).
다른 사회과학자들은 데이터 세트를 이용할 때 두 설정 간의 일치에 대해 우려를 표합니다. 예를 들어, 통계학자와 기계학습 전문가는 표본에서 얻은 결과가 반드시 일반화되지는 않는다는 것을 알고, 표본 외 추론을 테스트하기 위한 기술을 개발했다.
Other social scientists show concern about the matches between two settings when exploiting data sets. For example, statisticians and machine-learning experts know that results obtained in samples do not necessarily generalize and have developed techniques for testing out-of-sample inferences.
역동적인 환경이나 비안정적 환경에 대해서는 명확하게 고려하지 않았습니다. 어느 레벨에서는, 그러한 환경은 악질적입니다(케이스 E 의 가능성이 있습니다). 그러나 첫 번째 세팅에서 역동적 변화의 특성을 추론할 수 있다면 [친절한 환경]이 될 수도 있습니다. 예를 들어 경험을 통해 계절의 사이클을 배우는 것을 고려해 보십시오.
We have not explicitly considered dynamic or nonstationary environments. At one level, such environments are wicked (a likely Case E). However, if the nature of the dynamic change can be inferred from the first setting, these environments can be kind. Consider, for example, learning seasonal cycles from experience.
시사점
Implications
우리의 프레임워크는 기술적이고 규범적인 의미를 가지고 있다. 특정 업무에서 추리적인 판단을 검토하는 맥락에서, 우선 이 맥락이 친절한 환경인지 고약한 환경인지에 관심을 갖는다.
- 만약 친절환 환경이라면, 우리는 정확한 추론을 위해 필요한 조건을 가지고 있다. 따라서 모든 오류는 개인에게 귀속되어야 한다(예: 부적절한 정보 집계).
- 만약 고약한 환경이라면, 작업 기능에서 오류가 발생하는 방식을 식별할 수 있습니다. 단, 작업 기능은 사람의 행동에 의해 영향을 받을 수도 있습니다. 즉, 우리의 프레임워크는 오류의 원인을 특정하는 데 도움이 됩니다(태스크 구조 또는 사람).
Our framework has descriptive and prescriptive implications. In the context of examining inferential judgments in a particular task, it first draws our attention to whether this is kind or wicked.
- If kind, we have the necessary conditions for accurate inference. Therefore, any errors must be attributed to the person (e.g., inappropriate information aggregation).
- If wicked, we can identify how error results from task features, although these can also be affected by human actions. In short, our framework facilitates pinpointing the sources of errors (task structure and/or person).
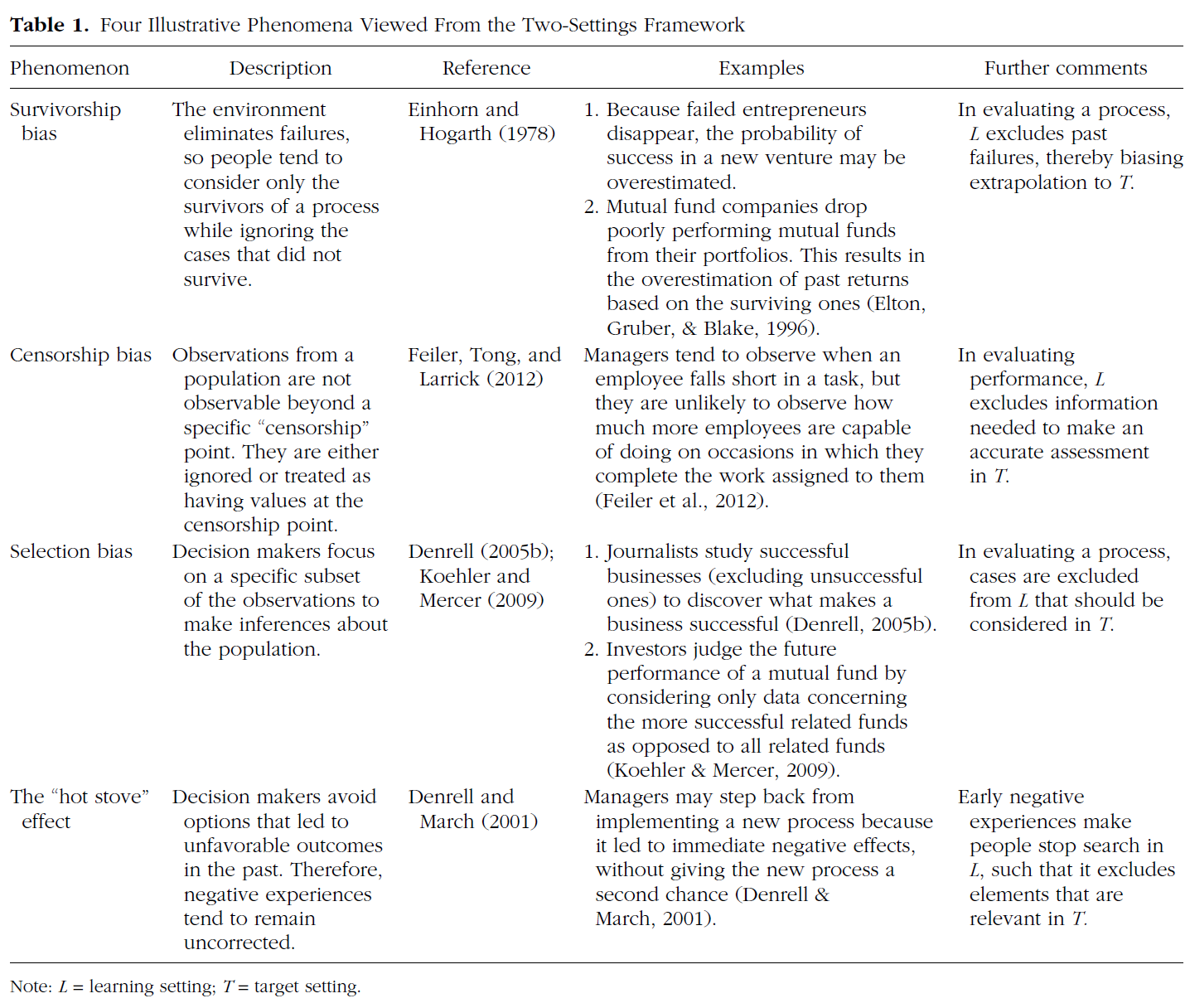
표 1은 이러한 관점에서 본 문헌의 몇 가지 현상을 나열한다. 예를 들어, 네 번째 항목인 "온풍로" 효과를 생각해 보십시오. 여기서, 과거의 결과(학습)에 대한 개인의 경험은 그녀가 현재 선택하는 것(목표)을 결정하지만, 그 결과는 이후의 학습을 편향시킨다.
Table 1 lists some phenomena in the literature viewed from this perspective. For example, consider the “hot stove” effect, the fourth entry. Here, a person’s experience of past outcomes (learning) determines what she selects currently (target), but then the outcome of this biases her subsequent learning.
판단의 편견을 바로잡기 위한 많은 시도가 있었다. 친절한 환경은 정확한 판단을 위한 필수 조건이기 때문에, 우리의 프레임워크는 의도적으로 친절한 환경을 만드는 것을 제안합니다. 실제로, 이 추론은 사람들이 확률론적 과정의 순차적 결과를 경험하게 함으로써 친절한 환경을 설계하고(Hogarth & Soyer, 2011) 적절한 확률론적 진술을 할 수 있는 능력을 조사했던 시뮬레이션 경험에 대한 우리의 작업에 동기를 부여했다. 일반적으로 잘못 대답하는 문제에 직면했을 때, 이러한 친절한 환경에서 참가자들의 판단은 매우 정확했습니다. 게다가, 참가자들은 그들의 반응에 자신감을 가지고 있었다.
There have been many attempts to correct judgmental biases (Soll, Milkman, & Payne, in press). Since kind environments are a necessary condition for accurate judgments, our framework suggests deliberately creating kind environments. Indeed, this reasoning motivated our work on simulated experience, in which we engineered kind environments by letting people experience sequential outcomes of probabilistic processes (Hogarth & Soyer, 2011) and investigated their ability to make appropriate probabilistic statements. Facing problems that are typically answered erroneously, participants’ judgments in these kind environments were quite accurate. Moreover, the participants were confident in their responses.
시뮬레이션 방법론을 제안하는 것은 우리뿐만이 아니다. 이러한 방법은 예를 들어 재정 결정 및 기후변화의 영향을 이해하는 데 유용한 것으로 입증되었다(Sterman, 2011). 우리의 프레임워크는 시뮬레이션 방법이 유용할 것 같은 시기를 지정하는 데 기여할 수 있다.
We are not alone in suggesting simulation methodology. These methods have proven useful, for example, in financial decisions (Goldstein, Johnson, & Sharpe, 2008; Kaufmann, Weber, & Haisley, 2013) and understanding the implications of climate change (Sterman, 2011). Our framework can contribute to specifying when simulation methods are likely to be useful.
환경을 친절하게 만드는 것의 이점을 강조하지만, 때로는 나쁜 환경을 악용하는 것이 이득이 될 수도 있습니다. 예를 들어, 플라시보를 제공함에 있어서, 목표는 [사람들이 경험으로부터 잘못된 교훈을 얻어야 한다]는 것이다. 우리의 프레임워크는 그러한 개입을 개념화하는데 사용될 수 있다.
Although we highlight the advantages of making environments kind, we note that it may sometimes also pay to exploit wicked environments. In providing placebos, for example, the goal is that people should draw the wrong lesson from experience. Our framework can be used to conceptualize such interventions.
최근, Erev와 Roth(2014)는 학습 행동의 관점에서 경제적 합리성으로부터의 편차를 조사했다. 그들은 학습환경이 에이전트를 "모든 에이전트에 대해 평균적이고 대부분의 시간 동안 최고의 성과"로 이끌 때 행동을 극대화할 가능성이 높다고 주장했다. Erev와 Roth는 종래의 최대화 모델을 사용하는 것을 가정하는 대신, 행동 최대화의 성공과 실패를 에이전트가 무엇을 어떻게 학습했는지에 기인하고, 따라서 암묵적으로 그들이 종류의 학습 환경에 노출되었는지 또는 사악한 학습 환경에 노출되었는지에 기인하기 때문에 그들의 기여는 중요하다.
Recently, Erev and Roth (2014) examined deviations from economic rationality from the perspective of learning behavior. They argued that maximizing behavior is likely when the learning environment leads agents to “the best payoff for all agents on average, and most of the time” (p. 10818). Their contribution is important because, instead of postulating the use of conventional maximization models, Erev and Roth attributed successes and failures in maximizing behavior to what and how agents have learned and thus, implicitly, to whether they have been exposed to kind or wicked learning environments.
이러한 생각들은 친절하고 사악한 학습 환경의 개념이 경제적 인센티브 계획의 설계에 유용할 수 있다는 것을 암시한다. 즉, 경제 주체들이 솔루션을 극대화할 수 있다고 가정하는 대신 적절한 대응, 즉 현물 환경에서 적절한 대응을 이끌어낼 수 있는 경험을 제공해야 한다. 이를 달성하는 방법은 아직 불확실하지만, 이러한 관점에서 문제를 제기하는 것은 큰 진전이다.
These ideas suggest that the concepts of kind and wicked learning environments can be useful in the design of economic incentive schemes. That is, instead of assuming that economic agents can calculate maximizing solutions, one should provide experiences that lead to appropriate responses—that is, in kind environments. Although the way to achieve this remains uncertain, posing the problem in these terms is a major step forward.
Abstract
Inference involves two settings: In the first, information is acquired (learning); in the second, it is applied (predictions or choices). Kind learning environments involve close matches between the informational elements in the two settings and are a necessary condition for accurate inferences. Wicked learning environments involve mismatches. This conceptual framework facilitates identifying sources of inferential errors and can be used, among other things, to suggest how to target corrective procedures. For example, structuring learning environments to be kind improves probabilistic judgments. Potentially, it could also enable economic agents to exhibit maximizing behavior.
'Articles (Medical Education) > 대학의학, 조직, 리더십' 카테고리의 다른 글
| 의학교육을 위한 평등한 학습환경 만들기: 사회적 정체성의 편향과 교차(Med Educ, 2021) (0) | 2022.03.28 |
|---|---|
| 의학교육의 사회적 권력과 위계에 대해 생각하기(Med Educ, 2021) (0) | 2022.03.28 |
| Carle Illinois College of Medicine (Acad Med, 2020) (0) | 2021.12.29 |
| 전략기획이 중요한가? (Acad Med, 2019) (0) | 2021.11.12 |
| 역량바탕평가가 지속적인 개혁이 되기 위해 고려할 점(Adv in Health Sci Educ, 2019) (0) | 2021.11.12 |